Az OpenBSD-vel foglalkozó előző írásaimban megismerkedhettünk az OpenBSD 3.5 telepítésének menetével, elvégeztük a rendszer alapvető beállítását, lefordítottuk a saját, az OpenBSD csapat által támogatott kernelünket, majd megpróbáltunk magas rendelkezésre-állású failover web szervert készíteni az OpenBSD 3.5-ben bemutatkozó CARP segítségével.
Az elkészült web szerverünk szépen tette is a dolgát egy ideig. Szerencsére sikerült olyan web tartalommal feltölteni, amelyre sokan voltak kíváncsiak.
Egyszer csak azt vettük észre, hogy a web szerverünk folyamatosan lassult, majd először csak délutánonként nem volt elérhető, a későbbiekben pedig rendszeresen kiszolgálási gondjaink akadtak. Főleg olyankor, amikor egy-egy sokat látogatott oldalon linkelték a mi web oldalunkat, és hirtelen nagy számú kérés érkezett felénk, amelyet a web szerverünk nem tudott kiszolgálni. Az interneten a fent leírt jelenséget Slashdot effektusnak nevezik. A Slashdot effektus, vagy egyéb nagy webes terhelés ellen egy ideig harcolhatunk úgy, hogy nagyobb teljesítményű processzort, több memóriát, gyorsabb merevlemezt építünk a gépünkbe, de egy idő után rá kell jönnünk, hogy az ilyen típusú terhelések ellen egy géppel nem vehetjük fel sikerrel a harcot.Szóval két dolgot tehetünk, az egyik, hogy felfele, vertikálisan skálázzuk a rendszerünket, a másik pedig az, hogy horizontálisan bővítjük azt. Lássuk, hogy melyik típusú skálázás mit jelent.
Fel skálázás (scale-up):
------------------------
Pár évvel ezelőtt még de facto szabvány eljárásnak volt tekinthető a felfele történő skálázás akkor, ha egy rendszer teljesítményét növelni kellett. A recept egyszerű volt, vegyél még nagyobb, még erősebb vasat, tömj bele egy marék processzort, egy zsák memóriát, SCSI merevlemezeket, gyors hálózati csatolót. Ha ez egy idő után kevés lesz, akkor tegyél bele ezekből kétszer annyit, vagy kétszer gyorsabbat. A piacra egyre gyorsabb és gyorsabb processzorok érkeztek - egy ideig szinte követve Moore híres törvényét - így biztosított volt, hogy egyre nagyobb teljesítmény zsúfolhassunk egy darab rendszerbe. Aztán a szabványnak tekinthető elgondolás megdőlt, több okból is kifolyólag: egy idő után képtelenség felfele skálázni, mert nem tudunk több és gyorsabb eszközt beleépíteni a gépbe. A gép egymaga nem képes redundáns működésre, így ha meghibásodik, akkor a rajta futó szolgáltatások elérhetetlenné váltak. Ezért megszületett az új elgondolás, az oldal irányba történő skálázás.
Ki skálázás (scale-out):
------------------------
Az oldal irányban skálázott rendszerek is sokkal nagyobb teljesítményt nyújtanak, mint egy szóló rendszer, de teljesen más megközelítésből. Clusterezéssel, vagy egyéb más eljárással feldaraboljuk a rendszerre irányuló terhelést, azokat elosztjuk több kisebb teljesítményű szerver között, így az egyes szerverek képesek megbirkózni a nagy terhelés rájuk háruló kisebb részeivel. Magyarul a munkát nem egy nagy vas (szaknyelven előforul big iron néven is) végzi, hanem több kisebb szerver, amelynek az összegzett teljesítménye azonban meghaladja az egy nagy szerver teljesítményét. Már most látszik, hogy ennek az elképzelésnek sok előnye van az előzőhöz képest. Az egyik a redundáns működés. Ha a rendszerünk egyik tagja kiesik mondjuk meghibásodás miatt, akkor a többi szerver függetlenül a leállt tagtól, tovább tud szolgáltatni. A jelenség annyi lesz, hogy a kiesett tag feladata a többi szerverre hárul, és azokon elosztva annyival nagyobb workload jelentkezik, amennyit a kiesett szerver végzett. A másik előnye ennek a megközelítésnek, az, hogy szinte a végtelenségig bővíthető, szemben a big iron megközelítéssel. Tegyük fel, hogy a 4 node-ból álló webszerverünk már nem képes kiszolgálni a kéréseket. Mit teszünk? Egyszerűen üzembe helyezünk egy újabb node-ot, és a probléma meg van oldva. Ha egy nem elég, akkor beüzemelünk még egyet, kettőt, vagy éppen ahányra szükségünk van.
Tehát a mai jelszó a oldal irányú skálázás! Már csak azért is mert a cikksorozat az OpenBSD köré épül, és ha akarnám se tudnám a rendszert felfele skálázni, annál az egyszerű oknál fogva, hogy az OpenBSD nem képes felfele növekedni. Hogy miért? Mert nem támogatja az SMP-t (több processzoros működést), és egy processzornál többet nem képes (jelenleg) kezelni.
Szóval scale-out. Nézzük mi jöhet szóba:
RR DNS:
-------
Az első ami eszembe jut, az a szegény ember load-balancer-je a Round Robin DNS (hívják LB DNS-nek is). A RR DNS lényege, hogy az egy web oldalra irányuló kéréseket több gépre osztjuk el úgy, hogy a hosthoz több bejegyzést készítünk a DNS szerverben. Tételezzük fel, hogy a hup.hu zónafile-jában az alábbi bejegyzéseket készítjük a (BIND) DNS szerverünkön:
www 60 in A 195.228.252.138
www 60 in A 195.228.252.139
Mostantól ha valaki lekéri a www.hup.hu IP címét a DNS szerverektől, akkor az esetek felében a 195.228.252.138-as címet, míg az esetek másik felében a 195.228.252.139-es címet fogja visszakapni.
# host www.hup.hu
www.hup.hu has address 195.228.252.138
www.hup.hu has address 195.228.252.139
majd utána:
# host www.hup.hu
www.hup.hu has address 195.228.252.139
www.hup.hu has address 195.228.252.138
Az alkalmazasok nagy része csak az elsőnek visszakapott számot használja fel, így a dolog szépen működik. Kb. az esetek felében a kérés az egyik szerverre, míg az esetek másik felében a masik szerverre érkezik. A DNS konfigban a TTL (Time To Live) értéket lehetőleg alacsonyan kell tartanunk, hogy az útban levő cache DNS szerverek ne tartsák sokáig gyorsítótárban az IP címeket és ne ``ragadjanak le'' az egyiknél. Így a terhelés szépen közelítőleg 50-50%-ban eloszlik a két gép között.
``Hurrá, megcsináltuk!" - kiálthatnánk fel, és itt véget is érne a cikk. Igen megcsináltuk, de ha ilyen egyszerű lenne, akkor nem lennének komoly berendezések, amelyek ezt a funkciót biztosítják. Ennek a megoldásnak vagy egy nagy hátránya. Ha az egyik szerver kiesik, akkor a DNS feloldások felében a kliens gépek egy olyan szerver IP címét adják vissza, amely már nem él. Ez komoly probléma lehet. A megoldás ilyenkor, az lehet, hogy 1.) módosítjuk a DNS konfigurációt, és megvárjuk míg az elterjed a többi DNS szerver között, 2.) ``gányolunk'', és ping, shell, és arp manipuláló segédprogramokat felhasználva a meghalt gép IP-címét átvesszük az élő gépre. Vagy kitalálunk valami mást...
Van egy másik (olcsó) megoldás is (drága van több is), mégpedig az, hogy munkába fogjuk az OpenBSD-t és a CARP-ot.
A múlt alkalommal felépítettünk egy failover CARP rendszert, amelynek egyik hibája az volt, hogy nem biztosított terhelés-elosztást. Ezt fogjuk most tovább fejlesztni.
Tehát a kiindulási alap ugyanaz, mint a múltkor. Ahhoz, hogy egy ARP elosztott virtuális hostot létre tudjunk hozni, mind a két fizikai hostra (Puffy és Rock) konfigurálni kell egy virtuális hostot, amely majd válaszolni fog az ARP kérésekre, és ez által kezelni fogja a webes forgalmat.
Először felállítjuk a carp csatoló-felületeket a Puffy névre hallgató gépen:
# ifconfig carp0 create
# ifconfig carp0 vhid 1 pass foobar 192.168.5.100
(eddig jutottunk a múltkot, és most folytatjuk)
# ifconfig carp1 create
# ifconfig carp1 vhid 2 advskew 100 pass foobar 192.168.5.100
Majd felállítjuk a carp csatoló-felületeket a Rock névre hallgató gépen is:
# ifconfig carp0 create
# ifconfig carp0 vhid 1 advskew 100 pass foobar 192.168.5.100
(itt eddig jutottunk a múltkor, és innen folytatjuk)
# ifconfig carp1 create
# ifconfig carp1 vhid 2 pass foobar 192.168.5.100
Ha ez kész, akkor az ARP balancing funkciót engedélyezni kell mindegyik hoston:
# sysctl net.inet.carp.arpbalance=1
(reboot után is maradandó beállítást a /etc/sysctl.conf fileban kell elkövetni)
Amikor a hostok ARP kérést kapnak a 192.168.5.100-as címre, a kérés IP címe alapján kiválasztódik az egyik virtuális host. A virtuális host azon tagja fog válaszolni a kérésre, amelyik a MASTER, a többi pedig ignorálja a kérést. Mivel mindig az a host lesz a MASTER a virtuális hostok közül, amelyik gyakoribb időközönként hirdeti magát, abban az esetben, ha az 1-es számú virtuális host (vhid 1) választódik ki, akkor a Puffy névre hallgató gép fog a kérésre válaszolni, mert a vhid 1-ben ő a MASTER. Ebből következik, hogy a 2-es számú virtuális host (vhid 2) kiválasztódása esetén a Rock névre hallgató gép fog válaszolni, hiszen a vhid 2-vel jelölt virtuális hostban a Rock a MASTER.
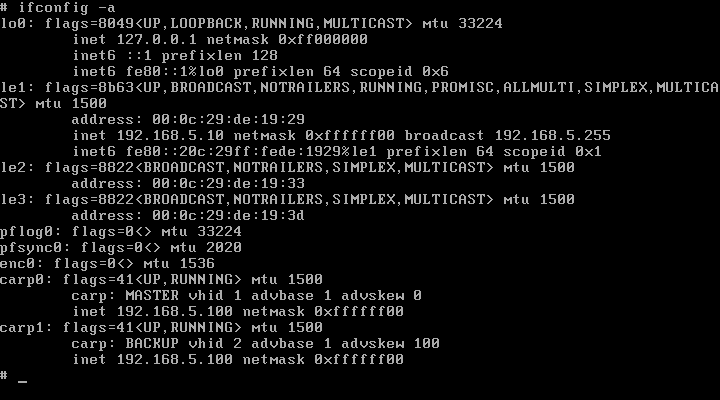
A konfiguráció az alábbiak szerint néz ki a Puffy-ról nézve:
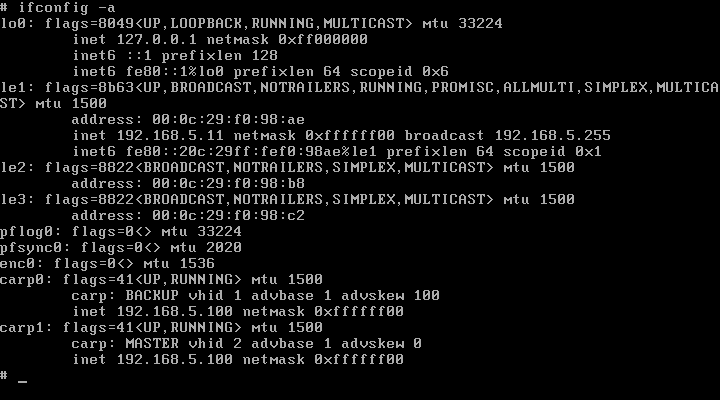
és a Rock-ról nézve:
A fenti konfigurációból az következik, hogy az ARP kérések eloszlanak (a kérés forrásának címe alapján) a virtuális (vhid 1 és vhid 2) hostok között, melynek az eredménye az lesz, hogy a webes forgalom is eloszlik a hostok között. Ha az egyik host meghal, akkor a másik magához ragadja a virtuális MAC address-t, és az fog a továbbiakban a kérésekre válaszolni.
A fenti konfigurációnak is van hátránya természetesen. Az egyik, hogy csak akkor működik az ARP balancing, ha a csoport tagjai egy fizikai subnet-en helyezkednek el. A CARP-ban implementált load balancing magában sajnos nem tökéletes. Mivel a CARP a kérést indító IP címének HASH-e alapján dönti el, hogy melyik virtuális host fogja a kérést lekezelni, sokat nem várhatunk tőle. Például abban az esetben, ha le szeretnénk tölteni egy file-t a szerverről, és azzal egy időben még böngészni is szeretnénk a web szerveren, akkor sajnos ugyanattól a szervertől fogjuk kapni az adatokat.
Bővebb információt a carp(4), sysctl(3), inet(4), ifconfig(8), sysctl(8) oldalakon kaphatsz.
Jó barkácsolást!