- A hozzászóláshoz be kell jelentkezni
- 5019 megtekintés
Hozzászólások
Van opensource eszkoz a load alapjan valo szervervalasztashoz? Vagyis, hogy ahhoz a szerverhez menjen a keres amelyiknek a legkisebb volt a load-ja az lekerdezes elott.
- A hozzászóláshoz be kell jelentkezni
Ennek megoldására nekem van egy ötletem, csak azt nem tudom, hogy mennyire lassítaná le ez a válasz idejét. De szerintem simán elhanyagolható lenne.
- A hozzászóláshoz be kell jelentkezni
Az otlet trivialias, kell egy kicsi php oldal, ami a /proc/loadavg tartalmat adja vissza. Igy megvan az alkalmazas szintu ping-is, es a load is visszajon. Ezt kell lekerni a DNS szerverrol mondjuk 5sec-enkent, es ez alakjan sulyozni egy veletlen valasztast a szerverek kozott(ha mindegyiknek azonos a loadja, akkor egyenlo valoszinuseggel kapjak a kovetkezo lekerest)
A kerdesem az volt, hogy _uzembiztos_, _tesztelt_, _kiprobalt_ megvalositas van-e opensource-ben?
- A hozzászóláshoz be kell jelentkezni
Ja advancedebb megoldasban kellene olyan, hogy bizonyos load felett 0 valoszinuseggel kapjon lekerest, meg hasonlok. Egy ilyen lenyeges program akkor jo, ha _evek_ tapasztalata gyulemlik fel benne. ;-)
- A hozzászóláshoz be kell jelentkezni
Az ipvs-ben (linux nat-csicsa modul) van olyan, hogy az aktiv kapcsolatok szamanak aranyat (sulyt) adhatsz meg webserverenkent. Igy ha vmely webserver belassul barmi okbol kifolyolag, akkor az aktiv kapcsolatok aranyanak tartasa eppen a masik webserverhez valo nat-ot eredmenyezi. Ez egyebkent inkabb terheleselosztasra jo, nem rendelkezesreallas-javitasra.
- A hozzászóláshoz be kell jelentkezni
Ehhez php? Normalis vagy? Ezt annyira kis dolgokkal meg lehet csinalni, hogy nem kell evtizedeket tesztelni. Csak igy belegondolva.
- A hozzászóláshoz be kell jelentkezni
Érdekes és ügyes megoldás.
A cikkel kapcsolatban: miért is jpeg a konzol screenshot?
Ejnye. Irgumburgum. És egyebek.
- A hozzászóláshoz be kell jelentkezni
mert jpeg rock
- A hozzászóláshoz be kell jelentkezni
Nem is
- A hozzászóláshoz be kell jelentkezni
>>>A DNS konfigban a TTL (Time To Live) értéket lehetőleg alacsonyan kell tartanunk, hogy az útban levő cache DNS szerverek ne tartsák sokáig gyorsítótárban az IP címeket és ne ``ragadjanak le'' az egyiknél. Így a terhelés szépen közelítőleg 50-50%-ban eloszlik a két gép között.
-----------------------
egy kis pontositas:
a DNS cachekben mindket A record benne lesz, tehat nem "ragadnak be". Minden egyes (kozbulso) DNS szepen round-robinolni fog.
A TTL-t csak akkor kell alacsonyan tartani, ha a rekordot a kozeljovoben valtoztatni akarod.
Nem kell feleslegesen terhetli a DNS-t.
hostmaster@fsn.hu-nak:
Ez peldaul felesleges:
portal.fsn.hu. 0 IN A 195.228.252.138
Honapok ota igy all.
udv
- A hozzászóláshoz be kell jelentkezni
>a DNS cachekben mindket A record benne lesz, tehat nem "ragadnak be". Minden egyes (kozbulso) DNS szepen round-robinolni fog.
Olvass el par RR DNS leirast. Ahanyat en olvastam, az osszes javasolja a TTL ertek alacsonyan tartasat.
1.) "We set the TTL low (to 60 seconds) to prevent any intervening caching DNS servers from hanging onto one sort order for too long"
2.) " The TTL value should be kept to a low value, so that the DNS cache is refreshed faster."
3.) "Reducing the TTL value on the individual records can mitigate the caching problem at the expense of DNS transactions."
sorolhatnam meg.
>hostmaster@fsn.hu-nak:
Ez peldaul felesleges:
portal.fsn.hu. 0 IN A 195.228.252.138
Honapok ota igy all.
Teves. 2 eve igy all. :-D (de ezt mar megbeszeltuk).
- A hozzászóláshoz be kell jelentkezni
>Olvass el par RR DNS leirast. Ahanyat en olvastam, az osszes javasolja a TTL ertek alacsonyan tartasat.
Akkor tevesek a leirasok.
Probald ki pl a www.google.com-ot.
A kozbulso DNS az a szolgaltatod nameserver-e lesz, es megsem ragad be csak az egyik IP-re. (es a TTL nem 0, hanem 300)
>Teves. 2 eve igy all. :-D (de ezt mar megbeszeltuk).
ahh:)
- A hozzászóláshoz be kell jelentkezni
>A kozbulso DNS az a szolgaltatod nameserver-e lesz, es megsem ragad be csak az egyik IP-re. (es a TTL nem 0, hanem 300)
Hol lattal te 0-as TTL-t? A cikkben az van irva, hogy tartsuk alacsonyan (60 van benne).
Azert ezt a linket atolvasnam a helyedben:
Round Robin low TTL @ Google [www.google.com]
(4870 oldal tevedne?)
"Understanding DNS and its load-balancing capabilities
By setting a low TTL, administrators can use DNS to help achieve load balancing. A low TTL forces clients and local servers to query the authoritative server frequently, giving the authoritative server the opportunity to reply with a different IP... "
:-D
- A hozzászóláshoz be kell jelentkezni
Trey,
A lenyeg: a chachekben nem ragad le. En csak erre reagaltam.
Az tokeletesen igaz, amit beideztel a google RR-rol:
Ha alacsonyan tartod a TTL-t, akkor az alkalmazasoknal sem ragad be.
- A hozzászóláshoz be kell jelentkezni
cache-ekben
- A hozzászóláshoz be kell jelentkezni
Szerintem felreerted. Nem beragad, hanem ne ragadjon le sokaig egy IP-nel. De szerintem lepjunk ezen tul, mert a cikk nem is errol szol, csak megemliti, mint egy lehetoseget a load balancing-ra.
- A hozzászóláshoz be kell jelentkezni
A cikk szuper, már csak _Joel és kisza kifogásaira várok... ;-P
- A hozzászóláshoz be kell jelentkezni
A két bal*****é? :D
- A hozzászóláshoz be kell jelentkezni
ejnye buglife >:-W
- A hozzászóláshoz be kell jelentkezni
A végéhez hozzáfűznék még egy gondolatot: webszervernél, de úgy általában, bármilyen Internetes szervernél a fenti megoldás teljességgel használhatatlan terheléselosztásra.
Hogy miért? Mert az Ethernet keretekben a forrás MAC cím mindig ugyanaz lesz (a router MAC címe), így a forgalom csak az egyik gép felé fog menni, a másik felé csak akkor, ha az elsővel valami gond van.
- A hozzászóláshoz be kell jelentkezni
Ez igy van. Intranetre viszont tokeletes.
- A hozzászóláshoz be kell jelentkezni
> A cikk szuper, már csak _Joel és kisza kifogásaira várok... ;-P
Hát Gabucino? :))
Egyébként tényleg jó cikk, csak rövid :))
Továbbléphettünk volna.
Row
- A hozzászóláshoz be kell jelentkezni
Ez akkor került beállításra, amikor a régi portálról az újra (mostani) váltottunk, aztán valahogy úgy maradt.
Javítom azonnal, köszönöm, hogy szóltál.
- A hozzászóláshoz be kell jelentkezni
Pedig jót mond :)
A DNS round robin működni fog akármilyen TTL-lel. Azt csak akkor szokták alacsonyra venni, ha változtatni kell az IP címeket.
- A hozzászóláshoz be kell jelentkezni
Pont errol irtam. Nem arrol volt szo, hogy magas TTL-lel nem fog mukodni a RR. Hanem arrol, hogy celszeru alacsony ertekel uzemeltetni.
Ha megall az egyik host, es valamilyen modon kiveszuk a halott host IP cimet, akkor gyorsabban vezetodnek at a valtozasok. Megsutheted ebben az esetben, ha magas ertekekkel nyomatod a TTL-t.
BTW mit jelent az RR DNS-nel, hogy csak akkor kell alacsonyra venni, ha valtoztatni akarom? Tudom elore, hogy mikor fog meghalni az egyik host? :-D
- A hozzászóláshoz be kell jelentkezni
És Internetes megoldásra mit ajánlasz...? ami kb. egy "súlycsoport" a fentivel...
- A hozzászóláshoz be kell jelentkezni
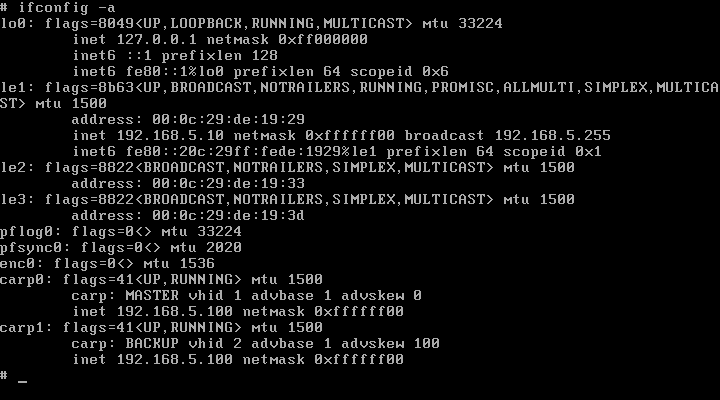
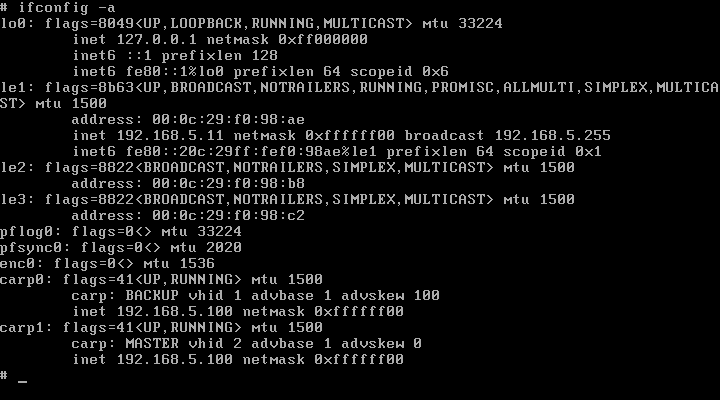
Mondjuk a ketto kombinacioja. RR DNS + 4 gep CARP-pal :-D
- A hozzászóláshoz be kell jelentkezni
A cikk jo! Az egesz sorozat tetszik. Orulok, hogy foglalkoztok a temaval!
Viszont en inkabb a CARP-ot routerre vagy tuzfalra hasznalnam. Ket olcsobb, kissebb teljesitmenyu gepet raknek be tuzfalnak CARP-al megoldva a magas rendelkezesreallast es pf-el forwardolnam a kereseket a kiszolgalok fele. Pfsync-el meg a ket fuzfal kozott a state tabla megosztast.
Szerintem ezzel a modszerrel lehet elerni a legjobb load balancingot. Nagyobb biztonsagot is ad es gyorsabban lehet skalazni a rendszert.
- A hozzászóláshoz be kell jelentkezni
Szerintem ez a megoldás a való világban nem nagyon állja meg a helyét.. ha az ARP kérést intéző forrás IP címe alapján dől el, milyen ARP választ adunk, akkor bukott az egész... interneten lévő szervernél ugyanis ARP kérés nagy valószínűséggel egy, és csakis egy IP felől fog érkezni, mégpedig a gatewaytől, aki ráadásul el is cacheli szépen a választ. De lehet, hogy valamit nem jól értelmezek a cikkben, ennyire az OpenBSD-sek se lehetnek hülyék, vagy lehet, hogy inkább ez a dolog nem is load balancera akar szolgálni, hanem csak fail overre. De akkor meg a cikknek nincs értelme.
- A hozzászóláshoz be kell jelentkezni
igen volt mar rola szo.
- A hozzászóláshoz be kell jelentkezni
Mico! ;) Ezt írta bra is, de egyébként ha az előtte lévő router/tűzfal arp cachet kikapcsolod, akkor már működik rendesen, nem? :) Persze lehet, hogy én gondolom rosszul. Cisco PIX-nél pl. egy bejegyzés: arp timeout 0
- A hozzászóláshoz be kell jelentkezni
Erre (is) találták ki amúgy a blade szervereket... Különösen ott jön jól, ahol az ISP rack unit-onként fizettetti a havi díjat, és így 1 RU-ra 3-4-5 CPU-t is be tudsz zsúfolni.
- A hozzászóláshoz be kell jelentkezni
Szerintem szakmailag korrekt:) de loadbalancing-ra én akkor is inkább valami dedikált célhardvert használnék... (márkát nem írok).
- A hozzászóláshoz be kell jelentkezni
Vásároltam már Tomcatnél, úgyhogy csak szóljatok neki mert tudja, hogy hova kell küldeni a pólót:)
- A hozzászóláshoz be kell jelentkezni
A tema irant melyebben erdeklodoknek figyelmebe ajanlom az ftp://ftp.hit.bme.hu/sys/anonftp/jereb/teljanal
konyvtarban levo pdf file-okat..:)
- A hozzászóláshoz be kell jelentkezni