Most, hogy sikeresen feltelepítettük az OpenBSD 3.5 operációs rendszerünket, beállítgattuk az alapvető dolgokat, és megtanultunk szupportált kernelt fordítani, azt a feladatot kaptuk, hogy olyan web szervert kell készítenünk, amely üzleti kritikus környezetben fog működni, és ha törik ha szakad annak üzemelnie kell.
Nem megengedett a downtime, és meg van adva, hogy éves szinten maximum 5 percet állhat a web szerverünk. Ez azt jelenti, hogy 99.999% (5 9-es) rendelkezésre-állású (High Availability - HA) web szervert kell készítenünk, amely az év 365 napján üzemel. Sok pénzünk nincs, a nagy vasak elfelejtve, de van a sarokban néhány jobb minőségű asztali PC, amelyet a nemrég elbocsátott kollégák hagytak itt. Ezekből kell a feladatot megoldani.
Nem kis feladat, és több helyen is buktatókkal van tűzdelve, de azért próbáljuk meg!
A magas rendelkezésre-állású rendszereknél a legnagyobb ellenfelünk a Single Point of Failure (SPF), amit magyarra talán úgy lehetne átültetni, hogy az ``egy pontból eredő megbízhatatlanság" vagy ``egy pontból eredő hibaforrás". Ha HA rendszert akaruk építeni, akkor rendszerünkből el kell tünteni a SPF-eket.
A SPF olyan meghibásodás, amely ha bekövetkezik, akkor a HA rendszerünk üzemszerű működése megszűnik. Képzeljünk el egy failover clustert, amely egy darab 220 voltos hosszabbítóba van bedugva. Hiába van 2 node-ból álló cluster-ünk, hiába figyeli az egyik node szorgalmasan a másik node által küldözgetett heartbeat-eket, ha jön a takarító néni, és szépen kitakarítja a konnektorból a betápot. Ebben az esetben a SPF a 220 voltos áramellátás. Vagy képzeljük el shared SCSI alapú failover cluster esetén, hogy meghibásodik a node-okat a diszk alrendszerrel összekötő kábel. Ez esetben a frontendek hiába működnek, ha a backend megadta magát. Itt az SPF a diszk alrendszert a node-okkal összekötő kábel lenne. Sok egyéb példát lehetne még hozni, de egy biztos: a jelszó a SPF-ek eltüntetése.Térjünk vissza az eredeti feladathoz. A feladat az, hogy egy web szervert kell építeni, amelynek kihagyás nélkül kell üzemelnie. Tételezzük fel, hogy egy nagy cégnél dolgozunk, ahol külön ember felel az áramellátásért és a hálózati infrastruktúráért, ezért azzal nem kell törődnünk. Tételezzük fel, hogy olyan szünetmentes áramforrásokat kapunk, amelyek külön körön vannak, mindegyiket generátor hajt, ha az áramszolgáltató leáll. Tételezzük fel, hogy a UTP fali aljzatban állandóan van ``delej'', azaz az ethernet hálózatunk 100%-os rendelkezésre-állással bír. Tekintsünk el attól, hogy bekövetkezhet egy földrengés, vagy robbanás, amely miatt a web szerverünk elérhetetlenné válik (nem interkontinentális clustert építünk egyelőre :-), stb.
Egy ilyen környezetben a mi feladatunk a következő:
- biztosítsuk, hogy a web szervert futtató vas állandóan, hiba nélkül működjön
- biztosítsuk, hogy a vason futó web szerver 365 napon keresztül kiszolgálja a kéréseket, de emellett az összes biztonsági (security) és az üzemszerű működést javító (reliability) fix felkerüljün a szerverünkre
``Ezt lehetetlen megcsinálni! Felmondok!'' - mondhatnánk egyszerűen. ``Hiába van 100%-os áramellátás, hiába 100%-os a hálózat, elromolhat a ethernet kártya, tönkremehet a CPU, elfüstölhet a RAM, stb. De ha szerencsém van, és ezek nem következnek be, akkor sem tudom a legfrissebb kernel patcheket feltenni anélkül, hogy újra ne kelljen indítanom a szervert. Két újraindítás egy évben, és már nem is tudom hozni az 5 9-es rendelkezésre-állást''.
Szerintem ne mondjunk fel, hanem kérjünk fizetésemelést, és csináljuk meg!
Arra gondolom mindenki rájött, hogy ahhoz hogy a fenti kívánalmakat teljesítsük nem lesz elegendő egy számítógép. Ahhoz, hogy állandó szolgáltatást tudjunk nyújtani, valamilyen failover cluster megoldást kell készítenünk. A failover cluster lényege, hogy minimum 2 node-ból álló rendszert építünk, amelyre teljesen azonos (jelen esetben HTTP szerver) szolgáltatásokat telepítünk. Van két szerverünk, amelyre feltelepítettük a céges web oldalakat. Külön-külön megszólítva szépen vissza is adják a kért web oldalt, és most már csak azt kell megoldanunk, hogy ha az egyik kiesik, akkor a helyét vegye át a másik.
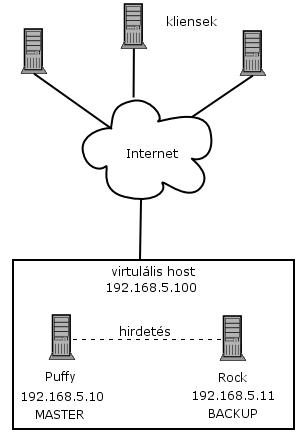
A két node-os failover cluster-ezés egyik megvalósítása úgy működik, hogy adott a két node, amelyeknek saját IP címe van. A cluster service nem csinál mást, mint a két IP cím elé egy virtuális IP címet tesz, és az adott kondícióktól függően kapcsolgat a két szerver között.
A szerverek a virtuális IP címen keresztül lesznek elérhetőek. Lesz egy elsődleges szerver, amelyet nevezzünk MASTER-nek. Alapértelmezés szerint a MASTER szerver fogja a céges web oldalt kiszolgálni. A másik node lesz a BACKUP. Ha minden jól megy, akkor a MASTER kiszolgálja az webes kéréseket, és a BACKUP szerver szépen csendben pihen. De tegyük fel, hogy a MASTER szerverben eldurran a merevlemez, és megáll az egész gép. Ilyenkor a cluster szerviz észreveszi a hibát, és a virtuális IP címet az eddig pihenő BACKUP szerverre ``irányítja''. Ez a másodperc töredéke alatt lezajlódik, jó esetben a felhasználó ebből a váltásból semmit nem észlel. Ezt a váltást nevezzük failover-nek.
Hogy honnan tudja a BACKUP szerver, hogy át kell vennie a feladatot a MASTER szervertől? Onnan, hogy a két gép összeköttetésben áll egymással. Az összeköttetésen (amely lehet dedikált ethernet hálózat a két gép között (gyk. crosslink kábel), vagy soros porti kommunikáció, stb.) keresztül a szerverek ún. ``heartbeat'' jeleket küldözgetnek egymásnak (ezek általában speciális broadcast UDP csomagok, de lehet más megoldás is). Amíg a BACKUP szerver folyamatosan érzékeli a MASTER szervert, addig semmit nem tesz, marad ``készenléti'' állapotban. Viszont, ha a ``heartbeat'' csomagok nem érkeznek meg egy bizonyos időn belül, akkor a BACKUP szerver megkezdi a failover folyamatot, és magához veszi az irányítást. Ettől a pillanattól kezdve a BACKUP szerver MASTER-ré válik, és ő fogja kiszolgálni a kéréseket. Ha közben a megállt szerverben kicseréljük a merevlemezt, újratelepítjük a szervert, majd bekapcsoljuk és az visszatér az élők sorába, akkor ez a szerver lesz a BACKUP szerver, és a folyamat kezdődik elölről. Az ritka, hogy a két szerver egyszerre menjen tönkre (van villámvédelem, redundáns áramellátás, kölün körön vannak, stb.). Így már egy nagy lépést tettünk a magas rendelkezésre-állás felé. Ebben a felépítésben az egyik szervert bármikor leállíthatjuk, hogy abban hardvert cseréljünk, vagy akár az egész operációs rendszert megfrissítsük, kernelt cseréljünk, stb. A webes ügyfelek ebből semmit nem vesznek észre.
``Mi van akkor, ha a másik szerver akkor hal meg, mikor az egyik node le van kapcsolva?''
Akkor baj van, de ez ellen lehet védekezni azzal, hogy nem kettő, hanem 3-4, stb. node-ból álló clustert építünk. Ennek csak a pénztárcánk szab határt.
``Jó, jó de egy ilyen rendszer kiépítése biztos sok pénzbe kerül.''
Ha a windowsos világban, vagy hardveres berendezésben gondolkodunk akkor amikor egy ilyen megoldás után nézünk, akkor bizony nem kevés pénzünkbe fog kerülni a biztonság. De mi gondolkodjuk inkább nyílt forrásban, és oldjuk meg abból!
Az OpenBSD 3.5 megjelenésével kapunk egy olyan eszközt, amellyel a fent leírt scenariot meg tudjuk oldani. Az eszköz nem más mint egy protokoll, amely a CARP névre hallgat. A CARP jelentése Common Address Redundancy Protocol, ami magyarra lefordítva valami ilyesmit tesz: közös címen alapuló redundancia protokoll. A CARP-ról bővebben olvashatsz a HupWiki CARP szócikkében, vagy az OpenBSD 3.5 carp(4) man oldalon.
Tehát a feladatot OpenBSD 3.5-ös gépekkel, és CARP-pal fogjuk megoldani.
Lássunk hozzá!
Kiindulási alap:
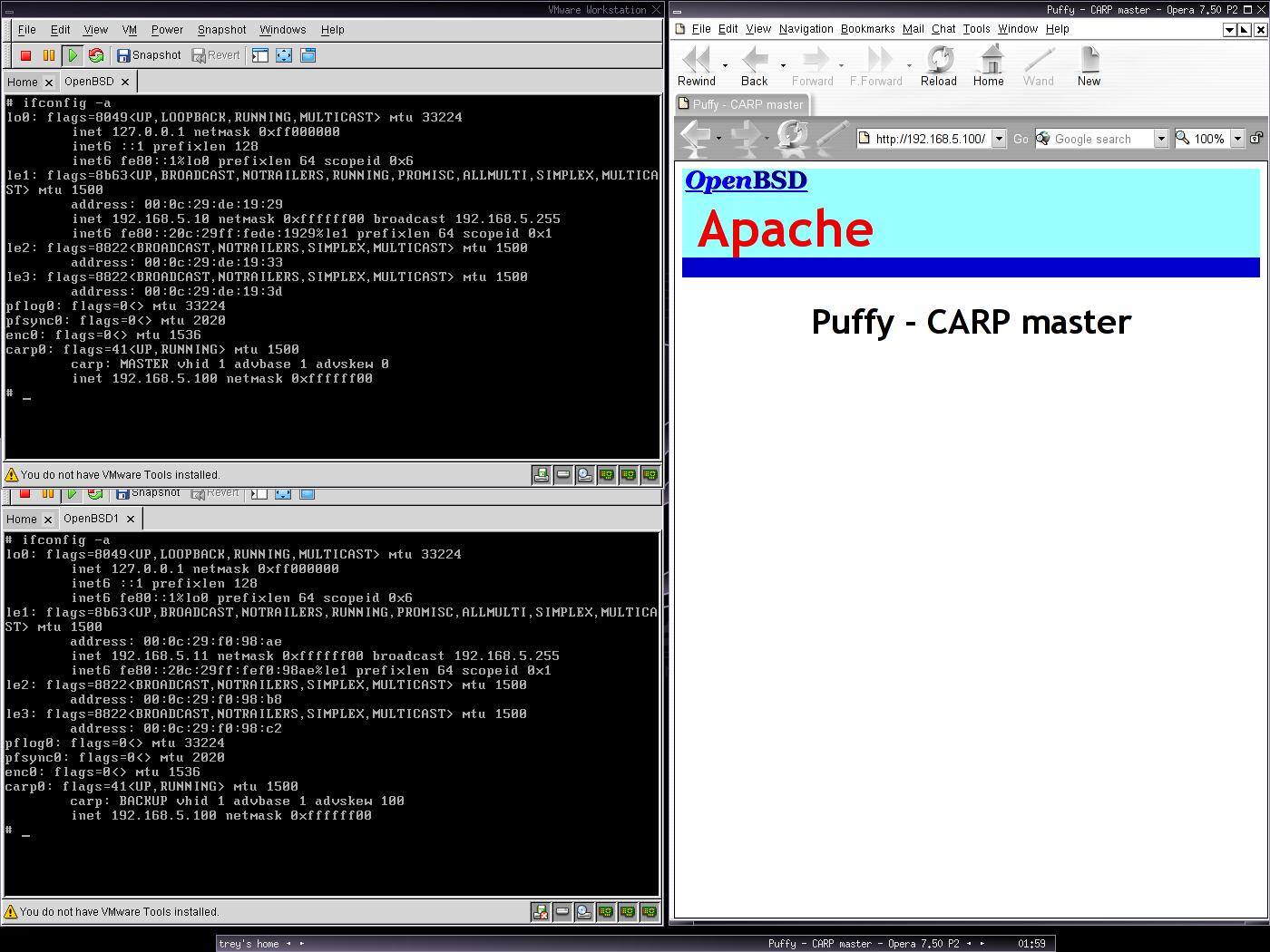
Adott két gépünk, amelyre feltelepítettünk az OpenBSD 3.5-öt, beállítottunk, és engedélyeztünk az induláskor, hogy az alaprendszer részeként kapott Apache web szerver elinduljon. Beállítottuk a gépeken a hálózatokat. A két gép jelenleg így fest:
Puffy:
------
IP cím: 192.168.5.10
Netmask: 255.255.255.0
Rock:
-----
IP cím: 192.168.5.11
Netmask: 255.255.255.0
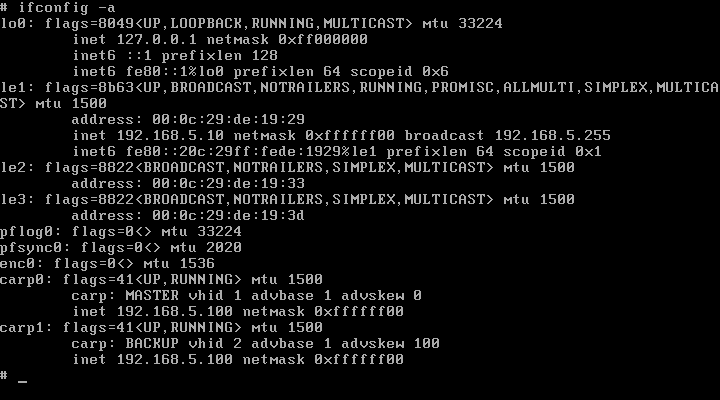
A két gépet megszólítva böngészőn keresztül ugyanazt a céges web oldalt kapjuk meg (ezt előzőleg feltelepítettük a gépekre). Azt szeretnénk, hogy a két gép a 192.168.5.100-as IP címen osztozzon (virtuális IP cím - erre lesz majd a DNS szerverben bejegyezve a web oldalunk), és a Puffy névre hallgató gép legyen a MASTER gép, ha mindkettő elérhető. A Rock lesz a készenlétben álló BACKUP, amely azonnal átveszi a Puffy szerepét, ha az nem elérhető.
Itt jön a képbe a CARP. A CARP-ot két dologgal lehet konfigurálni. Az egyik az ifconfig(8), a másik pedig a sysctl(3). A sysctl-lel az alábbi dolgokat lehet állítani:
net.inet.carp.allow = a host fogadja-e vagy sem a CARP csomagokat (alapértelmezés szerint be van kapcsolva)
net.inet.carp.arpbalance = load balance (terhelés elosztó) megoldáshoz használatos, jelenleg nem használjuk (alapértelmezés szerint ki van kapcsolva) (erről a másik cikkben lesz szó)
net.inet.carp.log = CARP hibákat logolja (alapértelmezés szerint ki van kapcsolva)
net.inet.carp.preempt = a természetes kiválasztódást engedélyezi a CARP hostok között (alapértelmezés szerint ki van kapcsolva)
A hostokat a következőképpen konfiguráljuk.
Puffy:
------
puffy# ifconfig carp0 create
Ezzel létrehoztuk a carp0 interfészt.
puffy# ifconfig carp0 vhid 1 pass foobar 192.168.5.100
Ezzel a paranccsal a carp0-ot a vhid 1 csoportba tettünk. A vhid a ``virtual host identifier'', amely azt jelöli, hogy mely CARP hostok tartoznak egy virtuális csoportba. A pass-sal megadtuk azt a jelszót, amellyel a CARP hostok igazolják magukat, és a végén megadtuk azt a virtuális IP címet, amelyen a virtuális web szerverünk elérhető lesz.
Ahhoz, hogy a reboot után ezek a beállítások meg is maradjanak, létre kell hozni a /etc/hostname.carp0 filet, amely a következőket kell, hogy tartalmazza:
puffy# cat /etc/hostname.carp0
inet 192.168.5.100 255.255.255.0 192.168.5.255 vhid 1 pass foobar
Értelemszerűen az adatok: IP cím, netmask, broadcast, virtual host ID, jelszó.
Most ugyanezt eljátszuk a másik hoston, a Rock-on is.
rock# ifconfig carp0 create
rock# ifconfig carp0 vhid 1 pass foobar 192.168.5.100
Elkészítjuk a /etc/hostname.carp0 filet ezen a hoston is.
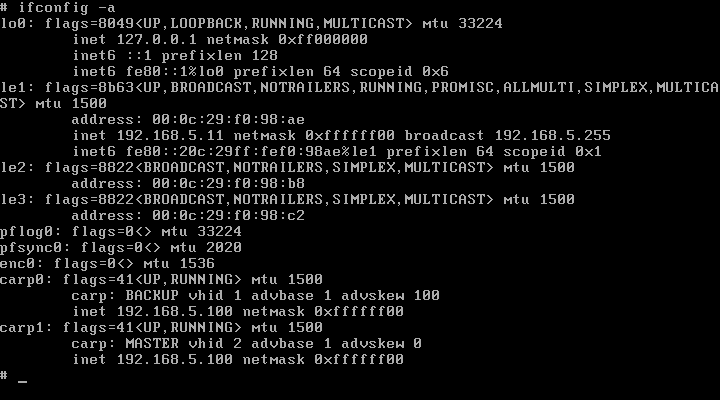
Az a rendszer lesz a MASTER, amelynek a carp0 interfésze előbb felhúzódik. Viszont mi van akkor, ha azt szeretnénk, hogy a Puffy legyen a MASTER mindig, ha az lehetséges, mert mondjuk annak erősebb a hardvere? Semmi gond, ez lehetséges, csak tudatni kell a CARP-pal.
Mindig az lesz a MASTER gép, amely sűrűbb időközönként hirdeti magát. Annyit kell elérnünk, hogy a Puffy gyakrabban hirdesse magát, mint a Rock, és akkor ha mindkét gép elérhető, akkor a Puffy lesz a MASTER. Természetesen ebben az esetben a Rock lesz a BACKUP. Ha a Puffy megszűnik hirdeti magát egy bizonyos perióduson belül (ez az idő a háromszorosa a BACKUP (Rock) hirdetési intervallumának), akkor a Rock megkezdi a failover procedúrát, átveszi az irányítást, és ő lesz a MASTER. Ez annyit tesz, hogy ezután ő fog válaszolni a 192.168.5.100 IP címhez tartozó ARP kérésekre.
Ha azt szeretnénk, hogy a Puffy sűrűbben hirdesse magát, mint a Rock (és ezzel ő legyen a MASTER), akkor a Rock-on le kell csökkenteni a hidetés frekvenciáját az alábbi paranccsal:
rock# ifconfig carp0 advskew 100
(ha maradandóan akarjuk a beállítást akkor így módosul a /etc/hostname.carp0 file:
inet 192.168.5.100 255.255.255.0 192.168.5.255 vhid 1 advskew 100 pass foobar)
Természetesen a következőt hozzá kell adni a /etc/sysctl.conf-hoz:
net.inet.carp.preempt=1
(kézzel: sysctl -w net.inet.carp.preempt=1)
A bővebb parancsokért nézd még meg a carp(4), ifconfig(8), sysctl(3) man oldalakat.
Ezzel a magas rendelkezésre-állású web szerverünk elkészült.

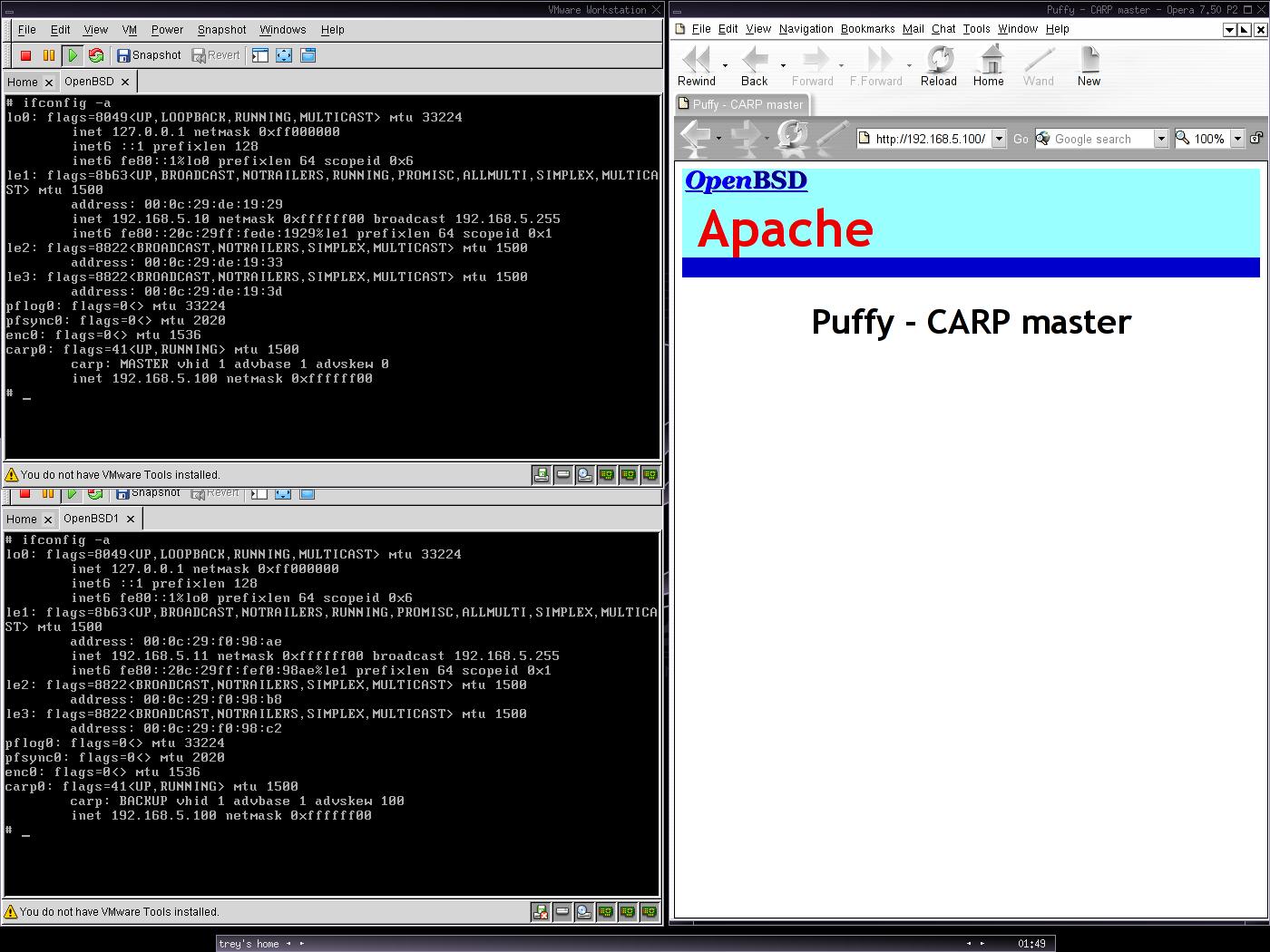
A képen az látható, hogy a Puffy a MASTER, és jelenleg ő szolgálja ki az oldalakat. A Rock jelenleg készenlétben áll.
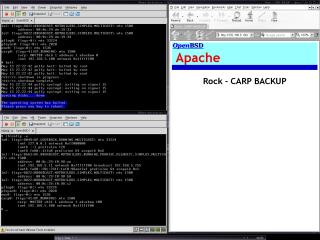
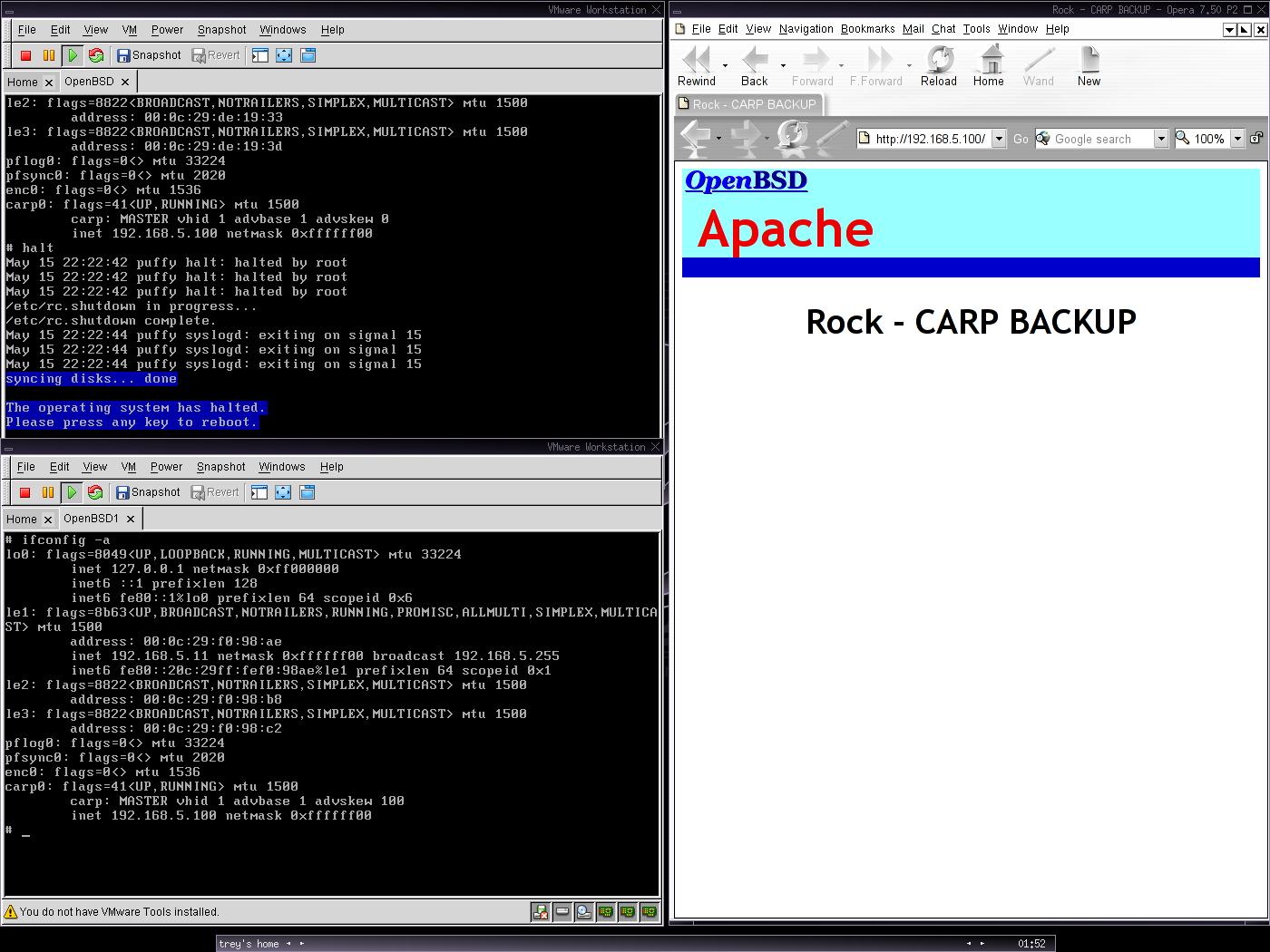
A képen az látható, hogy a Puffy megállt, és a Rock elvégezte a failovert. Jelenleg a Rock szolgálja ki az oldalakat.
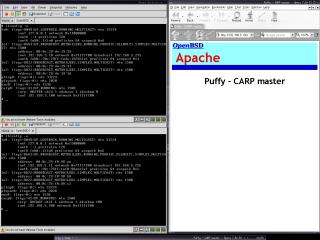
A képen az látható, hogy a Puffy visszatért az élők sorába (HDD csere), és ismét ő a MASTER, mert a hirdetési frekvenciája nagyobb, mint a Rock-é. Jelenleg a Puffy szolgálja ki az oldalakat.