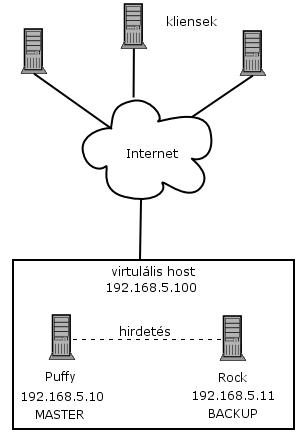
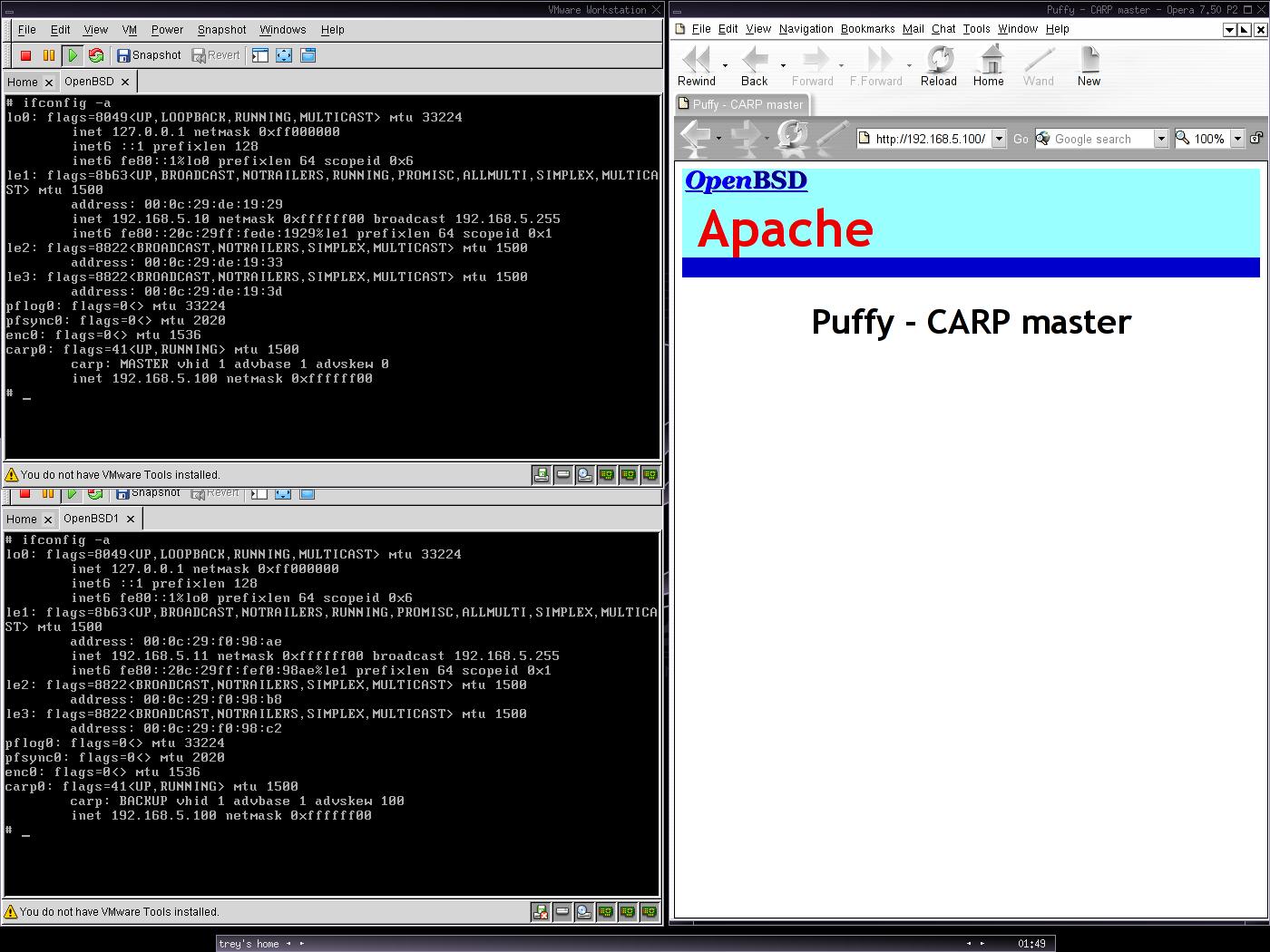
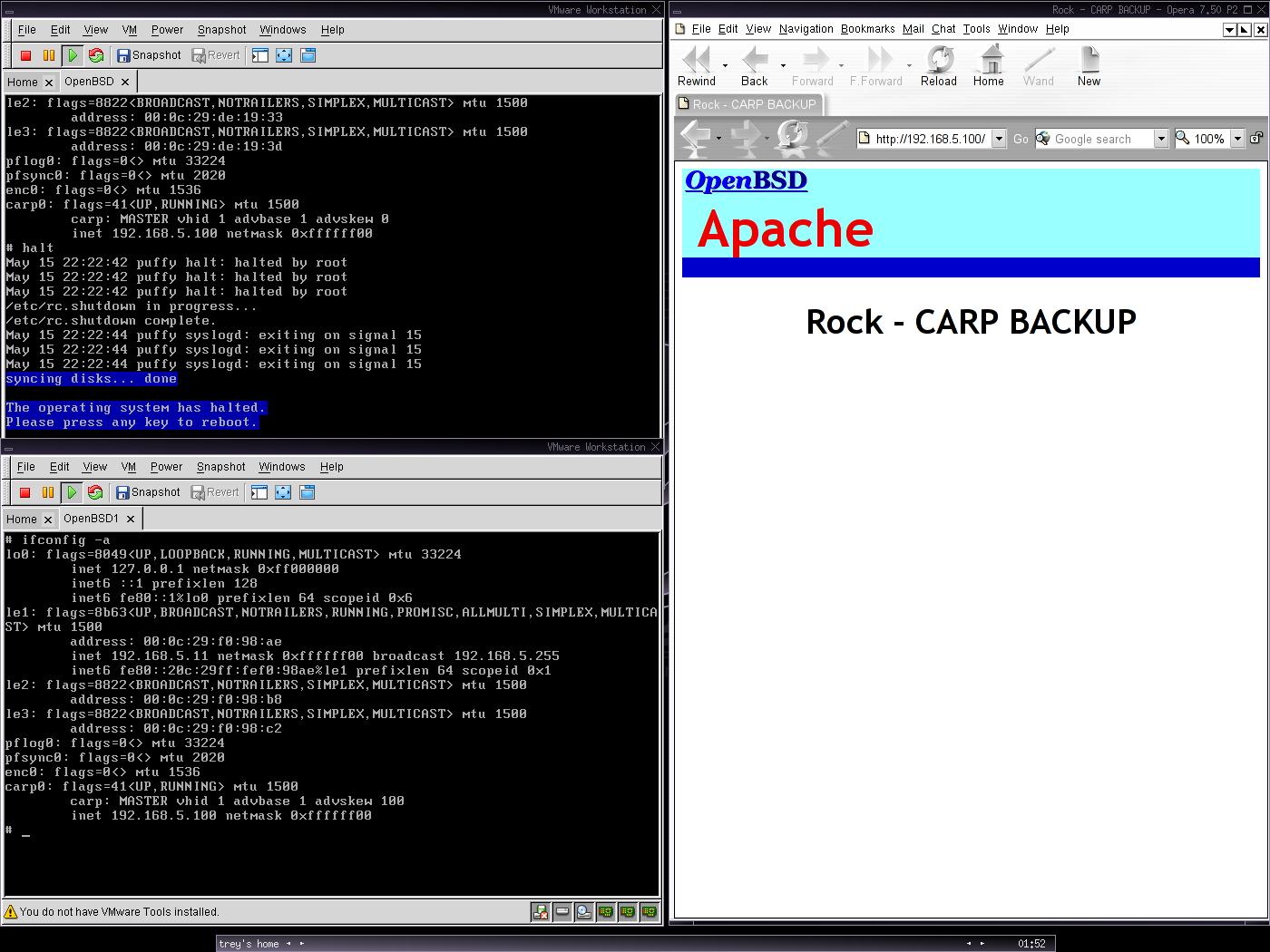
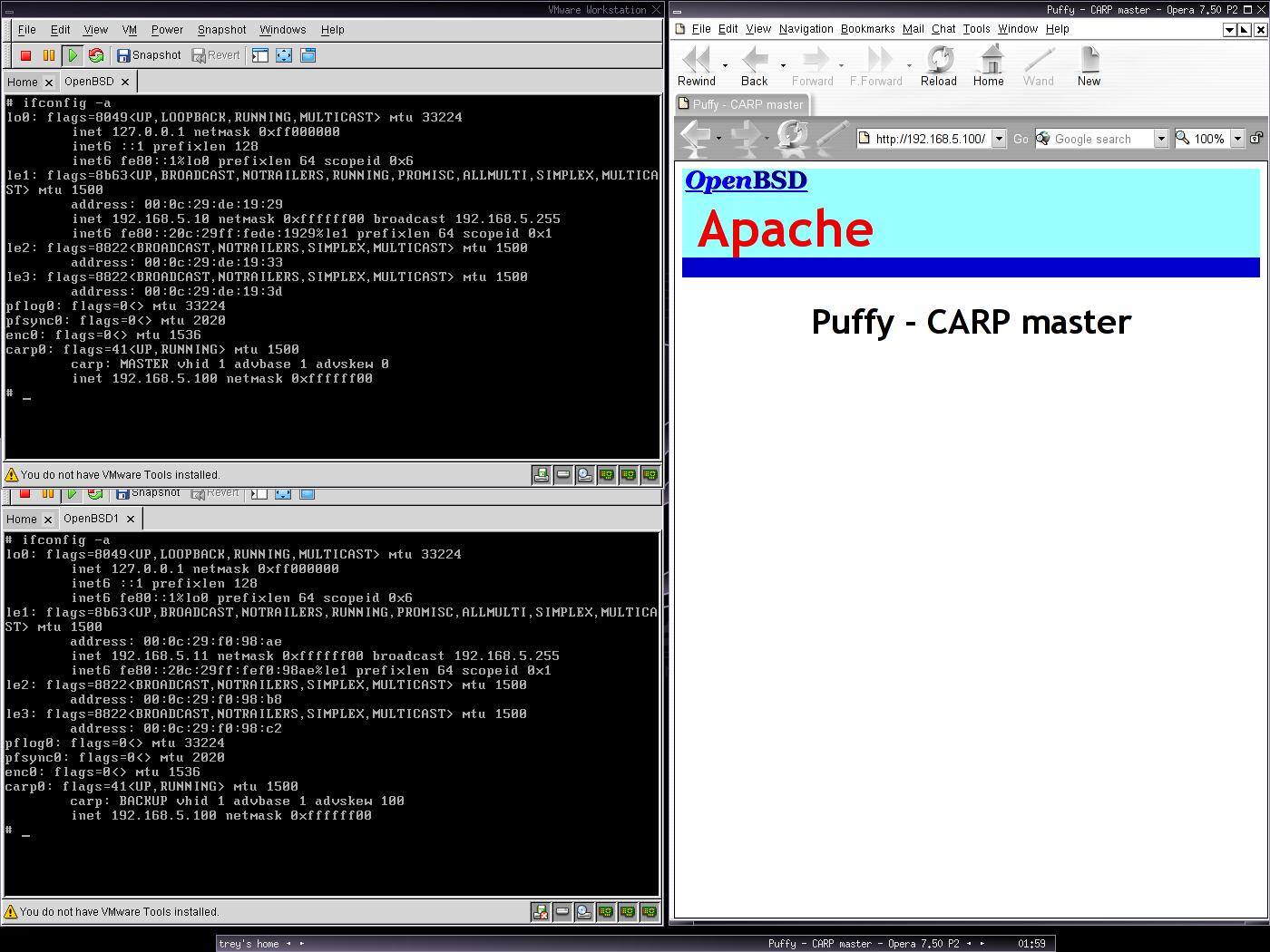
Következő cikkben a terhelés elosztásról (load balancing) lesz szó. Addig is sok szerencsét a kísérletezgetéshez!
- A hozzászóláshoz be kell jelentkezni
- 14528 megtekintés
Hozzászólások
>Nagyon jó kedvet csináltál (szerintem sokaknak) az openBSD-hez. A jó, hogy lelkes maradsz annak ellenére, hogy akik egyébként érdemben írni lusták, ilyenkor alázni meg fikázni hamar beesnek...
Nem hiszem, hogy van mit alazni, hiszen ez a tema (nem az OpenBSD-s CARP, hanem a clustering) mar regen meghaladja egy atlag informatikus tudasat. Amirol meg Kisza es Joel beszel, azzal halando mernok nem nagyon talakozik eloben, kiveve, ha akkora cegnel dolgozik, mint a Sun, IBM, HP, stb. Az ilyen rendszerekt mar csak azok epithetik es uzemeltethetik, akiknek egy valag papirjuk van rola, es ezekbol nem egyet csak kulfoldon lehet megszerezni. Tehat az atlag ember ilyen rendszereket az eleteben nem fog latni, maximum fenykepen. BTW annak idejen hogy valaki Datacenter Servert lasson Huostonba kellett menni, pedig az nem is olyan nagy szam. :-D
>Lesz szó a továbbiakban arról, hogy egy ilyen rendszeren hogyan szokás megoldani a dinamikus webtartalom (főleg, ha a kliensektől érkezik tárolandó adat) szükségszerűen gyors szinkronizálását a cluster-en?
Ugy tervezem, hogy a vegen egy komplett web szolgaltatas lesz, a hatterben clusterezett SQL szerverrel. Bar a backend valoszinuleg nem OpenBSD lesz, hanem Linux de ez ne keseritsen el senkit :-D
- A hozzászóláshoz be kell jelentkezni
>Es en meg olyan DNS LB-t nem lattam, amelyik nem pingelte az IP-ket mondjuk 5 masodpercenkent es valasz hianyaban nem vette ki az adott IP cimet a pool-bol - az ilyen LB-nek semmi ertelmeísem lenne.
Kerdes, hogy ez mennyi ido alatt vezetodik at a DNS-ben.
- A hozzászóláshoz be kell jelentkezni
> Nem hiszem, hogy van mit alazni...
Főleg abban tévednek, (annak ellenére, hogy ezzel kezdted...) hogy mi a cikk célja. Nagyon jó alapozó, összefoglaló, kedvcsináló. Akiben megvan az egészséges érdeklődés, lelkesedés és szakmai önbecsülés, az úgysem kizárólag erre alapozva fogja felépíteni a renszerét, hanem mélyen utána fog járni a kérdéskörnek. Akiben ezek nincsenek meg, azoknak meg tökmindegy: úgyis gányolnak, akkor már legalább itt olvastak valamit, ami hasznukra lesz.
Akkor kíváncsian várom a folytatást.
Row
- A hozzászóláshoz be kell jelentkezni
A rendelkezesreallas nem a multra vonatkozik (ket napja all az egyik gep, de mukodik a masik es ezert 100%) - a mult csak a penztarnal szamit. A rendelkezesre allas valoszinusegek atlagaval, varhato ertekevel foglalkozik (ezert mean time between failure es mean time to repair), meghozza a jovore vonatkozoan. Ez a rendszer 99,999%-os rendelkezesre allasu, ha garantalhato, hogy a kovetkezo x ido maximum 1 ezred szazalekaban lesz szolgaltatas kieses. Ha kiesik egy komponense, akkor mar nem tudom garantalni ugyanezt, hacsak meg nem javitom mielott ujabb hiba tortenne. Ezert gyakran ez nem kifejezetten informatikai, mint inkabb logisztikai problema.
- A hozzászóláshoz be kell jelentkezni
Egyebkent pedig igen. Nehez (illetve nehezebb) azt elolvasni, mivel sajnos nem rendelkezem anyanyelvi szintu angol nyelvismerettel, igy bizonyos dolokat csak sokszori atolvasas, extremebb esetben pedig csak tesztelgetesek utan ertek meg belolle.
Pedig enelkul nem fog menni. OpenBSD-hez szinte semmi magyar nyelvu anyag nincs, a legfontosabb forras pedig a levlista archivum es a faq. Ez van.
netchan
- A hozzászóláshoz be kell jelentkezni
"Kerdes, hogy ez mennyi ido alatt vezetodik at a DNS-ben."
Valoban:) De ez minden failover cluster-nel is ugyanigy fennall (maximum ott nehany masodperc a szolgaltatas elerhetetlensege, DNS-nel pedig amikor a cache-ekbol torlodik).
- A hozzászóláshoz be kell jelentkezni
A cikkel kapcsolatban tobben is megkerestek levelben (van olyan is aminek .gov.hu a vege :-), hogy erdeklodnek valami hasonlo *BSD rendszer kiepitesen. Lehet, hogy sok helyen van igeny ilyen rendszerre, csak penz nincs sok ezer dollaros vasakra.
- A hozzászóláshoz be kell jelentkezni
http://www.openbsd.org/faq/hu/index.html
Magyarul azert csak tudsz nem?
- A hozzászóláshoz be kell jelentkezni
Trey, milyen rendszerekre?:) Valamilyen HA megoldasra? Arra igen. Három kilences garantálására valószínűleg elég a CARP megoldás.
Ötkilencesre? Arra nem hiszem:)
- A hozzászóláshoz be kell jelentkezni
Kilencesekrol nem volt szo, de igerem, hogy ha 5 9-et akarnak, akkor elkuldom hozzad oket. Azert mondjuk erdekelne, hogy ti tudtok-e 5 9-es rendszert szallitani garantaltan, es ha igen, akkor kb. milyen konfiguraciot, es mennyiert :-D
- A hozzászóláshoz be kell jelentkezni
Ertem, koszi. [A fene sem tudta, hogy a rendelkezesreallast a jovore mondjak meg az okosok, es nem a multra szamoljak -> megint tanultam;-)]
udv,
jacek
- A hozzászóláshoz be kell jelentkezni
:))
Sokat segitett a magyarra leforditott tartalomjegyzek :)
Mindegy. Boldogulok az angollal is, mint kifejtettem, de egy hosszas reszletes szovegnel sokkkal hasznosabb tud lenni idonkent egy rovid, magyar info, ami a helyes iranyban elinditja az embert.
- A hozzászóláshoz be kell jelentkezni
Koszi a segitokeszseget.
Most meg a manok faq-ok es info-k atragasaval telnek a napjaim, is nem is akarlak foloslegesen terhelni. Szoval ha ugy erzed, hogy rtfm, akkor mond nyugodtan :)
- Csomagszuro, NAT, Router
Erre a celra a Linux+iptables+iproute2 vagy az OpenBSD+pf+? megoldast javasolnad? - Software RAID
Van-e? Es ha van akkor hogyan? - UPS
avagy mivel valtsam ki az apcupsd-t? - "Valodi halt"
Hogyan kapcsolom le teljesen az ATX-es gepet. (Pl ha mar nem birja az UPS tovabb.)
A halt utan ugyebar egy gombnyomasra var, es reboot-olni szeretne. - Mit tegyek, ha nem jo sorrendben talalja meg az IDE-vezerloimet.
(Az alaplapi mellet van egy + IDE-vezerlo kartya). Linux alatt az ide=reverse kernelparameter volt a megoldas. - Device nevek
CD,floppy,soros port, usb-printer,stb.
Pillanatnyilag ennyi jutott az eszembe, idovel meg lehet, hogy szaporodik
- A hozzászóláshoz be kell jelentkezni
Ha erdeklodnek nyugodtan iranyits at parat hozzam. Ugyis kene egy kis extra munka :)
- A hozzászóláshoz be kell jelentkezni
JOel, neharagudj, de ilyen gyenge valszam hozzaszolasokkal, mint ami neked van, kezdek benne ketkedni, hogy tenyleg olyen nagy spiler vagy ezen a teruleten.
ugyanis az alapelv az, hogy valoszinusegi esemenyeknel nincs olyan hogy "garantalt".
Legfeljeebb olyan van, hogy "valoszinusege kisebb, mint" x %.
- A hozzászóláshoz be kell jelentkezni
ttl 0
aztan egesz gyorsan megy. bar ennek is vannak negativ oldalai
- A hozzászóláshoz be kell jelentkezni
En lehet hogy elmaradtam valahol, de meg valami olyasmi reszt vartam volna, hogy hogyan tegyunk fel ilyen-olyan programokat. Pl. az eddigi leirasokkal felszerelkezve meg eleg sok man-olvasgatas kellet, mire a csh-t lecsereltem bash-ra, meg lett egy hasznalhato vim i sa gepen.
Trey, ha megkerhetlek egy koztes szintu reszt is irjal nekunk. En egyelore csak megismerni szeretnem a Linux utan a BSD-t mint alternativat, es bizony a HA cluster elott szeretnem legalabb a megszokott shellemet es editoromat magam alatt tudni :)
Egyebkent ezer hala a cikkekert, ezek nelkul nem tudom, mikor vagtam volna bele.
- A hozzászóláshoz be kell jelentkezni
Keraj :)
A MEH-nek mar raktam ossze FreeBSD-s szervert, egy masik miniszteriumnak is (illetve az egy vegyes rendszer volt fbsd + obsd + linux kivitelben) javaslom hogy toltsuk fel az allamigazgatast BSD-kkel es vegyuk meg a Sun-t :)
- A hozzászóláshoz be kell jelentkezni
http://www.openbsd.hu/faq/index.html
Most őszintén nehéz lenne elolvasni?
- A hozzászóláshoz be kell jelentkezni
Jó kis cikk... csak azt nem találtam meg, az előzőkben sem (bár lehet, hogy én voltam figyelmetlen), hogyan kell beállítani egy hálózatot...
De azért köszönjük a cikket... :)
- A hozzászóláshoz be kell jelentkezni
masodik cikk...
- A hozzászóláshoz be kell jelentkezni
Kösz, tényleg megtaláltam... átsiklott felette a szemem... :)
- A hozzászóláshoz be kell jelentkezni
Szerintem az eddig leirtakhoz is (mint barmi mashoz) van kello mennyisegu faq es help a neten, megis ugy tunik, hasznosak voltak az eddigi cikkek, sot, megis vannak kerdesek a kulonfele forumokban.
Egyebkent pedig igen. Nehez (illetve nehezebb) azt elolvasni, mivel sajnos nem rendelkezem anyanyelvi szintu angol nyelvismerettel, igy bizonyos dolokat csak sokszori atolvasas, extremebb esetben pedig csak tesztelgetesek utan ertek meg belolle.
Masreszrol pedig az a velemenyem, ha vadaszatot akarsz tanulni, ne az oroszlan legyen az elso predad. Vagyis mielott HA clustert kezdenek epiteni egy oprendszer alatt, elobb szivesen megismerkednek a tuzfalrendszerevel, a RAID-kezelesevel, stb.
Sot, mint Linuxrol attero emberke, meg annak is orulnek, ha a szokasos device-aimnak a nevet ismernem...
- A hozzászóláshoz be kell jelentkezni
Ertem en, hogy a cikk celja az OpenBSD HA lehetosegeinek bemutatasa, de a peldat elegge eroltetettnek erzem. Egy szerverfarm otkilences rendelkezesre allasahoz ennel azert tobb kell (terveztem mar ilyen architekturat).
Meg az is kicsit furcsanak tunik, hogy ha a redundans betap, hutes, stb rendelkezesre all a cegnel, akkor pont a cluster kornyezet szintjen kezdjenek el licenszeket es hardvert sporolni, es nem iparagi beszallitoktol *****mazo supportalt megoldast venni (amire lehet kotni SLA-t, tehat ha megsem jon be az a bizonyos otkilences rendelkezesreallas, akkor szepen fizeti a buntetest a szallito).
Egy otkilencest igenylo rendszer altalaban ugyanis azert igenyel ilyen rendelkezesreallast, mert a leallasa percenkent belekerul mondjuk masfelmillio forintba a cegnek. Ha nem kerul ennyibe, akkor nem is igenyel otkilencest:)
Nem akadekoskodni akarok, csak a cikk olyan benyomast kelt, mintha pl egy bank az e-banking rendszeret nyugodtan elfuttathatna egy ilyenen, holott nem.
- A hozzászóláshoz be kell jelentkezni
Abszolute nem errol szolt. Jelenleg egy egyszeru statikus oldal clusterezeserol van szol. Ennek viszont lehet 5 9-es rendelkezesre allasa.
Majd a kovetkezo cikkben a mogotte levo SQL szerver is clusterezve lesz, aztan kesz is a HA. Szerinted a Google mibol all?
Ilyen kicsi PC-kbol (AFAIK).
- A hozzászóláshoz be kell jelentkezni
>eg az is kicsit furcsanak tunik, hogy ha a redundans betap, hutes, stb rendelkezesre all a cegnel, akkor pont a cluster kornyezet szintjen kezdjenek el licenszeket es hardvert sporolni, es nem iparagi beszallitoktol *****mazo supportalt megoldast venni (amire lehet kotni SLA-t, tehat ha megsem jon be az a bizonyos otkilences rendelkezesreallas, akkor szepen fizeti a buntetest a szallito).
Sajnalom, hogy nem erted meg vagy nem akarod megerteni mit akartam mondani. Azert lettek felsorolva ezek, hogy tekintsjunk el a SPF ezen lehetosegeitol, mert ha nem irom bele, akkor a hozzaertok egybol jonnek azzal, hogy ``Hahahah, kihuzom a 220-at aztan szevasz.''
De mondok neked valos peldat erre.
A HUP az Axelero adatparkban van. Adott a redundans tap, adott a magas rendelkezesre-allasu halozat, de nekem 10 fillerem sincs. Az Axelero biztositja az infrastrukturat, nekem nincs egy q vasam se, hogy toled Sun 10K servert vegyek. Na ilyenkor mi van? Benez a lo az ablakon?
Vagy fogom magam, aztan megcsinalom magamnak OpenBSD-bol, Linuxbol, vagy FreeBSD-bol. Mert mindegyikre van mar CARP.
Es most mond, hogy nem eletszeru a pelda.
- A hozzászóláshoz be kell jelentkezni
> Nem akadekoskodni akarok, csak a cikk olyan benyomast kelt, mintha pl egy bank az e-banking rendszeret nyugodtan elfuttathatna egy ilyenen, holott nem.
Pont most csinálom az egyik banknak a homebanking szolgáltatását ilyen módszerrel... :-DDD
- A hozzászóláshoz be kell jelentkezni
Vannak dolgok, melyeket nem teljesen értem, itt kérdezem meg őket, hogy az esetleges válasz együtt legyen a cikkel.
Az egyik az, hogy egy ilyet hogyan kell fizikailag megcsinálni...? Mondjuk jön van egy madzag, azon jön az Internet. Ezt belevezetem egy tűzfalba (akkor ez már SPF, bár megoldható, hogy két tűzfal legyen, asszem most van kisérletezés alatt, hogy két tűzfal egymással összekötve tudja szinkronizálni a szabályait), majd onnan (vagy több) kábel megy tovább az egyes node -okhoz. A node -okban pedig két hálókártya van, egyikkel a világhálóra csatlakozik, a másikkal pedig a többi node -hoz csatlakozik, a heartbeat miatt.
Az csak futólagosan volt említve, hogy ha mondjuk egy biztonsági hiba miatt az egyes node -okon frissiteni kell pl. az apache -ot, olyankor elég csak "kihúzni" a heartbeat vezetéket (igy a többi node halottnak látja), majd a frissítés után visszadugni?
Végül pedig, ha három node van, és a master kiesik, mi alapján dől el, hogy a maradék kettő közül melyik lesz a master? Vagy a három közül a master hírdetési frekvenciája legyen 100, annak a gépnek, ami a master kiesése után átveszi annak funkcióit legyen 200, a harmadiknak pedig 300 ?
- A hozzászóláshoz be kell jelentkezni
Az elso kerdes: pfsync, de ha van eleg publikus cimed, akkor meg az sem kell. Egyetlen megkotese van a CARP-nak, hogy egy fizikai subneten kell lennie a node-oknak.
masodik kedes: semmit nem kell kihuzni
ifconfig carp0 down
megcsinalod amit akarsz
ifconfig carp0 up
harmadik kerdes: a frekvancia donti el, egyre lassabbra kell venni nyilvan
- A hozzászóláshoz be kell jelentkezni
>Nem akadekoskodni akarok, csak a cikk olyan benyomast kelt, mintha pl egy bank az e-banking rendszeret nyugodtan elfuttathatna egy ilyenen, holott nem.
Tedd már meg légyszives, hogy leirod, hogy szakmailag miért nem jó ez egy bankban?
Nem tartod megfelelőnek a OpenBSD stabilitását? Biztonságát?
- A hozzászóláshoz be kell jelentkezni
Ok.
Melyiknek?
Küldöm a PSZÁF-et a zsíros bírsággal.
- A hozzászóláshoz be kell jelentkezni
"Az Axelero biztositja az infrastrukturat, nekem nincs egy q vasam se, hogy toled Sun 10K servert vegyek. Na ilyenkor mi van? Benez a lo az ablakon?"
1. Kifejezetten maganemberkent irogatok a hup.hu-n, mivel alapvetoen az elmult 7-8 evben csak unix alapu rendszerekkel foglalkozom.
2. Ha en olyan helyzetben vagyok, hogy beteszek egy rendszert az Axelero adatparkjaba, akkor:
- ha ez nonprofit, akkor megcsinalom ugy ahogy akarom. Ellenben nincs olyan nonprofit cel ami miatt megerne otkilences vagy akar haromkilences architekturat kialakitani (architekturat!!!).
- ha nem nonprofit, akkor viszont minek csinalod egyaltalan penz es uzleti terv nelkul? Szerverek installalgatasa helyett tessek oltonyt felvenni, es befektetot keresni.
Eletszerunek eletszeru a peldad (sajnos), de kozgazdasagilag semmi ertelme. Mondom ezt mernokkent.
- A hozzászóláshoz be kell jelentkezni
A rendelkezesre allas nem arrol szol, hogy mi lehet, hanem arrol, hogy mi garantalt.
Google: ott azert ennel egy kicsit jobban atgondolt es hibaturobb architektura szolgalja ki a kereseket.
Mondom meg egyszer: nem akadekoskodni akarok..
- A hozzászóláshoz be kell jelentkezni
Igyekztem átnézni a hozzászólásokat is. Számomra az látszik, hogy a pár lelkes ifjú amatőr elfogadta a cikket, míg az, aki ért hozzá, igencsak félrevezetőnek ítélte.
Én is a félrevezető jelzőt találom a legmegfelelőbbnek. Ez a rendszer közel sem 5x9.
Az igaz, hogy el kell kerülni az SPF-et - de nem szabad lényegi dolgokat lehúzni, s figyelmen kívül hagyni! A single fali UTP csatlakozó ...
5x9-ben nincs fali csatlakozó, hiszen az legalább 6 további kontaktus és 3 csatlakozás. S amúgy is minimum 2 uveg megy minden vasba kifele, a quorum hálózat is redundáns, a leválasztott SAN is körkörös fiberen van. (SCSI-HA ?! ;) Igen, volt olyan is. A LUN-ok lockolása miatt nem lehet rendes HA-t csinálni.)
A webszerver HA-ba beletartozk a kapcsolatok perzisztenciája, meg kell tartania az azonosított kapcsolatok folyamatosságát is.
'Én felmondok' - én meg ajánlatot kérek két Crossbeam C30-ra, ha csóró vagyok, ha nem, akkor egy X40-re.
'Kérjünk fizetésemelést' - számoljunk TCO-t. Mennyibe is kerülne nekem a Te munkád? Mennyiért ad távolról 5x9-et a cég? Jé, nem kapsz emelést!
Master-Backup. Mi a helyzet, ha fennakad a hálókártya a masterben? Akkor nem tudod átvenni az IP-t a backup gépre.
Az ismertetett felépítés service-heartbeat alapú, ahol külső a heartbeat. Mi a helyzet, ha a webszerver deadlockba kerül? A külső progi tovább küldi a heartbeatet. Mint céloztam rá, ez a megoldás SPF lehet.
A CARP jó megoldás lehet bizonyos esetekben, de pl. más NFS esetén sem jó, holott az NFS elvileg mehet lockolás nélkül is.
Implementáció:
- engedélyezzük az apache indulását - és ha nem indul el?!
Nagyon sok dologban megbízott a cikk szerzője. Sokkal kevesebb dologban bízik meg az ember, ha a bind resolver-ében bízik meg. Elvégre az egy progi, s nem kell konfigolni. Ezek szerint, ha a DNS-ben csinálok LB-t a 2 webszerverre, akkor sokkal magasabb rendelkezésreállást kapok? Funkcionalitásban és folytonosságban a DNS-LB sokkal jobb, mint az itt ismertetett megoldás.
Igen! Mi a helyzet, ha valamit csinélni is szeretnék a webszerverrel, netán írni valamit rá? Mi a helyzet, ha kihal a disk? S a tárolt adatokra mindig szükségem van, hisz annak az elérhetőségétől függ az 5x9! Az nem érdekel, hogy az IP-n válaszol-e a TCP-stack a SYN-re...
- A hozzászóláshoz be kell jelentkezni
Ami furcsa lehet szamodra, hogy haosnlo (neha azonos) megbizhatosagi ertekeket lehet elerni opensource eszkozokkel _nagysagrendekkel_ olcsobban.
Ha te mernokkent opensource alapon alakitanal ki hasonlo rendszer egy banknak, akkor a munkaberedre _sokkal_ tobb jutna, mintha ugy kezded, hogy akkor vegyek meg ezt a ceges HA szoftvert 1X millaert, ezt a hardwer 1x millaert,...
;-)
- A hozzászóláshoz be kell jelentkezni
>Küldöm a PSZÁF-et a zsíros bírsággal.
Kuldjed.
Nem tudok olyan jogszabalyrol, hogy tilos lenne opensource programokat hasznalni bankokban.
Csak hogy felhomalyositsalak a Kozum ban _teljes_ tevekenysege Linux-on fut. A kozepes/kicsi brokercegek jelentos resze szinten Linux-ot hasznal szervernek.
- A hozzászóláshoz be kell jelentkezni
Itt az 5 9-es nem az az 5 9-es amin a nagy cegek lovagolni szoktak. Nyilvan itt nincs szupport, es senki nem fog garanciat vallalni. Itt az 5 9 egy egyszeru matematikai szam, ami abbol jon ki, hogy a webszerver nem fog tobbet allani, mint 5 perc egy evben. A kozgazdasag meg nem tudom hogy jon ide.
Aztan ide kevered az architekturat. Itt az 5 9 csakis a webszerver szolgaltatasrol szolt. Elismetlem: a 80-as portrol.
olvasd el a cikk ximet megegyszer:
magas rendelkezésre-állású webszerver készítése CARP-pal
es nem az a cikk cime, hogy
5 9-es architektura epitese
- A hozzászóláshoz be kell jelentkezni
Egyvalamire nem jutottatok el.
Nyilvánvaló, hogy nem nem ez a leírás alapján fog egy teljesen kezdő 5 9 -es rendszert építeni otthon, sima házi pc-ből, adsl -lel.
Ezért nem is törekedett (nem is törekedhetett) a teljességre ezen a téren, de arra tökéletesen elég mélyebb betekintést adjon a HA rendszerek felépítésébe, működésébe. Aki pedig többet szeretne, az komolyabb gyakorlat után, felvértezve szakmai-angol nyelvismerettel eléször is nekiáll olvasni szakirodalmat sokat, esetleg elmegy olyan céghez dolgozni, ahol ilyennel foglalkoznak, gyakorlat és tapasztalatképpen.
Ezekután a hozzászólásod mindenképpen hasznos, de szőrszálhasogatásnak tűnik...
- A hozzászóláshoz be kell jelentkezni
Kicsit regen volt, hogy ennel egzaktabban kellett errol a temarol fogalmaznom, es ippeg egy b@lf@sz vigyorgo amerikai eloadasat hallgatva irogatok. Szoval matematikailag igazad van. De: garantalhato = penzugyileg megerni garantalni = elfogadhatoan elhanyagolhato valoszinusegu a dolog = be tudja tartani a vallalt SLA-t = nem fog belebukni a ceg, aki garantalja.
Valahova linkeltem egy pdf-et, ahol ezek a dolgok sokkal egzaktabban le vannak irva.
- A hozzászóláshoz be kell jelentkezni
> Ez a rendszer közel sem 5x9.
latom neked is szemuveg kell :-D nem csoda, hiszen arrol az IP-rol irsz mint Joel :-D
>Az igaz, hogy el kell kerülni az SPF-et - de nem szabad lényegi dolgokat lehúzni, s figyelmen kívül hagyni! A single fali UTP csatlakozó ...
Amint a cikkben leirtam, ezeket tekintsuk adottnak, csak a web szolgaltatasrol beszeljunk.
Amint irtam ez az 5 9 azt jelenti, hogy ezzel a megoldassal lehet olyan web szolgaltatast biztositani, amely egy evben 99.999%-ban mukodik. Te azt allitod, hogy nem lehet. Jol ertem?
>Mi a helyzet, ha fennakad a hálókártya a masterben? Akkor nem tudod átvenni az IP-t a backup gépre.
Mit jelent az, hogy fennakad a halokartya? Csak hogy ki tudjam probalni...
> Funkcionalitásban és folytonosságban a DNS-LB sokkal jobb, mint az itt ismertetett megoldás.
A round robin dns mint jobb megoldas? Az inkabb load balance, mint failover, ne keverjuk a kettot.
En elhiszem, hogy a Sun tud jobb megoldast, hiszen ennek tudottan vannak hatulutoi. Csak nem mindegy mennyibol...
En fenntartom, hogy lehet matematikailag 5 9-es rendelkezesre-allast biztositani ezzel a felepitessel. Elkepzelheto, hogy ez a rendelkezesre-allas nem fog egybeesni sem a Microsoft Datacenter serverre megadott es vallalt 5 9-re, sem a HP altal adott 5 9-re (ami meglepoen tok mas), es azt is elismerem, hogy Bankok es KOrmanyzati szerverek nem foganek erre alapozni. (Bar megelodnel ha tudnad, hogy ott is hasznalnak BSD-ket).
- A hozzászóláshoz be kell jelentkezni
magas rendelkezesre allasu statikus webszerver.
A rendelkezesre allas amugy matematikailag a kovetkezo:
MTBF
___________
MTBF + MTTR
MTBF: Mean time between failure
MTTR: Mean time to repair
Vagyis nem egy konkret gep konkret adatarol van szo, hanem arrol, hogy az adott kialakitasu rendszernek matematikai eselye sincsen arra, hogy 5 percnel tobbet alljon egy evben (mert pl ott van 24 oraban egy support mernok es mindenbol potalkatresz, stb).
Megegyszer mondom: ez nem magas rendelkezesre allasu rendszer, csak egy kiserlet ra, ahol senki semmire nem vallal garanciat. Lehet ilyennel jatszadozni otthon, nonprofit modon, de aki ilyesmivel komolyan akar foglalkozni, annak ajanlom figyelmebe a BME ezzel foglalkozo szakiranyat (nalunk meg hibaturo rendszereknek hivtak, de kesobb megvaltozott a neve:).
- A hozzászóláshoz be kell jelentkezni
Engem nem az erdekel, hogy mit lehet elerni. Hanem az, hogy mit lehet garantalni. A magas rendelkezesre allas errol szol.
Nagysagrendekkel olcsobban csak akkor tudod elerni open source eszkozokkel mindezt, ha olcso munkaerovel dolgoztatsz, vagy a sajat munkaidodet 0 ertekunek tekinted.
En mernokkent sosem alakitanak ki a jelenleg elerheto opensource eszkozokkel ilyen rendszert, mert nem szeretnem sem a johiremet sem az anyagi eszkozeimet kockara tenni.
Masreszt: tudod mi a kulonbseg az OPEX es a CAPEX kozott? A fizetesed az OPEX (operating expenditure - mukodesi koltseg), a beruhazas viszont CAPEX. Mutass nekem egyetlen olyan gazdasagi szervet, aki ha valaszthat, akkor inkabb a CAPEX-en sporol, es nem az OPEX-en.
- A hozzászóláshoz be kell jelentkezni
>Megegyszer mondom: ez nem magas rendelkezesre allasu rendszer, csak egy kiserlet ra, ahol senki semmire nem vallal garanciat. Lehet ilyennel jatszadozni otthon, nonprofit modon, de aki ilyesmivel komolyan akar foglalkozni, annak ajanlom figyelmebe a BME ezzel foglalkozo szakiranyat (nalunk meg hibaturo rendszereknek hivtak, de kesobb megvaltozott a neve:).
Igazad van abban hogy senki nem vallal garanciat, de ezt hol vitatta valaki? Itt - hangsulyozom megegyszer az 5 9 nem az az 5 9 amelyet a nagy cegek adnak, es nem az az 5 9 amelyet a prospektusokban olvasni lehet.
Tisztaban vagyok vele mi az az ot kilenc. Vegeztem en is cluster tanfolyamot. Erdekes modon mas az 5 9 a Microsoft vilagban, es mas mondjuk a Sun-nal vagy a HP-nal. Most akkor melyik 5 9-rol beszelunk? Az 5 9 kb. annyira relativ, mint a multkori RSBAC. Sok mindent ertenek alatta, es ahany ceg annyit jelent.
- A hozzászóláshoz be kell jelentkezni
Mind a stabilitas, mind a biztonsag vegsosoron nem mas, mint egy sor a koltsegek tablazataban. Minden egyes ujabb platform, amit behozol egy data centerbe, jokora addicionalis koltseget jelent emberek szintjen. Kell ugye legalabb 2 rendszergazda.
Egy masik fontos kerdes: OpenBSD hogy all FC kartya driverekkel? Lassan tenyleg nem lesz olyan bank itthon ,aki nem egy kozponti SAN-t alakitott ki az adattarolas szamara.
- A hozzászóláshoz be kell jelentkezni
5 9 az, amit az egyetemen tanitanak...:)
Mast jelent szolgaltatas es platform szinten. Epeszu ember csak a szolgaltatastol koveteli meg, de ott akkor abban hiba nem lehet (pl web eseten lehal egy szerver es a felhasznalonak a masikon ujra authentikalni kell - ez nem 5 9).
- A hozzászóláshoz be kell jelentkezni
Ki mondta, hogy valaki is tiltaná az opensource-ot?
Én egy szóval sem említettem. Igazából az olyan kontárkodást kellene tiltani, mint amire pl. ez a cikk ösztönöz. Pl. a Crossbeam is opensource.
Nincs tilalom, de van, amit nem tud teljesíteni egy összekontárkodott rendszer.
Az meg, hogy ki kit és miről homályosíthatna fel, abba pedig szerintem ne menjünk bele.
(Konzumbank? Nem azzal volt az a botrány, hogy lenyeltek betéteket? Csütörtökön láttam, azt hiszem. ;) )
- A hozzászóláshoz be kell jelentkezni
"En elhiszem, hogy a Sun tud jobb megoldast, hiszen ennek tudottan vannak hatulutoi. Csak nem mindegy mennyibol..."
Hagyjuk mar ezt a Sun-t, hetvege van, nem dolgozom...
- A hozzászóláshoz be kell jelentkezni
Nézd, adjuk oda ezt a cikket mondjuk dr. Patariczának (BME, MIT) és lássuk, hogy milyen minősítést adna rá. Én hozzá képest csak egy műkedvelő vagyok a témában, mégis szúrja a szemem néhány dolog...
Szép dolog a lelkesedés, de a szakmai igényesség is fontos.
(Trey, nem bántani akarlak, komolyan..., köszi, hogy van hup és elmondhatom a véleményem:)
- A hozzászóláshoz be kell jelentkezni
Es ki nem sz*a*rja le dr. Patariczát meg a többi. OpenBSD, CARP, PF az *én* választásom. És valahogy akkora ívben sz*a*rok bele az ilyen emberek szajaba, hogy azt te el sem tudod kepzelni. Szakmai igényesség?? wtf ez nem valami cégportal ember. hetkoznapi embereknek szól. elvagy tevedbe dumbass.
_|_ Ennyi a velemenyem.
- A hozzászóláshoz be kell jelentkezni
Visszanéztem a hireket
A Baumag botrány van mostanában, de az nem bank. Valamit nagyon keverhetsz
- A hozzászóláshoz be kell jelentkezni
>> Ez a rendszer közel sem 5x9.
>latom neked is szemuveg kell :-D nem csoda, hiszen arrol az IP-rol irsz mint Joel :-D
Szerintem ebből inkább arra lehet következtetni, hogy talán konyítunk a témához...
>>Az igaz, hogy el kell kerülni az SPF-et - de nem szabad lényegi dolgokat lehúzni, s figyelmen kívül hagyni! A single fali UTP csatlakozó ...
>Amint a cikkben leirtam, ezeket tekintsuk adottnak, csak a web szolgaltatasrol beszeljunk.
Miért is? A cikkben egy IP-ről és egy kártya konfigjáról írsz, holott legalább 4-re van szükség. OK, a környezet adott, de a konfigból hiányzik 3 kártya: +1 kifele és +2 a szinkronra.
>Amint irtam ez az 5 9 azt jelenti, hogy ezzel a megoldassal lehet olyan web szolgaltatast biztositani, amely egy evben 99.999%-ban mukodik. Te azt allitod, hogy nem lehet. Jol ertem?
Tudom, hogy a fórum keretei között értelmetlenség az exponenciális eloszlás tulajdonságairól beszélnem. Azt végképp értelmetlen lenne elmondani, hogyan viselkedik egy inverz Laplace transzformált mátrix ezen eloszlásokból.
Ez a rendszer képes 5x9-ben működni egy éven keresztül. Viszont megjegyzem, hogy a meghibásodás valószínűsége nagyobb, mintha egyetlen eszközt használnál (exponenciális eloszlásfüggvény meredekség-összetevője változik).
Az 5x9 azt jelenti, hogy minden körülmény között képes a teljes rendszer az adott megkötések mellett biztosítani az 5x9-et.
>>Mi a helyzet, ha fennakad a hálókártya a masterben? Akkor nem tudod átvenni az IP-t a backup gépre.
>Mit jelent az, hogy fennakad a halokartya? Csak hogy ki tudjam probalni...
Olyan megdöglés, hogy a stack TCP/IP fele él ( a service látszólag megy), de nem tud csomagot küldeni, ugyanakkor ARP szinrten minden megy. Pl. block any out és arp -s MAC pub egyszerre (semmi se megy ki, de ARP mindig megy magától).
>> Funkcionalitásban és folytonosságban a DNS-LB sokkal jobb, mint az itt ismertetett megoldás.
>A round robin dns mint jobb megoldas? Az inkabb load balance, mint failover, ne keverjuk a kettot.
Sajnos a neve LB, ez ellen nem tudok mit tenni. Viszont a speckódat teljesíti, mert minden esetben válaszol egyik szerver, s ugyanúgy nincs állapotszinkron. A kliens resolvere megoldja az észrevétlen átállást a következő IP-re, ha az adott szerver nem válaszol és van további IP is.
>En elhiszem, hogy a Sun tud jobb megoldast, hiszen ennek tudottan vannak hatulutoi. Csak nem mindegy mennyibol...
Én nem vagyok Sun dolgozó, jelen esetben ellenérdekelt fél vagyok.
>En fenntartom, hogy lehet matematikailag 5 9-es rendelkezesre-allast biztositani ezzel a felepitessel.
Én fenntartom, hogy nem rendelkezel a szükséges matamatikai alapokkal ahhoz, hogy ezt a nagyon erős kijelentést megtegyed.
>Elkepzelheto, hogy ez a rendelkezesre-allas nem fog egybeesni sem a Microsoft Datacenter serverre megadott es vallalt 5 9-re, sem a HP altal adott 5 9-re (ami meglepoen tok mas),
Sajnos az ottani adat valós is lehet, míg ez csak blöff.
>es azt is elismerem, hogy Bankok es KOrmanyzati szerverek nem foganek erre alapozni. (Bar megelodnel ha tudnad, hogy ott is hasznalnak BSD-ket).
Szerintem Te is meglepődnél, hogy hol mit használnak. Tudod, az évek, a tapasztalat és a megfelelő szintű szakképzettség ...
- A hozzászóláshoz be kell jelentkezni
Jéééééééééééé...
Az 1. , azaz első alkalom, mikor tökéletesen egyetértek thuglife -vel...
Na, ezt is megértük... :)
- A hozzászóláshoz be kell jelentkezni
Oda felulre az van irva, hogy Hungarian Unix Portal. Ebbol en arra kovetkeztetek, hogy informatikaval, azon belul is unix rendszerekkel foglalkozik, szakmai szinten - nem kontar modjara.
A cikk egyes kijelentesei olyan dolgokat tartalmaznak, amiket ha vizsgan mondana a hallgato, ugy kivagjak a terembol az indexevel egyutt, hogy a laba nem erne a foldet. Kisza ezeket nagyjabol lejjebb felsorolta.
Ezek utan miert tamadsz engem ilyen alpari stilusban, es honnan veszed a batorsagot ahhoz, hogy emberi meltosagomban megserts?
- A hozzászóláshoz be kell jelentkezni
Pedig nekem is ugy remlik, hogy Konzumbank, valami hiradoban volt. Egy ugyfel lekotott masfel milliot es harom honap mulva nem tudta felszabaditani. Kozoltek vele, hogy nincs ilyen lekotes, holott ott lobogtatta a kezeben a banki papirt rola... Valahol eltunt a szamla.
- A hozzászóláshoz be kell jelentkezni
Tudod, nem veszed észre, hogy az egész hozzászólás-folyamotok átcsapott kötözködésbe és szőrszálhasogatásba... sajnos. Nem értettétek meg a cikknek és a cikk-sorozatnak a lényegét, sajnálom. Nos, ő csak erre hívta fel a figyelmetek, a maga módján...
- A hozzászóláshoz be kell jelentkezni
"Amint irtam ez az 5 9 azt jelenti, hogy ezzel a megoldassal lehet olyan web szolgaltatast biztositani, amely egy evben 99.999%-ban mukodik. Te azt allitod, hogy nem lehet. Jol ertem?"
Jol. Te ugyanis azt erted 5 9 alatt, hogy evi 5 perc szolgaltataskieses elerheto. Ilyen egyetlen PC-vel is elerheto, csak mazli kerdese.
Az 5 9 azt jelenti valojaban, hogy annak a valoszinusege, hogy a rendszer 5 percnel tobbet all egy evben 0. Ez vizsgan buktatokerdes...
- A hozzászóláshoz be kell jelentkezni
Tehat jol ertem, hogy az a baj, ha egy szakmai cikk kijelenteseirol egy szakmai portalon szakmai vita bontakozik ki?
Bocs...
- A hozzászóláshoz be kell jelentkezni
nem tudom mire osztonoz teged ez a cikk. senki nem mondta, hogy ebbol valakinek is barmit kellene erteni. de ettol a felsobbrendu dumatol hanyok...
- A hozzászóláshoz be kell jelentkezni
Bar ha jol emlekszem, ugy inditottam, hogy "ertem, hogy az OpenBSD HA-jat akartad bemutatni", de akkor miert kell 99,999%-rol beszelgetni? Ez rettenetesen felrevezeto mindenkinek, aki itt olvas ezekrol a rendszerekrol eloszor, a hozzaertonek pedig egybol felmegy a szemoldoke tole... mert nem preciz.
- A hozzászóláshoz be kell jelentkezni
Nem, az a baj, hogy egy kezdőknek, a témával most ismerkedőknek készült cikket azért kritizáltok, mert nem törekedett teljes szakmai tökélyre. Persze, úgy is meg lehetett volna írni (akkor biztos tetszene nektek is), csak akkor hogyan értenék meg azoknak ez a cikk igazán készült...
És persze a felsöbbrendüségi érzés, nos az tényleg kisüt a hozzászólásaitokból...
Csak ennyi a baj...
- A hozzászóláshoz be kell jelentkezni
megérted, de a stílusa báltozatlan :-(
- A hozzászóláshoz be kell jelentkezni
Rendben, koszonjuk a kioktatast, megertettem hogy ez nem 5 9-es rendelkezesre-allas.
- A hozzászóláshoz be kell jelentkezni
Ez már egy másik dolog, mint tudjuk "a stílus maga az ember..." :)
- A hozzászóláshoz be kell jelentkezni
Teljes szakmai tokely??? Alapveto targyi tevedes 5 9-esnek hivni egy ilyen alap HA rendszert.
Hagyjuk mar abba ezt a flame-et, mert csak mindenki ideges lesz. Igerem tobbet nem hivom fel alapveto szakmai tevedesre senkinek sem a figyelmet...
- A hozzászóláshoz be kell jelentkezni
tudnam, hogy mi koze van egy banknak a webszerverekhez, es hogy jutottunk el a PC-tol a mainframe-ek vilagaig, azt jo volna tudni
- A hozzászóláshoz be kell jelentkezni
nyugi, en orulok, hogy el tudunk rola vitatkozni, hajlando is vagyok tanulni a tolem tapasztaltabbaktol, de kisza baratod fellengzos stilusara nem vagyok vevo... :-)
- A hozzászóláshoz be kell jelentkezni
>Igerem tobbet nem hivom fel alapveto szakmai tevedesre senkinek sem a figyelmet...
Ne tedd. pl engem erdekel a velemenyed.
>Az 5 9 azt jelenti valojaban, hogy annak a valoszinusege, hogy a rendszer 5 percnel tobbet all egy evben 0.
Ez volt az a mondat, amivel ha kezded talan nem lett volna flame.;-)
Az informatika _oriasi_ terules, hiaba ert valaki az egyik reszehez profin a tobbitol nagyon tavol lehet. Meg akkor is ha azt gondolja, hogy ert hozza.;-)
- A hozzászóláshoz be kell jelentkezni
Mainframe? Fileszerver Windows PC-k lognak mindenfele SAN-okon, nem mainframe-ek. Vajon a webszerverrol kiszolgalt tartalmat hol erdemes tarolni? Lokalis diszkeken? Vagy egy kozponti ket telephely kozott tukrozott SAN-on, ahol a backup is joval egyszerubben megoldott...
- A hozzászóláshoz be kell jelentkezni
Igen, nekem sokszor bebizonyosodott mar, hogy amit a matematika oran levezettek a tablanal, az a valo eletben nem biztos hogy ugy is lesz. Ennek ellenere elfogadom, hogy nem 5 9-es a rendszer, de vallom, hogy megfelelo szamu kliens eseteben, egy ilyen rendszerrel fel lehet venni a versenyt egy kereskedelmi megoldassal.
Arban biztos, rendelekzesre-allasban ezek szerint nem (legalabbis szerintetek, bar a netcraft adatai alapjan erdekes, hogy a legjobb uptime-okat, es teljesitmenyeket FreeBSD-kbol, BSDOS-ekbol es nem Solarisokbol, es nem AIX-ekbol hoztak ki). Es ezert vannak bajban a nagy cegek a UNIX-ukkal, es ezert nyitnak egymas utan a nyilt forras fele. Mert ezek a ``gagyi'', ``osszehackelt'' rendszerek egyre jobban szorongatjak oket.
A bankok, kormanyzati szektor mas szfera, oda nem lehet egyelore betorni, de ez annak koszonheto, hogy nem is erdeke a targyalo feleknek ez.
- A hozzászóláshoz be kell jelentkezni
2 nagy cegrol tudok akik 100%-os(ebben nem vagyok biztos, de tuti jobb, mint 5 9) rendelkezesreallast csinaltak maguknak. Legjobb tudomasom szerint mindketto Linux-ot, es PC-t valasztott!
Akamai: egyszerre 15000 processzor online;-)
Google: kb 100000 PC, de ennek nagyresze letolt, nem kiszolgal.
Erdekes nem?
- A hozzászóláshoz be kell jelentkezni
Hat nem tudom, hogy hol van penz arra, hogy SAN-on taroljanak webszerver adatokat. Azert attol meg messze vannak a magyaroszagi cegek, hogy a webszerveruket FC-rol hajtsak. Az a baj, hogy tul nagy cegnel dolgozol, es tul nagy cegekkel vagy kapcsolatban. A magyarorszagi atlag cegeknek problemat okoz sokszor az is, hogy a meglevo 10baseT halozatrol atalljanak 100-ra. Pedig mar a gigabit erosen jelen van a nagy cegek strategiajaban evek ota.
- A hozzászóláshoz be kell jelentkezni
Nem volt mas valasztasuk, mert ennyi processzorra barmelyik OS licensz draga lenne. Ennek ellenere nem keves embert fizet mindket ceg a naponta a tappancsat feldobo parszaz PC szervizelesere.
Semmi problemam egyik open source operacios rendszerrel sem. De tudom, hogy hol lehet oket hasznalni, es hol nem.
Sem google sem akamai nem failover cluster amugy...
- A hozzászóláshoz be kell jelentkezni
Ez szamomra azert nem olyan nagy baj:))
Nade, most egy hetig megszabadultok tolem, utazom tanulni Munchenbe...
- A hozzászóláshoz be kell jelentkezni
Azért akkor is jó kis cikk... :)
- A hozzászóláshoz be kell jelentkezni
Pfff, most erre mit mondjak? Hogy "te kis hülye"? Nem rég volt itt a PSZÁF, nemigazán tudtak mibe belekötni... Nevetséges vagy.
- A hozzászóláshoz be kell jelentkezni
>Ez a rendszer képes 5x9-ben működni egy éven keresztül. Viszont megjegyzem, hogy a meghibásodás valószínűsége nagyobb, mintha egyetlen eszközt használnál (exponenciális eloszlásfüggvény meredekség-összetevője változik).
Szerintem tobb even keresztul is. De koszonom, hogy elismerted, en csak ennyit akartam mondani amikor a cikkben leirtam amit leirtam. Azt irtam benne, hogy magadnak keszites (olvasd csak el ujra), senki nem vallalja ra az 5 9-et, de kepes olyan mukodesre.
Tegyuk fel, hogy ezt a kiepitest 254 CARP hostbol keszited el (ennyi azt hiszem a maximum). Akkor mennyi a valoszinusege, hogy ez ne hozza azt a megbizhatosagot, amit mondjuk egy sok millio dollart ero vas?
>Sajnos a neve LB, ez ellen nem tudok mit tenni. Viszont a speckódat teljesíti, mert minden esetben válaszol egyik szerver, s ugyanúgy nincs állapotszinkron. A kliens resolvere megoldja az észrevétlen átállást a következő IP-re, ha az adott szerver nem válaszol és van további IP is.
El kell hogy keseritselek, de ez jobb, mint a Round Robin DNS. Azt is elmondom miert. A Round Robin DNS (vagy LB DNS) az amikor egy hostra tobb IP-t jegyzunk (remelem egy dologrol beszelunk). Ha az egyik host kihal, akkor csak minden masodik refresh-re kapod meg az oldalt. Itt ez nem fordulhat elo.
- A hozzászóláshoz be kell jelentkezni
Megígérem, azonnal szólni fogok, amint tudok bankot, aki ilyen módszerekkel építgeti a rendszerét, hogy azonnal berakhasd családtagjaiddal együtt a pénzed. Biztosan jó kondíciókat fognak tudni kínálni, hiszen nem kell elkölteniük a pénzt ilyen felesleges nagygépekre, egyebekre...
- A hozzászóláshoz be kell jelentkezni
> senki nem vallalja ra az 5 9-et, de kepes olyan mukodesre.
Egy trabant is képes 100 évig folyamatosan menni, de senki sem garantálja.
Sajnos még mindig elbeszélünk egymés mellett. Attól, hogy egy rendszer visszanézve 5x9-es, az nem azt jelenti, hogy jövőben is az lesz. Informatikában, ha valamire azt mondják, hogy 5x9, akkor azt a jövőre, s nem a múltra értik. Amire Te gondolsz, ott ez csak a múltra mondható ki, a jövőre nem. A lottó 5-öst is el tudod vinni, hiszen csak az öt számot kell tudnod. Ezt könnyen teljesítheted - utólag, viszont előre igen nehéz teljesíteni ezt a feltételt. Holott mindkét esetben 5 meghatározott számról van szó.
254 vs. 2: nem tudom megmondani, hisz egy 3-4 állapotú rendszer is meghaladja a matematikai tudásomat. Nem vagyok számítógép.
Mindegy, itt nem is az a lényeg. Ez valóban megfelel a poor-man's failover megoldásának és nagyon sokat lehet tanulni az ilyen rendszerekkel való játékkal.
Mindenki elkezdi valahol a tanulást, s minden lépcsőt át kell járni. Ez sajnos nekem nem sikerült, így csak elméleti emlékfoszlányaim vannak a matematikai alapokról. Azóta én is legózom, s elhiszem, amit a gyártók mondanak, hisz azt leverhetem rajtuk. Saját rendszernél meg kénytelen lennék kiszámolni.
- A hozzászóláshoz be kell jelentkezni
kedves Joel, akármit is jelenthet az 5-9, de azt, hogy nulla a valószínűsége t időnél hosszabb meghibásodásnak, azt SEMMIKÉPP.
nulla valószínűségű meghibásodást ugyanis SEMMILYEN rendszerrel nem lehet elérni, soha.
- A hozzászóláshoz be kell jelentkezni
Megelőztél, pont ezt akartam írni én is! :-)
- A hozzászóláshoz be kell jelentkezni
Es meg ha igy is van, az informatikai hattare barmit is valtozik? Szerintem ez mar egy mas tema, amirol te beszelsz.
onyx
- A hozzászóláshoz be kell jelentkezni
Ezennel szeretném fölkérni a HUP közösségét, hogy szervezzünk gyűjtést arra, hogy _Joelnek és kiszának EGY -EGY ILYEN [www.tomcatpolo.hu] pólót vásároljunk, majd ünnepélyes keretek között átadjuk; melyet azon okból kapnak meg, hogy trey igen épületes, olvasmányos és okító jellegű cikkét ilyen sikeresen széjjelfik*zták.
- A hozzászóláshoz be kell jelentkezni
Ird le pontosan mi erdekel, es akovetkezo cikkban az lesz.
- A hozzászóláshoz be kell jelentkezni
Lehet, hogy a stilusa miatt kinyilik az ember zsebeben a bicska, de szakmai oldalrol most pont igaz van -- kar, hogy a flame miatt senki nem hajlando belegondolni abba, amit irt.
Teny, hogy trey cikke jo, es felesleges a flame, mert senki nem ez alapjan fog holnap HA rendszereket kesziteni, de szerintem meg egy ilyen ismerteto jellegu cikknel is hasznos a szakmai pontatlansagok kijavitasa.
(Ha valaminek, akkor az ilyen szemelyeskedo postoknak tenyleg nincs semmi ertelme...)
- A hozzászóláshoz be kell jelentkezni
>Oda felulre az van irva, hogy Hungarian Unix Portal. Ebbol >en arra kovetkeztetek, hogy informatikaval, azon belul is unix >rendszerekkel foglalkozik, szakmai szinten - nem kontar >modjara.
Szakmai szint az nem ez, az mar egy joval magasabb dolog. A portal arra van, hogy a sok ember jozan paraszti esszel is megertse a dolgokat. Itt most senki nem beszelt kontarsagrol.
>A cikk egyes kijelentesei olyan dolgokat tartalmaznak, >amiket ha vizsgan mondana a hallgato, ugy kivagjak a >terembol az indexevel egyutt, hogy a laba nem erne a >foldet. Kisza ezeket nagyjabol lejjebb felsorolta.
Ha valaki egy vizsgara innen keszul fel az bal*****. De ha nem tetszik a cikk írj jobbat hulyegyerek. Nem csak pofazni kell.
>Ezek utan miert tamadsz engem ilyen alpari stilusban, es >honnan veszed a batorsagot ahhoz, hogy emberi >meltosagomban megserts?
Ezek utan, es ez elott is szivesen tamadlak akarmilyen alpari stilusban. Batorsagot? Ehhez nem kell batorsag. Es akkor sertelek meg amikor akarlak. Jogom van hozza. Neked jogod van visszapofazni, vagy idejonni is beverni a kepem.
mofo
- A hozzászóláshoz be kell jelentkezni
De van. Az autógyártó garantálja, hogy az új autód gyártási hibáktól mentes, még ha ez nincs is mindig így. A biztosító is egyfajta garanciát vállal olyan eseményekre, amiknek relatíve kicsi a bekövetkezési valószínűsége. Az egyik problémám az ilyen opensource világmegváltásokkal az, hogy a rendelkezésre állás feltételei közül csak egy nagyon kis szeletet fednek le. A másik, hogy nem működnek. A harmadik, hogy senki nem vállal rájuk garanciát. Persze nem is az opensource megoldással van baj, hanem inkább azokkal, akik elhiszik, hogy ez tényleg mindenre jó.
- A hozzászóláshoz be kell jelentkezni
>de szerintem meg egy ilyen ismerteto jellegu cikknel is hasznos a szakmai pontatlansagok kijavitasa.
Ezzel nincs is baj, hiszen senki tudasa nem tokeletes. Hajlando is vagyok elfogadni a megalapozott ellenerveket, es hajlando vagyok elvitatkozni barkivel, hiszen a komoly szakkonyvek is ugy keszulnek, hogy valaki megirja, majd egy masik hozza erto ember lektoralja azt. Itt az olvasok lektoralnak, de nem hiszem, hogy barmelyik lektor is kontarkodasnak nevezne az altala lektoralt muvet, meg ha abban talal is olyan hibat, amelyet ki kell javitani. Plane, hogy ha a mu mar olyan melysegekben targyalja a dolgokat, ahol matematikusokkal kell vitatkozni.
Szoval itt a reszemrol csak stilussal volt a baj, es csak egy ember stilusaval.
De ettol fuggetlenul orulok, hogy a ``nagy'' emberek is szemuket az oldalon tartjak, es jelzik ha valami nem passzol. Csak kerem, normalisan tegyek...
- A hozzászóláshoz be kell jelentkezni
Meg kell értened őket is. Valszinuleg sok milliot kerestek mar HA rendszerek epitesevel, es most jon valaki aki azt mondja, hogy ez olcson is megcsinalhato. Nem hiszem hogy kepes volt (pl kisza) nyugodtan irni. Ha lenne a hup-nak voice verzioja akkor a leirt szovegeket orditva mondta volna.;-)
- A hozzászóláshoz be kell jelentkezni
kisza az egyik legnyugodtabb ember, akit ismerek...
nezzetek vissza a 2-3 evvek ezelotti leveleit a netfilter dev listan:)
- A hozzászóláshoz be kell jelentkezni
Szerintem mindkét szempontban van némi igazság. HA rendszerekhez léteznek számítások, ajánlások stb. (nem csak hardverre, hanem szoftverre is). Érthető tehát, ha az ezzel foglalkozók trey cikkét "barkácsolásnak" tartják.
Másfelől nem minden szervezet, amelynek jól jönne a magas rendelkezésreállás, tudja megfizetni a professzionális eszközket. Ilyen jóformán az összes nonprofit szervezet. Pl. egy egyetemi tanszéken (mondjuk egy informatikai karon) a hallgatók éjjel-nappal aktívan használják a webes szolgáltatásokat, nincs pénz speciális hardverre, de van sok elfekvő számítógép és szakértelem. Ilyen helyeken ideális lehet a trey által ismertetett megoldás.
Arra is kellene gondolni, hogy tényleg HA rendszert építeni nehéz dolog. Adatredundancia kapcsán szokták mesélni, hogy volt egy cég, amely két redundáns szervert helyezett el a WTC két ikertornyában és büszke volt magára...
Én úgy gondolom, hogy a nagyobb rendelkezésreállás felé tett összes lépés üdvözlendő, és a trey kritikusai is örülnének, ha pl. minden tanulmányi rendszer front szervere csak ilyen értelemben lenne HA... :)
minden jót,
p.
- A hozzászóláshoz be kell jelentkezni
Ok azt felejtettek el, hogy az 5 9-et a klasszikus nagykonyvban megirt modon vettek, mig en az 5 9-et arra ertettem, hogy nem fog a szerveren futo szolgaltatas kevesebben allni egy evben, mit 5 perc. Ebben az esetben igazuk van, hogy ez nem egy 5 9-es cluster, de nem is vagyok olyan hulye, hogy erre azt mondjam hogy az.
De tartom, hogy meg lehet ezzel csinalni azt hogy nem lesz 5 percnel kevesebb kises egy evben, es hajlando vagyok olyan szervert epiteni ilyen modon, amelyet szembe teszek az altaluk osszeepitett cuccal (csak gyozzek megvenni). Tolem rendezhetunk egy ilyen versenyt. :-D
> Adatredundancia kapcsán szokták mesélni, hogy volt egy cég, amely két redundáns szervert helyezett el a WTC két ikertornyában és büszke volt magára...
Igen az is 5 9 volt az elso repuloig.... :-D (na jo ezzel nem viccelunk)
>Én úgy gondolom, hogy a nagyobb rendelkezésreállás felé tett összes lépés üdvözlendő, és a trey kritikusai is örülnének, ha pl. minden tanulmányi rendszer front szervere csak ilyen értelemben lenne HA... :)
Hat igen, ezzel en is egy vagyok. A magyarorszagi informatikat meg nem kell nekem bemutatni, mert benne dolgozom mar jo par eve. Nincsenek itt clusterek tomegesen, mert amikor cluster tanfolyamra mentem 3/4 evet kellett varni, hogy osszejojjon 4-5 ember, mert alatta nem indittottak tanfolyamot. Szoval ez egy kis orszag, kis business, es igenis van jovoje az ilyen kontarkodasoknak.
- A hozzászóláshoz be kell jelentkezni
Szerintem az eddigi hozzászólók közül koránt sem Joel és Kisza az, aki megérdemli a pólót, hanem inkább azok, akik megfelelő felkészültség nélkül nyilatkoznak dolgokról, ráadásul meglehetősen nyers hangnemben.
- A hozzászóláshoz be kell jelentkezni
Mondjuk az érdekes lenne, hogy ha van két node így összekapcsolva, én hozzákapcsolódom, engem nyilvánvalóan a MASTER szolgál ki. Ha ő valami miatt leáll, és a SLAVE -re kell váltania a rendszernek, miként lehetne megoldani, hogy a kapcsolat ne vesszen el...?
- A hozzászóláshoz be kell jelentkezni
Attol meg varjuk orommel az SQL-es cluster cikkedet amit igertel :)
Csak ne ugy kezd, hogy vegy egy M$ Datacenter-t :D
- A hozzászóláshoz be kell jelentkezni
Akkor sincs joga PSZÁF-el fenyegetőznie, kár itt szépítgetni a dolgot...
- A hozzászóláshoz be kell jelentkezni
Igen, valóban hülye voltam. Ezt orvoslandó valóban beszéltem a PSZÁF-fal. Mindennek ellenére a következő rész csak az én interpretációmat reprezentálja.
Tehát: törvény valóban nincs. Két vonatkozó törvény szabályozza a területet (283/2001 és az új PSZÁF). Egyik sem ad ilyen szintű előírást, hisz nem is adhat, valamint általános értelműnek kell lennie. Így a session-vesztés is elfogadott. Az új szabályozás 2005. októberében lép életbe. A Bázel II. azonban kötelező érvényű lesz!
A kérdéskör bankoknál nem merül fel, csak brókereknél. A def. szernt a tőkepiaci tranzakciók megléte a választóvonal. Tehát egy tőkepiacon jelenlevő banknál mégis érvénybe lép.
Nem lehet törvényileg előírni a 9-eket, hisz pl. a banknak van egy terméke, amiből max 3-at ad el egy évben - nincs értelme a 5x9-nek...
A PSZÁF a szabályoknak való megfelelést ellenőrzi. Tehát pl. elkéri a BCP-t és a BCP-re vonatkozó audit reportot. A report eredményét nézi meg. Ha valamit kifogásolt az audit, akkot felszólít majd büntet.
A BCP minden esetben menedzsment döntés. Ha a főnök az analízisek (Cobit, Risk, etc.) alapján kiböki az elvárásait, akkor abból kell BCP-t csinálni, s azt leauditálni.
Magánember a nyílvánosságot vonhatja be, hamegbízható infóhoz jut. Pl. a bank stratégiainak tekinti a webet, ezt leírja, ezután az elvárásokat nem teljesítő implementációt végez, akkor hazudik, s jó kis Blikk cikk lehet a dologból.
Tehát ezek szerint a 'küldöm a PSZÁF-et' kijelentés azt kérdezte, hogy mi van a BCP-tekben, s átment-e a rendszer az auditon. (Ahol a matematikai 5x9-et, s nem a cikkben szereplő 5x9-et nézik. )
Elnézést a tudatlanságomért!
- A hozzászóláshoz be kell jelentkezni
Nem volt teljesen egyértelmű, a kapcsolat alatt pl. http-session t értettem.
Mint kiderült volt, ezt nem lehet megoldani, mert nem alkalmazás-szinten van clusterelve, hanem sokkal lejjebb.
- A hozzászóláshoz be kell jelentkezni
biztos mondtam mar neked, majd ha olyan helyen dolgozol, ahol ezeket a szamokat komolyan veszik, es leverik rajtad, ha nem teljesited amit a szerzodesben vallaltal, akkor biztos maskent latod majd a dolgokat (pl vonnak a fizetesedbol, mert nem hoztad az adott rendelkezesreallast).
- A hozzászóláshoz be kell jelentkezni
Igen, nagyon jó és hasznos cikk, sokat lehet tanulni a cikk alapján.
(Egyedül csak az 5x9 a kicsit sok benne.)
- A hozzászóláshoz be kell jelentkezni
Szerintem Kisza és Joel hozzászólásai inkább az IT kereskedelem egy részének megnyílvánulásai.
Különösen akkor igaz ez mikor Kisza a dns-rr-ről beszél:
"Funkcionalitásban és folytonosságban a DNS-LB sokkal jobb, mint az itt ismertetett megoldás."
A DNS-LB semmilyen HA képességgel nem bír, szemben a fentivel. A dns-rr csak terheléselosztó.
Valamint Joel beszólása:
Nagysagrendekkel olcsobban csak akkor tudod elerni open source eszkozokkel mindezt, ha olcso munkaerovel dolgoztatsz, vagy a sajat munkaidodet 0 ertekunek tekinted.
[...]
Masreszt: tudod mi a kulonbseg az OPEX es a CAPEX kozott? A fizetesed az OPEX (operating expenditure - mukodesi koltseg), a beruhazas viszont CAPEX. Mutass nekem egyetlen olyan gazdasagi szervet, aki ha valaszthat, akkor inkabb a CAPEX-en sporol, es nem az OPEX-en.
Jó HA-hoz elsősorban minőségi és állandóan meglévő szakértelem kell. És itt nem telefonos supportra meg ilyen olyan support fokozatra gondolok.
"En mernokkent sosem alakitanak ki a jelenleg elerheto opensource eszkozokkel ilyen rendszert, mert nem szeretnem sem a johiremet sem az anyagi eszkozeimet kockara tenni."
Aláírom nincs megfelelő opensource cluster file system, de opensource rendszerrel (kernel+alkalmazások) lehet felette dolgozni.
Szvsz ma MO-n bármelyik vezetőség, kaparni fogja a falat örömében, ha két 0-val olcsóbban jössz ki, még annak az árán is ha csak három/négy kilencest teljesítesz. Ha másért nem akkor azért, mert a maradék két nullát megfelezik egymás közt.
A másik, hogy hol találsz ISP-t aki 5 9-es rendelkezésre állást vállal. M.o-n sehol. Akkor meg minek több száz milát webkiszolgálásra költeni.
Vajon a webszerverrol kiszolgalt tartalmat hol erdemes tarolni? Lokalis diszkeken? Vagy egy kozponti ket telephely kozott tukrozott SAN-on, ahol a backup is joval egyszerubben megoldott...
Egy alkalmazás (nem fájlszerver) funkciót ellátó jó web/sql szerver HA-hoz NEM kell (bár használható) SAN meg shared scsi, mert nincs rá szükség. Fájlszerver esetén pedig egy cluster fájlrendszerre elöbb van szükég mint SAN-ra.
Amúgy az egyész HA történetben, nem feltétlenül az adattárolás a művészet, hanem annak eldöntése mi működik és mi nem, valamint az erre adott reakciók.
balsa
- A hozzászóláshoz be kell jelentkezni
Miért is?
Mintha trey írta volna, hogy a mögöttes sql szerverről egyelőre nem szól a cikk...
Ha meg http auth-ra gondolsz. Emlékeim szerint az minden egyes http connection elején újra elmegy, csak akkor már a böngésződ nem kérdi újra, hanem 'becache'eli...
- A hozzászóláshoz be kell jelentkezni
Ezt alkalmazasszerver szinten szokas megoldani (J2EE-ben servletcontext es httpsession perzisztencia, illetve stateful session-bean perzisztencia megoldasok vannak ra: egyes gyartoknal memory based, masok egy HA sql szervert hasznalnak ra),
- A hozzászóláshoz be kell jelentkezni
"Hat igen, ezzel en is egy vagyok. A magyarorszagi informatikat meg nem kell nekem bemutatni, mert benne dolgozom mar jo par eve. Nincsenek itt clusterek tomegesen, mert amikor cluster tanfolyamra mentem 3/4 evet kellett varni, hogy osszejojjon 4-5 ember, mert alatta nem indittottak tanfolyamot. Szoval ez egy kis orszag, kis business, es igenis van jovoje az ilyen kontarkodasoknak."
Hmmm, nalunk egesz jol mennek a cluster eladasok, es negyedevente tele van a tanfolyam emberekkel.:)
Attol fuggetlenul igazad van, csak ezek a "kontarkodasok" meg veletlenul sem garantalnak otkilences rendelkezesre allast. Kb 3 kilencest lehet ilyesmivel garantalni maximum (de ez sacc) - bar annyit talan egy jobb minosegu PC-vel is lehet. Ebben az esetben a planned outage-ek kivedesere lehet hasznalni egy ilyen megoldast (amig az egyik gepet patch-eljuk addig a masik mukodik).
Ket "elegge" gyartofuggetlen doksi HA-rol:
http://see.sun.com/cgi-bin/gx.cgi/mcp?p=041Eie041EkC46D5I012000mwYM4wYLF
http://www.sun.com/blueprints/1100/HAFund.pdf
- A hozzászóláshoz be kell jelentkezni
"A DNS-LB semmilyen HA képességgel nem bír, szemben a fentivel. A dns-rr csak terheléselosztó."
Pontosan. De ket fuggetlen webszerverrel dns-lb magasabb rendelkezesre allasra kepes, mint a fenti HA megoldas (mivel fuggetlenek), plusz dupla mennyisegu keres kiszolgalasara kepes. Kisza funkcionalitast es folytonossagot emlegetett, nem HA kepessegeket. Igy ertheto a dolog?
"Jó HA-hoz elsősorban minőségi és állandóan meglévő szakértelem kell. És itt nem telefonos supportra meg ilyen olyan support fokozatra gondolok."
Igen, de egy "normalis rendszer" eseten a szakertelem eleg a telepites/installacio folyaman, mert maga a cluster fool proof lesz (jo, lattam mar en is rendszergazdat aki az eles cluster egyik tagjat futas kozben elkezdte patch-elni ami miatt lehalt az egesz, de ez normalis process-ekkel es megfelelo hozzaallasu rendszergazdak alkalmazasaval kikerulheto). Egy cluster akkor mukodik jol, ha csak akkor kell hozzanyulni, ha elfustol benne egy CPU, vagy elpusztul egy diszk, netan fel kell tenni egy patch-et.
"Szvsz ma MO-n bármelyik vezetőség, kaparni fogja a falat örömében, ha két 0-val olcsóbban jössz ki, még annak az árán is ha csak három/négy kilencest teljesítesz. Ha másért nem akkor azért, mert a maradék két nullát megfelezik egymás közt."
3 vagy 4 kilencest elerni sem mindig egyszeru:) De egyebkent teljesen igazad van. Es az ujabb kilencesek altalaban valoban 1-1 ujabb 0-at jelentenek az osszeg vegen.
Amit trey osszekevert a cikkben az az elerheto/garantalt rendelkezesre allas kozti kulonbseg, ahol a garantalt nem azt jelenti, hogy egy ceg garantalja, hanem azt, hogy az architektura, a rendszer osszetevoi es a policy egyuttese garantalja a rendszer rendelkezesre allasat (ez az, aminek nagyon szep matematikai hattere van).
"A másik, hogy hol találsz ISP-t aki 5 9-es rendelkezésre állást vállal. M.o-n sehol. Akkor meg minek több száz milát webkiszolgálásra költeni."
En ugy tudom, hogy volt ilyen szolgaltato, de csodbe ment:)
"Amúgy az egyész HA történetben, nem feltétlenül az adattárolás a művészet, hanem annak eldöntése mi működik és mi nem, valamint az erre adott reakciók."
Pontosan. Es eleg terjedelmes irodalommal rendelkezik a tema, ugyhogy remelem sokaknak felkeltettuk ezzel a vitaval a figyelmet ahhoz, hogy melyebben elmelyedjen benne:)
- A hozzászóláshoz be kell jelentkezni
>De ket fuggetlen webszerverrel dns-lb magasabb rendelkezesre allasra kepes, mint a fenti HA megoldas (mivel fuggetlenek)
Egyszer mintha mar leirtam volna, hogy a LB-DNS-nel ha kiesik egy tag, akkor csak minden masodik keresre kapod meg a weboldalt (2 webszerver eseten). Ket szerver eseten 50% eselyed van, hogy nem kapod meg az oldalt. Ket szerver eseten a CARP jobb szolgalatast fog nyujtani nekem, mint az LB-DNS. Sot tobb webszerver eseten is. Egy webszerver eseten pedig engem az erdekel, hogy weboldalt lassak, es nem azt, hogy a host nem elerheto. Hogy a matematikusok kiszamlojak hogy ebben az esetben jobb a rendelkezesre-allas az lehet, de engem az ugyfel ugy rugna ezert valagba, hogy repulnek 5 metert :-)
Nekem ez szamit.
- A hozzászóláshoz be kell jelentkezni
Miert minden masodik kerdesre kapod? Minden masodik DNS lookup-ra kapod ugyanazt az IP-t, de attol fuggetlenul a kliensek HTTP keresei elott nem fog minden egyes esetben DNS lookup-ot csinalni az ugyfel gepe. Es en meg olyan DNS LB-t nem lattam, amelyik nem pingelte az IP-ket mondjuk 5 masodpercenkent es valasz hianyaban nem vette ki az adott IP cimet a pool-bol - az ilyen LB-nek semmi ertelmeísem lenne.
- A hozzászóláshoz be kell jelentkezni
Bocs, ping termeszetesen nem ICMP, hanem szolgaltatas szintu ping (pl GET /ping.jsp HTTP/1.1 :)
- A hozzászóláshoz be kell jelentkezni
Mondjuk halistennek van net az oktatoteremben. Kar, hogy penteken vizsga is lesz:)
- A hozzászóláshoz be kell jelentkezni
Nem a rendszer alkatrészeinek meghibásodásának valószinűsége 0, hanem az, hogy a rendszer által nyújtott szolgáltatás mondjuk 1 évben maximum x ideig nem lesz elérhető. Ezt kell garantálni minden körülmény között.
99% garantálható minden PC alkatrésznél (ez 4 teljes nap kiesést jelent, ami alatt be lehet szerezni az elfüstölt alkatrészt, vissza lehet állítani a backup-ot, stb... 4 napba legalább 8-10 unplanned outage belefér).
99,9% garantálásához már nagyon jó minőségű hardveralkatrészekre, vagy gyengébb minőségű alkatrészekből épített redundáns rendszerre van szükség. A kettő költsége szerintem összemérhető.
99,99%-hoz már nagyon jó minőségű alkatrészekből épített teljesen redundáns kialakítású rendszerre van szükség (és ne csak a diszkre, CPU-ra gondoljatok, hanem pl. táp, hűtés is), lehetőleg hot swap alkatrészekkel (CPU, memória is jó, ha hot swap) + jó minőségű szervízszerződéssel (hogy 1 órán belül megérkezzen a cserealkatrész és ezzel megszüntethessük a SPOF-ot ami az 1 alkatrész elfüstöléséből adódik a rendszerben).
99,999%-hoz ugyanaz mint a 4 kilences, plusz lokális támogató mérnök + lokálisan tárolt hot swap alkatrészek. Másképp nem tudod garantálni, hogy a rendszer hibáját 5 percen belül ki tudod javítani (ha 5 percen túl is van még SPOF a rendszerben, akkor egy újabb hiba a másik rendszeren máris downtime-ot okoz, és jön a kötbér).
- A hozzászóláshoz be kell jelentkezni
>Miert minden masodik kerdesre kapod?
Erre gondoltam, csak rosszul fogalmaztam meg.
Az IP pingelos mokat nem neveznem valami profi megoldasnak (inkabb ganyolasnak), igy inkabb, maradok a CARP-nal...
- A hozzászóláshoz be kell jelentkezni
Végigolvastam a thread-eket, és írt valaki (sorry, mar nem keresem vissza h ki) egy érdekességet. Mi van, ha a http daemon hal el? Mert szép dolog a külön dedikált eth kártyán vagy RS232-n keresztüli heartbeat, de az nem az adott service-re vonatkozik. És bát trey tûzbe tenné kezét ezért a ,,barkácsmegoldásért'', én ilyet nem tennék az apache-ért...
- A hozzászóláshoz be kell jelentkezni
Pedig a sokmillioba kerulo content switch-ek es hardver load balancerek is valamilyen "ping" (nem feltetlenul ICMP echo, lehet egy HTTP get keres is, ha HTTP-t load balancolunk) alapjan erzekelik, hogy a mogottuk levo farmbol kihalt egy gep.
- A hozzászóláshoz be kell jelentkezni
Azt OS szinten, szoftver watchdog-gal szoktak megoldani. Apache nem tudom, hogy hasznal-e ilyet alapbol (regen volt hozza szerencsem), amikkel mostanaban foglalkozom, ott a termekek beepitett szolgaltatasa, hogy szoftverhiba eseten ujrainditjak a kiszolgalodemont.
- A hozzászóláshoz be kell jelentkezni
Trey ha ennyire nyilt forras melett vagy miert vmware t hasznalsz ?:)
bochs.sf.net
plex86.sf.net
- A hozzászóláshoz be kell jelentkezni
Itt jön képbe a cron-ból percenként indított ,,HEAD HTTP/1.1
''? :-) És ha a crond hal el? Írjunk rá egy figyelõ daemont ami nézi, hogy él-e a cron...
Nyilván valami kernel szintû checker kellene hozzá, de egy userspace program mindenképp kell a kernelbeli dolgok macerálásához.
- A hozzászóláshoz be kell jelentkezni
Ez nem cron. Ez egy folyamatosan futo, hihetetlenul egyszeru nehany soros C-ben megirt program (annyira egyszeru, hogy akar matematikailag is ellenorizheto, vagyis ez a komponensre sokkal de sokkal megbizhatobb, mint a kiszolgaloprocessz, es nem fog se segfault-tal se hasonlo durva dologgal elszallni).
Vagyis ez egy processz, ami masodpercenkent kapcsolodik a kiszolgalohoz es ha nem sikerul a kapcsolodas, akkor ujrainditja.
Cron-os megoldas azert sem jo, mert tul nagy terhelest okozna 10-20 masodpercenkent processeket inditani.
Failover clustereknel amugy egy eleg konkret problema tud lenni az, ha az alkalmazas futasat a masik node-rol monitorozo script az elso gep magas terhelese miatt nem kap idoben valaszt, es ezert azt hiszi, hogy leallt a szolgaltatas azon a node-on...
- A hozzászóláshoz be kell jelentkezni
Termeszetesen a fenti szamok 2 node-os failover cluster-re ertendoek.
- A hozzászóláshoz be kell jelentkezni
Ezt értem. De ha minden alkatrész meghibásodásának valószinűsége pozitív, szintúgy annak a valószínűsége, hogy a lokális támogató mérnök romlott halat eszik ebédre és rosszul lesz, akkor az egészre hogy jöhet ki 0 valószínűség? Nem inkább arról van szó, hogy annak a valószínűsége, hogy a rendszer t > 0 időnél többet áll (itt t = 5 perc), valamilyen "elég kicsi" pozitív szám (de persze nem 0)?
KisKresz
- A hozzászóláshoz be kell jelentkezni
Persze, cron-t csak tréfából írtam, erre ez teljesen alkalmatlan.
Vagyis ez egy processz, ami masodpercenkent kapcsolodik a kiszolgalohoz es ha nem sikerul a kapcsolodas, akkor ujrainditja.
Ez azt jelenti, ha jól gondolom, hogy nem elég csak a távoli monitorozó gépen futtatni a checker programot, hanem a monitorozandó masinán is kell egy service ami veszi a checkertõl az esetleges daemon restart üzeneteket.
elso gep magas terhelese miatt nem kap idoben valaszt
És erre mi lehet jó megoldás?
- A hozzászóláshoz be kell jelentkezni
Én ugyan az egészhez nem sokat értek, de mivel itt valószínűségekről van szó, azt nem árt tudni, hogy igaz, hogy a lehetetlen esemény valószínűsége 0, a fordítottja viszont nem. Vagyis abból, hogy egy esemény bekövetkezésének valószínűsége 0, még nem következik, hogy lehetetlen eseményről van szó :)
- A hozzászóláshoz be kell jelentkezni
"És erre mi lehet jó megoldás?"
Folyamatos teljesitmenymonitorozas, megfelelo meretezes, idoben torteno bovites, többrétegű architektúra.
Failover cluster-eket tipikusan nem webszervernek alkalmaznak (ott egy loadbalancer-rel megoldott horizontalisan skalazodo szerverfarm sokkal optimalisabb megoldast ad), hanem hatterrendszereknek, fileszerver, adatbazis, OLTP (online transaction processing), adattarhaz (data warehousing) ala. Tobbretegu architekturanal a felette levo retegek viszonylag jol tudnak skalazodni anelkul, hogy ezt a reteget komolyan leterheljek (web infrastruktura eseten: a web/alkalmazas szerverek cache-lnek adatokat, oldalakat es emiatt nem kell az adatbazishoz/file-szerverhez fordulni minden egyes oldallekeres miatt, stb).
Volt 2000 körül egy white paper erről a témáról, szerintem google megtalálja a "n tier architecture" kulcsszóra.
- A hozzászóláshoz be kell jelentkezni
De, valami ilyesmi:) Jobban belegondolva valamilyen várható értékkel lehetne ezt jobban leírni és annak kell az 5 perc alá esnie 99,999%-nál.
- A hozzászóláshoz be kell jelentkezni
Ez már teljesen off topic, de az itt tapasztalható hangnemen kissé megütköztem. Végigolvastam a teljes vitát, és nekem, mint a témában kellően járatlan olvasónak hasznos volt. Ha maga a cikk tartalmazta volna a hozzáadott infókat, még jobb lett volna, mert nem növelte volna sokkal a hosszát, és akkor talán a thuglife modorú embereknek felködlene, hogy az informatikának bizony kemény TUDOMÁNYOS szakirodalma van, és csak azért, mert ők sose hallottak efféléről (vagy nagyon jól utánozzák ezt a sajnálatos állapotot), attól az még van, és az asztali gépük ettől (is) működhet egyáltalán. A cikket kritizálóknak alapvetően annyi volt a szándéka, hogy erre felhívja a figyelmünket. A nemtudásért megsértődni pedig igazán kár. Egyébként meg, csak azért, mert az itteni cikkek a "köznépnek" szólnak, miért ne lehetne bennük súlyosabb tartalom, akár csak utalás szintjén? Hadd merengjen a kedves cikkolvasó. Attól még nem csökken a népszaporulat.
üdv mindenkinek,
cruiser
- A hozzászóláshoz be kell jelentkezni
Joel, Kisza!
Csak egy apro elmeleti kerdes, elvonatkoztatva a CARP-tol. Nem falmelni szeretnek, csak okosodni;-)
Szoval ha kiesik egy tag a clusterbol akkor attol meg nem romlik a cluster rendelkezesreallasa (gondolom en naivan) leven azert cluster, hogy ha kiesik valaki, attol meg gurul a szeker tovabb. Ha ket napig esik ki, akkor ket napig csak az egyik node mukodik, es nem all semmi szolgaltatas -> a cluster rendelkezesre allasa meg 100%. Vagy rosszul gondolom?
[Nem tanultam en elmeletet, csak szeretnem megtudni a frankot;-)]
Elore is koszi, meg udv
- A hozzászóláshoz be kell jelentkezni
[ itt OpenBSD flamelés volt, meg hosszú sztori hogy hogyan lehet egyetlen SCSI paranccsal leölni az OpenBSD kernelt és vele a teljes root filesystemet véglegesen, de mire megírtam, thuglife megoldotta az eredeti problémát : online SCSI bus probe ]
[ és mire ezt megirtam, rájöttem hogy az így probe-olt cdromot mountolás után lehetetlen umountolni (Invalid argument), ergo *****nak pofon ]
Konzekvencia: OpenBSD suxx, és bármilyen high availability-rol cikkezni vele kapcsolatban botor cselekedet.
- A hozzászóláshoz be kell jelentkezni
Gabu!!!! Teee! A legfontosabbat kihagytad!!!!
OpenBSD 3.5 (GENERIC) #41: Mon Mar 29 12:38:53 MST 2004
deraadt@vax.openbsd.org:/usr/src/sys/arch/vax/compile/GENERIC
VAXstation 4000/VLC [14000006 04010102]
Azert csak VAX ;-D
- A hozzászóláshoz be kell jelentkezni
Hát nemis network installal sikerült végül...
- A hozzászóláshoz be kell jelentkezni
na de mostmar tudjuk, hogy kerulni kell SCIOCRESET -et ;)
- A hozzászóláshoz be kell jelentkezni
Trey!
Nagyon jó kedvet csináltál (szerintem sokaknak) az openBSD-hez. A jó, hogy lelkes maradsz annak ellenére, hogy akik egyébként érdemben írni lusták, ilyenkor alázni meg fikázni hamar beesnek...
Mind1 nem ezért jöttem...
Csak 1 kérdés:
Lesz szó a továbbiakban arról, hogy egy ilyen rendszeren hogyan szokás megoldani a dinamikus webtartalom (főleg, ha a kliensektől érkezik tárolandó adat) szükségszerűen gyors szinkronizálását a cluster-en?
Row
- A hozzászóláshoz be kell jelentkezni