A fenti kérdést a Daemonnews egyik cikke tette fel.
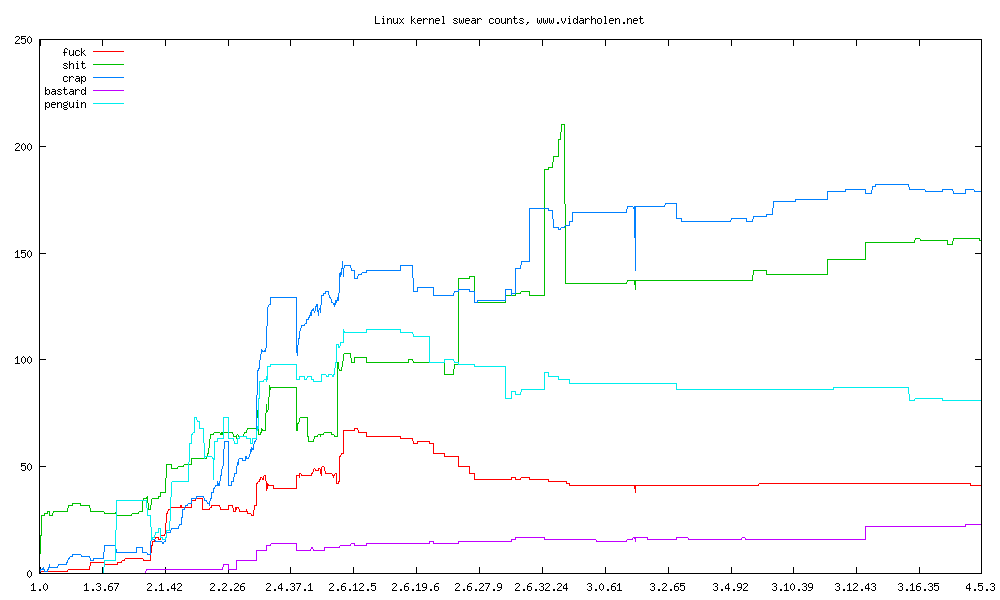
Létezik egy projekt, amely a Linux kernelben számolja a szitok szavakat és grafikonosan megjeleníti. A grafikon szerint nagyon népszerűek a Linux kernelfejlesztők körében a crap, fuck, bastard, stb. szavak. Érdekesség, hogy a crap majdnem háromszor annyiszor fordul elő a 2.6.7-es kernel forrásában, mint mondjuk a penguin szó.
Ennek a projektnek a mintájára készítette el Hendrik Scholz a FreeBSD forrás-elemző szkriptjét. A szkript a FreeBSD különböző verzióinak src-all disztribúcióját elemzi, és végez rajtuk statisztikai számításokat. Az eredmények szintén grafikonosan jelennek meg.A szkript 1994-től 2004-ig vizsgálta a HEAD branch-eket. Az elemzés során több szempont szerint is értékelésre kerültek az eredmények. Az egyik szempont az volt, hogy hányszor van a forráskódban utalás másik operációs rendszerre (Linux, NetBSD, OpenBSD, Solaris, Windows). Ebben a kategóriában a Linux került az első helyre. A FreeBSD src-all-okban ezt az operációs rendszert emlegették a legtöbbször.
Elemzésre került a dokumentáció is. A szkript undocumented, XXX, és FIXME sorokat keresett a forrásban (az XXX használják a legtöbbször a FIXME mellett a nem teljes vagy hibás kód megjelölésére).
Végül a szitok szavak is kigyűjtésre kerültek. A kereséskor a bastard, fuck, garbage, junk, shit, suck, ugly szavak kerültek elemzésre és grafikonra rajzolásra.
A projekt honlapja a grafikonokkal, kommentárokkal itt.
{kind=link}