- A hozzászóláshoz be kell jelentkezni
- 5808 megtekintés
Hozzászólások
Azt hiszem nekem újra kell gondolnom a stratégiámat, mert lehet jobb lenne időzíteni az ilyen feladatokat. :)
- A hozzászóláshoz be kell jelentkezni
(x) ha a menedzsment szoftver okot ad rá (pl. prefailure állapot, hiba stb.)
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
+1
- A hozzászóláshoz be kell jelentkezni
SMART adatokat nézem szinte az összes gépen muninnal.
- A hozzászóláshoz be kell jelentkezni
Az beleveheto a "ha elromlik"-ba szerintem. Ujabb szavazas johet arrol, hogy kinel mi a hatar az "elromlott"-ra. :)
A fix idot en mindenkepp tulzonak tartom, kiveve ha felsobb helyrol elvaras es fizetik a poliszit. Van diszk ami 1 ev utan (pedig sas meg enterspajz megminden) es van ami mar kozel 9 evnyi uzemorat porgott.
- A hozzászóláshoz be kell jelentkezni
A 9 évet mindenképpen túlzásnak tartom. 9 éves vinyó legföljebb 80GB-os. Egy más célra újonnan vett NAS-on, vagy újonnan épített RAID-en egy ici-pici volume-on elfér az a 80GB, a lecserélés költsége szerintem köbö a 80GB átmásolásához kellő munkadíjnak felel meg.
Amúgy ha lett volna olyan opció, hogy "legföljebb 5 év, vagy ha hibázik", akkor azt választottam volna.
- A hozzászóláshoz be kell jelentkezni
Az már nálam 3 év felett. :)
- A hozzászóláshoz be kell jelentkezni
A fix idős csere szerintem több gondot okoz mint amennyit megold. Egy jó merevlemez 10 évig is elmegy, de van olyan új merevlemez ami fél év után megdöglik. Gyártási hiba lehet az ok, garanciában természetesen cserélik de adatmentés ritkán jár a garancia mellé. Egy felesleges csere, felesleges kockázattal is jár. Rendszeres backup és archiválás a megoldás adatbiztonságra és nem a felesleges merevlemezcsere.
- A hozzászóláshoz be kell jelentkezni
A mai ínséges időkben azt hiszem nagy luxus* előre meghatározott időszakonként cserélni ezeket. A rendszer legyen hibatűrő és legyen tartalék a polcon. Ott elfér és nem kopik :)
* Kivéve, ha más, kevésbé kritikus helyre még felhasználható.
- A hozzászóláshoz be kell jelentkezni
Mi számít hibatűrőnek? Egy RAID10-ben bőven dögölhet meg a másik diszk, míg az újra próbál rámászni az adat...
A több paritásos megoldások (pld. RAID6) pedig sok helyre lassúak.
--
zsebHUP-ot használok!
- A hozzászóláshoz be kell jelentkezni
Pont így jártam (RAID10). 3,5 éves diszkek és a spare is halott volt már.
- A hozzászóláshoz be kell jelentkezni
"a spare is halott volt már."
Ez menet közben hogy-hogy nem derült ki?
- A hozzászóláshoz be kell jelentkezni
PEBKAC
- A hozzászóláshoz be kell jelentkezni
Persze, minden relatív, az adott helyzet határozza meg és a te tapasztalaid mást mondhatnak. Én úgy látom, hogy több (>3) lábú RAID10 esetén elég jó esélyünk van, hogy nem az előbb kihullott vinyó párja esik ki következőnek. Ha a polcról bekerül a tartalék jó eséllyel hamarabb összeszinkronizál, minthogy behalna egy másik.
Persze, nem zárható ki. Ahogyan az sem, hogy a vadi új vagy üzemórában fiatal vinyó egyszer csak kiesik. nagy számú mintából vett statisztikával lehetne dönteni.
Jobb híján a saját kis számú mintámból (100+ HDD) tudok következtetni.
RAID-10, RAID-50, RAID-60-nal + polcon lévő vinyóval + backuppal én azért elég jól alszom :)
Utoljára 2008-ban volt, hogy 4 vinyóból álló 2x RAID1-ből egyszerre 2 vinyó esett ki. Szerencsére mindkettőnek csak az egyik lába. Na az tényleg kicsit megemelte a pulzusomat :)
- A hozzászóláshoz be kell jelentkezni
Azért egy mai 4 (lassan 6) terás diszknél az egyszerre elég tág fogalom tud lenni. Valahol a pár nap és a pár hét között...
--
zsebHUP-ot használok!
- A hozzászóláshoz be kell jelentkezni
Igazad van. Számomra ez a méret/diszk már oroszrulett kategória :) Azt hittem másnál is. Pont az 1 diszkre koncentált adat mennyiség miatt megbuknak a korábbi hibatűrő technikák. RAID-hez nem is használok ezért 1TB feletti vinyókat.
- A hozzászóláshoz be kell jelentkezni
Imádkozzam végig azt 3 napot, mire újraépiti? :)
- A hozzászóláshoz be kell jelentkezni
Igen. Más lehetőség nincs.
- A hozzászóláshoz be kell jelentkezni
Vagy használj háromlábú tükröt. Persze rendszeres backup mellett...
- A hozzászóláshoz be kell jelentkezni
+1.
- A hozzászóláshoz be kell jelentkezni
Inkabb az lehet, hogy egy "alombo'l" szarmazo diszkek hullanak ki egyszerre. Nalunk most egy (6+2)*1.5T-s RAID6-ban rohadt le 3 egyszerre, par nap (max egy-ke't he't) kulonbseggel, egzaktul 3 e'v utan. Az serial number-ek kozott minimalis volt a kulonbseg, szoval kabe egymas utan johettek le a gyartosorrol. 3bo'l ketto" kattogosra szarta o"ssze maga't, de egyro"l me'g ki lehetett vakarni az adatokat. Erdekes volt az is, sajat elektronikat kellett epiteni ami reszetelte egy bad sector kiolvasasa utan, csak ugy lehetett leolvasni rola, de ugy majdnem mindent... mindegy, ez ma'r ma's mese :]
- A hozzászóláshoz be kell jelentkezni
Hibaturo az, hogy a rendszer barmelyik resze megdoglik, attol meg mukodokepes marad.
Valamint ha valami elromlik, akkor az dogoljon meg rendesen (aka fail hard), ne kezdjen el ujrainditassal/stb... probalkozni.
Nalunk mindenbol legalabb 2 van: bejovo vonalbol, firewall-bol, load balancer-bol, szerverterembol, szerverbol, switchbol, ..., es mind failover setup-ban (tobbnyire automatikus failover).
Ez nemcsak rendelkezesre allast novel, de biztonsagossa teszi az upgrade/deploy -okat is. Sok ido es energia, de ahol komolyan gondoljak, boven megeri.
- A hozzászóláshoz be kell jelentkezni
Azért ha egy raid10-ben az a-b párok egyike megpusztul, akkor közel sem bőven dögölhet meg a következő diszk, mert ha épp a döglött párja követi a társát az örök bitmezőkre, akkor azért nem leszel hűdeboldog... RAID esetén egyébként a gyors, olcsó, nagy megbízhatóságú tulajdonságok közül igazán kettő választható - amelyiket _nem_ fogja tudni a tömb :-P
- A hozzászóláshoz be kell jelentkezni
Csak ha elromlik: a SMART altal jelzett legelso pending, vagy reallocated szektornal.
- A hozzászóláshoz be kell jelentkezni
Vegyes a kép. Céges file szerveren (bár bőven van mentés róla) legfeljebb 3 évente csere. Többinél az első gyanús smart jelre, bár sajna az sem tud előre jelezni mindent.
- A hozzászóláshoz be kell jelentkezni
Ez pont most jött: http://blog.backblaze.com/2013/11/12/how-long-do-disk-drives-last/
- A hozzászóláshoz be kell jelentkezni
{kind=link}
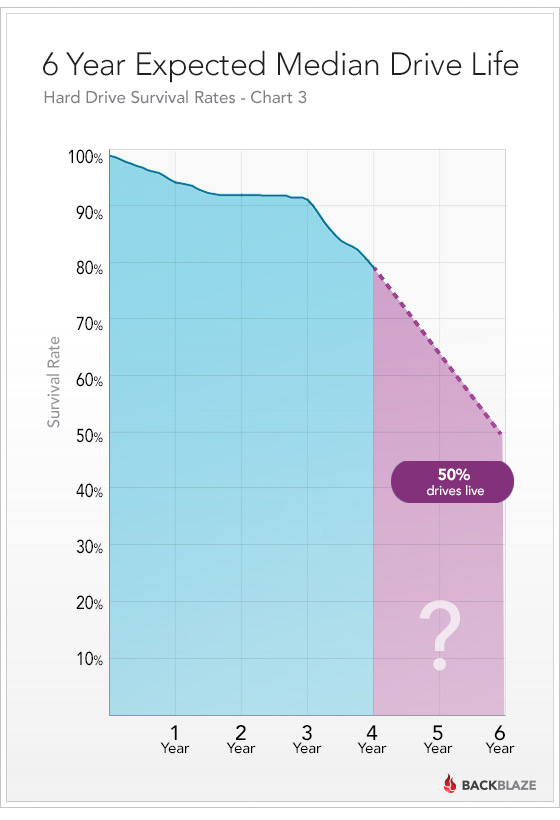{kind=link}
RAID-nél ha elromlik az bőven elég szerintem. Bár még szerencsére csak 1x volt rá példa. Sajnos kissé soká tartott 2TB adattömböt "újraépíteni", de nem lett legalább adatvesztés. RAID nélkül viszont figyelni kell a SMART-ot, ha kezdődik a "bad sector" esemény, akkor már előjel, és gyors read-only adatmentés, csere. Erre viszont már többször volt példa.
- A hozzászóláshoz be kell jelentkezni
RAID nélkül, csupán SMART-ot figyelni: orosz rulett
- A hozzászóláshoz be kell jelentkezni
Ha jól van tervezve/összerakva a RAID, akkor igen. De ez azt is feltételezi, hogy raid5 elfelejt, vagy legalább nem túl nagy diszkekből rak össze ilyen istencsapását az emberfia (huszonpár TB RAID5-ból kiszédülő diszk utáni rebuild közben megdöglő újabb egy-két diszk tökéletes forrása az örömnek meg a boldogságnak, pláne hajnali kettőkor....), hogy minél rövidebb ideig tartson a "térdre, imához" (eredeti nevén rebuild) időszak.
A SMART-ra támaszkodás, meg az egy diszken tároljuk az még desktop esetben sem biztos, hogy vállalható, szoktam mondani, hogy ami egy példányban van meg, az nincs meg.
- A hozzászóláshoz be kell jelentkezni
szoftveres vagy hardveres raid volt?
Én nem tapasztaltam raid5 nél sem Tb-körüli tagoknál hogy túl lassú lenne a hardveres raid újraépítése
raid5 öt nagyon nem szeretem, de ezek a lehetőségek:)
raid10-hez meg minimum 2db hot spare
- A hozzászóláshoz be kell jelentkezni
Ezek szerint nem használod a diszkeket, csak állnak, és unatkoznak.
--
zsebHUP-ot használok!
- A hozzászóláshoz be kell jelentkezni
ebéd időben szinkronizáltam, lehet:)
- A hozzászóláshoz be kell jelentkezni
Egy "régi motoros" ismerősöm és az Ő bölcsességei jutottak eszembe, úgy mint pl:
1, pénteken új dologba nem kezdünk, senki se akar hétvégén túlórázni, ha valami nem jól sikerül
2, ami működik, ahhoz nem nyúlunk és nem rontjuk el
Én úgy tapasztaltam, hogy a vinyó halál viszonylag ritkán jósolható meg előre. Bár van kivétel, és olyankor illik is cselekedni, de egyébként én is "Csak ha elromlik" opciót választottam. Egyébként meg sub, csak az olyan snassz, mikor csupán ennyit ír be valaki :P
- A hozzászóláshoz be kell jelentkezni
+1
Kapacitásbővítés belefér, de egyébként dolgozza meg az árát. Utolsó SCSI-s szerveremben még vígan fut a 2001-es Quantum Atlas.
- A hozzászóláshoz be kell jelentkezni
A második pont általam ismert változata:
Ami nem romlott el, azt nem javítjuk meg!
- A hozzászóláshoz be kell jelentkezni
Tobbnyire virtualis szervereket hasznalok, a szolgaltatom megoldja a cseret akkor es amikor kell, en meg eszre sem veszem, es ez igy nekem jo.
--
|8]
- A hozzászóláshoz be kell jelentkezni
Szerintem a felelősség áthárítása nem egyenlő az adatbiztonság növekedésével.
Feltételezem nem ismered a szolgáltatód rendelkezéseit ez ügyben.
Még illúziónak is hamis olyan dologban bízni amiről nem tudsz semmit.
- A hozzászóláshoz be kell jelentkezni
Ismerem a szolgaltatom rendelkezeseit, megneztem, mielott szolgaltatot valasztottam. Roviden ok megoldjak, hogy az adataim biztonsagban legyenek, en ettol boldog vagyok. A mikentje meg nem erdekel.
--
|8]
- A hozzászóláshoz be kell jelentkezni
Mint amikor a gyerekem megígéri: Apa vigyázni fogok!
Osztán olykor-olykor csak becsúszik: Bocsi, apa!
Ez egy gyereknek elnézhető, egy szolgáltatónak kevésbé, de ettől még nem biztos, hogy nem fordul elő.
- A hozzászóláshoz be kell jelentkezni
Ha magam csinalnam, akkor se lenne jobb, csak tobb munkam lenne vele.
A kulonbseg annyi egyebkent, hogy a gyerek nem all veled szerzodesben, es nem fizet karteritest, ha megsem vigyaz elegge.
--
|8]
- A hozzászóláshoz be kell jelentkezni
OFF
Nyuszipapa a lányokkal való mókára tanítja a fiát három nyuszilányon bemutatva:
-Figyelj fiam, így kell ezt csinálni! Mögéállok, nekikészülődök, és aztán egy-két-há! Na most te jössz!
-Mögéállok... Nekikészülődök, és egy-két-há-négy... Bocs papa!
- A hozzászóláshoz be kell jelentkezni
Nem mindegy, hogy milyen hhd.
Valódi szerver kategóriában leírják a hibajelenségeket és gyakoriságukat, amikor cserélni kell.
Valamiért mindig kisebb a diszkek mérete a boltban kaphatóhoz képest, amikor pl. IBM szerverbe kerülnek.
Ez arra utal, hogy megbízható gépbe csak a kiforrott technológia kerülhet.
Ezen kívül az oprendszer is meghatározó: kezeli-e a hibákat, vagy nem.
- A hozzászóláshoz be kell jelentkezni
Egesz pontosan mennyivel kisebb?
--
zsebHUP-ot használok!
- A hozzászóláshoz be kell jelentkezni
-1"
:)
- A hozzászóláshoz be kell jelentkezni
Azért ez egy buta kérdés.
A válasz ugyanilyen: harmada.
- A hozzászóláshoz be kell jelentkezni
egyéb: három év után azonnal, amint van rá pénz.
- A hozzászóláshoz be kell jelentkezni
Kicsit szűkek a választási lehetőségek. Speciel érdekes lenne (szerintem), hogy a "Csak ha elromlik" lehetőségen belül hányan szavaztak ténylegesen arra, hogy csak akkor cserélnek, ha el is romlott, illetve hányan arra, hogy ha okot ad rá, de még nem romlott teljesen el.
---------------------------
���������������������������
- A hozzászóláshoz be kell jelentkezni
Rég láttam diszket teljesen megdögleni. Többnyire folyamatosan növekvő Reallocated_Sector_Ct ("kibaszkoggya a réd") vagy pörgő Raw_Read_Error_Rate-tel kísért belassulás a csere oka. A smart az esetek tizedében kerül FAILING_NOW állapotba.
- A hozzászóláshoz be kell jelentkezni
A kicsit nem jó az nem jó. :)
Nem csak a nagyon nem jó a nem jó. :)
- A hozzászóláshoz be kell jelentkezni
http://pastebin.com/GByXPtkL (home 'server') Ideje lenne aggódnom? :(
Kicsit off topic, de mi a legegyszerűbb módja annak, hogy ha gáz van automatikusan leállítsa és szóljon?
- A hozzászóláshoz be kell jelentkezni
Évente karbantartom a vinyót a következőképpen:
1. Kiszedem
2. Panelt lecsavarozom
3. Ami poros azt pormentesítem
5. Az érintkezőket kontaktspray-vel lepucolom, oxidmentesítem.
6. Panel vissza
7. Gépbe vissza...
6-8 éve húzzák az igát amiket így karbantartok, néhány gép közülük éjjel-nappal üzemel. 2-3 év alatt jól látható oxidréteg képes képződni az érintkezőkön, évenkénti pucolással ezt a hibalehetőséget kiküszöbölöm.
-fs-
Az olyan tárgyakat, amik képesek az mc futtatására, munkaeszköznek nevezzük.
/usr/lib/libasound.so --gágágágá --lilaliba
- A hozzászóláshoz be kell jelentkezni
Jaj... Bár a .sig alapján annyira nem csodálkozom :-P
- A hozzászóláshoz be kell jelentkezni
Az jó, itt van vagy 500 db diszk, két IT-s kollégára.
Max. arra van energiánk, hogy a szervereket monitorozzuk.
- A hozzászóláshoz be kell jelentkezni
Na ja... De azt is megnézném, hogy egy EMC/HP/IBM/satöbbi storage gyártója mit szólna egy ilyen "karbantartás"-hoz :-)
- A hozzászóláshoz be kell jelentkezni
Azok hobbicégek csak, ne keverd őket ide. :)
- A hozzászóláshoz be kell jelentkezni
Dell storage support-hoz rendszeresen van szerencsém, minőségben versenyeznek egy garázscéggel..de legalább kva drágák.
- A hozzászóláshoz be kell jelentkezni
Gondolom ezt otthon csinálod és nem a Googlenél vagy az Amazonnál. :)
- A hozzászóláshoz be kell jelentkezni
Nem csak otthon, melóhelyen is. 12 gép, gépenként 3-4 vinyó. Egy vinyó fent leírt karbantartási módja 5 perc. 4 vinyós gépnél időben:
gépház kipakolása: 2 min
gépoldal leszedése: 1 min
vinyók kiszedése:
- ha csavaros 4*2 min
- ha patentos 4*10 sec
a vinyóval végzett munka: 4x5 min
vinyók visszaépítése:
- ha csavaros 4*2 min
- ha patentos 4*10 sec
gépoldal vissza: 1 min
gépház vissza: 2 min
gépenként max. 45 perc alatt elvégezhető.
-fs-
Az olyan tárgyakat, amik képesek az mc futtatására, munkaeszköznek nevezzük.
/usr/lib/libasound.so --gágágágá --lilaliba
- A hozzászóláshoz be kell jelentkezni
Szolgáltatás addig áll?
Mert gondolom nem a hotswap raidből kapod ki a hdd-t. )
- A hozzászóláshoz be kell jelentkezni
Nem hiszem, hogy ezek szerverek lennének, szerintem workstation PC-kről beszél, azt meg egy éjszaka alatt végig is lehetne söpörni. Az, hogy érdemes-e egyáltalán, pedig egy másik történet.
- A hozzászóláshoz be kell jelentkezni
Workstationok, egy web-mail-ftp szerver, és egy routergép. 1-1.5 óra kiesés itt nem kritikus.
Hogy érdemes-e? Sokszor volt olyan, hogy egy vinyó motorja nem indult, vagy menet közben cincogott, stb... ezeket a hibákat az esetek 80%-ában kontakthiba okozta. 1 műszak alatt végig lehet szaladni az összes gépen, inkább akkor pucoljuk az érintkezőket, amikor nincs más fontosabb tennivaló, ne akkor jöjjön elő, amikor volna sokminden más. ( helyi TV, évente 1 hét leállás ütemezve )
Nem csak a vinyókat pucoljuk ilyenkor, hanem minden olyat, amit össze kell dugni (memória, proci, kártyák érintkezői). 2 évente a procikat is hűtőzsírozzuk.
-fs-
Az olyan tárgyakat, amik képesek az mc futtatására, munkaeszköznek nevezzük.
/usr/lib/libasound.so --gágágágá --lilaliba
- A hozzászóláshoz be kell jelentkezni
Tegyék hozzá, hogy a 12 gép/ember elég szerencsés felállás.
- A hozzászóláshoz be kell jelentkezni
Ezt teszi a szerver/nem szerver.
diszk lecsatolás: 1 min
diszk csere: 1 min
diszk felcsatolás: 1 min
(agyhalott operátort feltételzve, amikor minden parancsot el kell olvasni)
HA a szerver döglött be - mivel nincs cluster vagy virtualizáció
diszk 2db áthelyezés: 2 min
alkalmazás átkonfigurálása: 2 min
(elvárt képességek mint fent)
rendszer újrarakása új/tartalék gépre/diszkre: 20 min
Szerverenként 4-8 diszk, de általában soha nem kell cserélni.
Ez szerver környezetben. :)
- A hozzászóláshoz be kell jelentkezni
Én még azt hozzáteszem, hogy középen az elválasztásnál szétszedem, és a korongokat puha ruhával végigtörlöm.
:-P
(nem.)
- A hozzászóláshoz be kell jelentkezni
Én a tükrökön Clint használok.
--
zsebHUP-ot használok!
- A hozzászóláshoz be kell jelentkezni
Én meg kiveszem a tárcsát és tükörnek használom.
- A hozzászóláshoz be kell jelentkezni
Ha vannak rajta mikroforgácsok annak eltávolítására pedig tökéletes a mágnes. :)
- A hozzászóláshoz be kell jelentkezni