A váratlan leállások kiküszöbölésére számos technológiát dolgoztak ki az informatika története során, ezek közül az egyik széles körtben elterjedt a nagy megbízhatóságot biztosító fürtözés (high availability clustering). A legtöbb platformon elérhetők HA cluster megoldások, ilyen a HP ServiceGuard for Linux, amely a vállalat HP-UX UNIX-változatának fejlesztéséből táplálkozva, azonos kódbázisra épülve, üzleti kritikus feladatok futtatására alkalmas képességekkel ruházza fel a Linuxot és a rajta futó alkalmazásokat.
A HP már jó ideje kommunikálja Project Odyssey nevű programját, amelynek célja egy üzleti kritikus x86 szerver- és szoftverrendszer megalkotása a HP-UX operációs rendszer és az Integrity szerverek fejlesztése során megszerzett tapasztalatok felhasználásával. Ennek az erőfeszítésnek az egyik eleme a ServiceGuard for Linux is, amely szabványos x86 hardvereken és Linux környezetben biztosítja a futó alkalmazások gyors átterhelődését egy másodlagos szerverre.
A szoftver a felhasználó által kijelölt kritikus alkalmazásokat teljes vertikumként kezeli és monitorozza, vagyis nem csak magának az alkalmazásnak az életjeleit figyeli, hanem a kiszolgáló infrastruktúráét is, beleértve az operációs rendszert, virtualizációs réteget, hálózati stacket, a szervert és a tárolókat is. Amikor az alkalmazás futásában hiba lép fel, vagy valamelyik környezeti paraméter elér egy előre beállított értéket, a ServiceGuard for Linux automatikusan átmozgatja a futó alkalmazást a fürt másik csomópontjára.
A megoldás jellemzője, hogy kezeli a többrétegű alkalmazásokat (pl. adatbázis-köztesréteg-web) és az összetett infrastruktúrákat, ezeket is képes mozgatni és tekintettel van a komponensek leállítási vagy indítási sorrendjére is -- ezeket egy átlátható grafikus felhasználói felületen állíthatja össze a felhasználó.
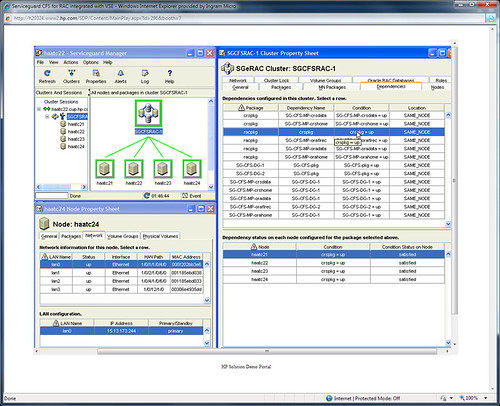
A HP ServiceGuard Manager for Linux szoftverben, amely a megoldás része, grafikus felületen tekinthető meg az üzleti kritikus alkalmazások környezete, ahol egy fürt telepítését, konfgurálását és működtetését változatos “varázslók” segítik, csökkentve a félrekonfigurálás és más emberi hibák kockázatait és egyszerűsítve az üzemeltető csapat dolgát. Áttekinthető a fürtök topológiája és komponensek közötti függőségek is jól láthatók, színkódokkal jelölt a fürtök és csomópontok állapota, a HP Systems Insight Managerrel vagy más felügyeleti megoldással történő integráció révén pedig a ServiceGuard Manager for Linux alkalmas a hardverek kezelésére is, egészen a diszkig.
A HP SGLX rendelkezik ún. Toolkitekkel és Extensionökkel, amelyek egy-egy szoftverhez vagy szoftverrendszerhez illeszkednek. Már elérhető például az NFS szerverekhez, az Oracle és Sybase adatbázisokhoz vagy például az SAP környezetekhez fejlesztett Toolkit, amely kimondottan ilyen megoldások rendelkezésre állását hivatott növelni: a ServiceGuard for SAP kiegészítéssel az SAP meghibásodása esetén a tartalék környezet 2-3 percen belül működőképes, míg nélküle akár órákig is eltarthat az SAP alkalmazásszíntű funkcionális átterhelése.
A HP-nak van ingyenes megoldása a népszerű nyílt forrású szervertermékek (Apache, NFS, MySQL, PostgreSQL, SAMBA, Tomcat, Sendmail) hibatűrő fürtözésére is, a Serviceguard Developer’s Toolbox pedig lehetővé teszi független szoftverfejlesztők számára, hogy saját alkalmazásukat integrálják a HP SGLX képességeivel. A HP ServiceGuard for Linux a VMWare környezetekkel is integrálható és a virtualizált környezet teljes alkalmazásszíntű biztonságát és az újraindulásoknál csak az alkalmazás újraindításának a sebességi előnyét nyújtja.
A HP ServiceGuard for Linux ingyenes próbaváltozata letölthető a HP weboldaláról.
(A HP megbízásából készített anyag.)
- A hozzászóláshoz be kell jelentkezni
- 4551 megtekintés
Hozzászólások
Egy HP szakértőt kérdeznék: mennyiben jobb, vagy másabb ez, mint a pacemaker? Már csak azért kérdezem, mert a HP cloud megoldása openstack alapú, és ők is pacemakert használnak a publikus felhőben. És ezt a megoldást akarják majd a cégek privát felhőinél is használni. Vagy ezt csak a szolgáltatásokra akarják adni?
- A hozzászóláshoz be kell jelentkezni
Szia,
A témával kapcsolatban volt egy előadásunk:
"A HP Cloud Services egy OpenStack alapú publikus felhő szolgáltatás. A Stackato egy ActiveState által fejlesztett és karbantartott platform-szolgáltatás (PaaS), amit a Cloud Foundry projektből forkoltak. Az OpenStack szolgáltatja az infrastruktúrát, Stackato pedig a platform és alkalmazás sablonokat. Ezen felül csak a saját kód és tartalom hozzáadása szükséges.
Mark Atwood,
Director of Open Source Evangelism for HP Cloud Services"
A HP mindíg igyekszik az adott környezeti igényekre szabni a megoldásait és ez dönti el, hogy mit javaslunk.
Ez a csomag bővült most a HP ServiceGuard for Linux megoldásokkal.
- A hozzászóláshoz be kell jelentkezni
Igen, ezt ismerem, a MeetUp-on is ott voltam, de én igazából arra lettem volna kíváncsi, hogy:
- miben más a ServiceGuard, mint a pacemaker
- mit láttok előnynek
- miben kell még fejlődnie amit a pacemaker tud, ez nem (nyilván semmiben, hiszen nem lehet ilyet írni egy kereskedelmi cég, kereskedelmi termékénél egy termékmenedzsernek, pre-sale engineernek nyivlános helyen, de egy próbát megér)
- A hozzászóláshoz be kell jelentkezni
Én nem értek hozzá (akkor meg minek írok ide, ugye), de meglepődnék, ha a ServiceGuardnak kéne felzárkóznia a Linux-HA-hoz. Két évtizedes UNIX múlttal rendelkezik, a codebase-t emelte most át a HP Linuxra.
Én a magam részéről megfordítanám a kérdést, mert míg a ServiceGuard jól dokumentált, addig nekem nehezemre esett bármi konkrétumot megtudni a Linux-HA képességeiről, történetesen hogy milyen részletesen monitoroz, milyen gyorsan tud failovert, milyen klaszter típusokat támogat, honnan lehet professzionális támogatást venni hozzá, hogyan támogatja az appok migrációját a klaszter felügyelet alá, mennyire egyszerű a használata.
Gyanítom egyébként, hogy a ServiceGuard elsősorban abban különbözik, hogy a HP mögé áll, és bizonyos támogatási és minőségi garanciákat vállal. Ennek megfelelően enterprise árazással dolgozik.
- A hozzászóláshoz be kell jelentkezni
OK, akkor nézzük tételesen:
- "meglepődnék, ha a ServiceGuardnak kéne felzárkóznia a Linux-HA-hoz": ez volt a kérdés, hogy miben jobb, miben tud kevesebbet, nyilván nem lehet minden mindenben jobb
- "Két évtizedes UNIX múlttal rendelkezik": a MÁV - elődeivel együtt - meg több, mint 150 éves, mégis jobban működik a GYSEV, ami meg csak 114 éves... és kicsit más a saját HP-UX-ra fejleszteni, mint egy másik kódbázisra
- "mert míg a ServiceGuard jól dokumentált, addig nekem nehezemre esett bármi konkrétumot megtudni a Linux-HA képességeiről": valószínűleg elkerülte a pacemaker oldalán a Documentation link alatt kb 230 oldal dokumentáció, melyben van részletes, minden parancsot és funkciót bemutató doksi, plusz külön egy példákkal illusztrált, csupán 94 oldalas dokumentáció... khm. ÉS ez különböző verziókhoz mind fent van, pdf, html, single-page html oldalon
- dokumentáció terén a SUSE EL-hez, és a RH-hoz szintén több száz oldal dokumentáció van, Susenál a resource agentekről egy külön referencia... elismerem, az oldal nem érzékeli automatikusan, hogy te most doksit keresel, rá kell kattintani a linkre, stb. ez most irónia volt, de a biztonság kedvéért ide írom :)
- "Gyanítom egyébként, hogy a ServiceGuard elsősorban abban különbözik, hogy a HP mögé áll, és bizonyos támogatási és minőségi garanciákat vállal." - ahogy a SUSE és RH is, a saját termékére.
A megbízhatóságról pedig az egyik legnagyobb referencia:
"Can I relay on pacemaker?"
"If you've flown in Europe in the last few years, chances are you already have.
Deutsche Flugsicherung GmbH (DFS) uses Pacemaker with Heartbeat to ensure its air traffic control systems are always available."
DFS trusts Pacemaker with peoples' lives, so can you."
- A hozzászóláshoz be kell jelentkezni
Azert a typot sikerult atmasolni. Relayezni szerintem nem lehet a pacemakerrel, akarmilyen okos cucc. Ellenben megbizni benne, szamitani ra (rely) annal inkabb.
--
Ki oda vagyik, hol szall a galamb, elszalasztja a kincset itt alant. | Gentoo Portal - A hozzászóláshoz be kell jelentkezni
Fel sem tűnt, az agy automatikusan javítja. Viszont tényleg gáz, hogy így van kiírva. Teljesen más jelentéssel :-/
- A hozzászóláshoz be kell jelentkezni
Csak a rend kedvéért, a Google-ön a "linux high availability documentation" keresésre az első 5 link között az alábbiakat találom:
http://www.clusterlabs.org/doc/
https://www.suse.com/documentation/sle_ha/pdfdoc/book_sleha/book_sleha…
Utóbbi 480 oldal... ennyit a rosszul dokumentáltságról... thumbs down...
- A hozzászóláshoz be kell jelentkezni
nem tudom minek ez a passzív agresszív attitűd, biztos csak rég hupoztam és elszoktam a stílustól.
alapvetően nem ilyen technikai dokumentációra gondoltam, és nem a kereskedelmi disztribúciók által szállított megoldásokról, hiszen nem is azt kérdezted, hanem a pacemaker/linux-ha kód képességeit. a sles és rhel HA képességei sem azonosak, akkor sem, ha mindkettő linux-HA-ra épül. rhel pl. nem kínál a menedzsmentbe integrált DR-t tudtommal, míg a sles igen.
a HP alapvetően egyszerűbben és gyorsabban bevezethetőnek, könnyebben használhatónak tartja az SG-t az RHEL/SLES megoldásoknál, beleértve a DR beállítását, magasabb adatintegritási garanciával és a klaszter online frissítésének lehetőségével. ezek nem igazán kemény, tényszerű különbségek.
az tényszerű, hogy disztribúciótól független, vagyis nagyobb infrastruktúrában többbféle linuxszal ugyanazt a HA megoldást tudod használni, pláne ha még HP-UX is van. az is előny lehet, hogy a hp rendszermenedzsment eszközökkel is integrált.
de csak most esik le hogy valójában szofisztikált trollkodásnak ültem fel.
- A hozzászóláshoz be kell jelentkezni
Aha, szóval troll lettem, mert tételesen írtam arra, amit írtál. Fura egy hozzáállás hallod :)
Ha feature lista kell, az is ott van, de ugye volt egy felvetés, hogy nem találtál erről semmilyen infót... megjegyzem, hogy a hosszú doksik elején is van egy általános ismertető, hogy mire jó, mit tud, mit nem tud. A nem SLES és RH doksi általános érvényű, a pacemaker benne van minden disztribben, tehát mind a dokumentáció, mind a megvalósítások elég jól implementálhatóak tetszőleges(!) linux rendszeren.
Attól függetlenül, hogy nem értesz hozzá, és nem vagy érdekelt a HP megoldásokban, elég szép marketing szagú hozzászólásaid vannak... az értékes válaszokat meg trollkodásnak írod.. végül is ,ha hitelteleníteni kell valakit, az erre jó mód, ha rákenjük, amit mi csinálunk... és én vagyok a troll... lefosom a bokám.
A fenti szöveg olyan szép marketing, mintha egy prospektusból lett volna kivágva.
Az egyetlen jól illő dolog benne, az az, hogy valószínűleg gyorsan belepasszol a HP menedzsment rendszerébe, ha rendelkezel ilyennel.
De akkor, hogy "trollkodjak", adok megint egy linket, és rövid idézetet amiben feature szinten látod a tudását:
http://clusterlabs.org/#info
Features
Detection and recovery of machine and application-level failures
Supports practically any redundancy configuration
Supports both quorate and resource-driven clusters
Configurable strategies for dealing with quorum loss (when multiple machines fail)
Supports application startup/shutdown ordering, regardless machine(s) the applications are on
Supports applications that must/must-not run on the same machine
Supports applications which need to be active on multiple machines
Supports applications with multiple modes (eg. master/slave)
Provably correct response to any failure or cluster state.
The cluster's response to any stimuli can be tested offline before the condition exists
Az, hogy mennyire megbízható a fejlődés, mennyire biztos a fejlesztése:
"The core Pacemaker team is made up of full-time developers from Australia, USA, Austria, Germany, and China. Contributions to the code or documentation are always welcome." "Pacemaker has been around since 2004 and is primarily a collaborative effort between Red Hat and Novell, however we also receive considerable help and support from the folks at LinBit and the community in general."
Most már nem igazán lehet kifogásod, hogy nem tudsz mindent. És ezt körülbelül 2 perc guglizással meg lehetett találni. Onnan tudom, hogy mikor elkezdtem klaszterekkel foglalkozni, akkor valahogy rögtön rátaláltam mindenre. Általános összefoglalóra, amiből látszott, hogy jó lesz ez nekem, és referenciára, ami alapján meg az utolsó eldugott opcióról is megtudtam, hogy mi az, és ezen felül egy gyorsan olvasható és kipróbálható, valós példákkal, ábrákkal illusztrált lépésről lépésre kezdeti dokumentációt is "kaptam".
Összefoglalva: az tényszerű, hogy a a pacemaker disztribúciótól független, vagyis nagyobb infrastruktúrában többféle linuxszal ugyanazt a HA megoldást tudod használni. Remélem pontosan idéztem. A HP menedzsment eszköz integráció nem működik, az is tény :)
Zárszóként: Amennyiben a kulturált választ, és a trollkodást nem tudod megkülönböztetni, nem akarod, vagy szándékosan a másikra mondod a trollt, miközben fals tényeket közölsz, majd elferdíted a válaszok célját, és közben tolsz egy marketinget a termékről, akkor nekem kicsit hiteltelen vagy, mint "kívülálló".
- A hozzászóláshoz be kell jelentkezni
Azert te is egy kicsit megmarketingelted a Pacemakert... Csak nem a ClusterLabs emberet tisztelhetjuk szemelyedben? :D
--
Ki oda vagyik, hol szall a galamb, elszalasztja a kincset itt alant. | Gentoo Portal - A hozzászóláshoz be kell jelentkezni
Csak küzd a marketing hazugságok ellen.
- A hozzászóláshoz be kell jelentkezni
Azt bem mondanám, hogy hazudnak. A HP SGt nem ismerem, így jogom sincs nyilatkozni, hogy mit tud. Valójában, nem papíron.
Ami miatt válaszoltam az viszont a pacemaker rossz hírének keltése és az a csúsztatás, vagy inkább fals infó, hogy nem lehet featuret és doksit találni könnyen a linuxon elérhető klaszter megoldásokról. A lényeg, hogy az egyik legjobban dokumentált rendszer, és nem csak az open source közősségen belül
- A hozzászóláshoz be kell jelentkezni
Ertettem en elsore is. Kollega nem vette eszre a smileyt a vegen.
--
Ki oda vagyik, hol szall a galamb, elszalasztja a kincset itt alant. | Gentoo Portal - A hozzászóláshoz be kell jelentkezni
Én meg neki is válaszoltam :)
Abban igaza van, hogy tényleg egy marketing zuhany jött a hozzászólásban, a "20 éves unixos múlt", mint mindent ütő érv, és az, hogy nem lehet linuxos clusterről infót találni.. cöcöcö. Aztán a válasz sem tetszett, nyilván, mert cáfolat volt. Viszont azért szándékos hazugságról sem beszélnék, bár elég homályos volt az, hogy először nem értenek hozzá, majd egy teljes támogatói nyilatkozatnak megfelelő szöveget írt be, de kb úgy, mint aki használja. Vagy csak copy&paste volt, és mindent elhisz a hozzászóló. Viszont ezt nem tisztem eldönteni, ezért nem is mondanám, hogy szándékos volt. Teljesen ne lássunk rosszat a másikban, mert akkor mindenhol csak gond lesz, soha semmi nem lesz jó, és ezzel magunknak ártunk. Ha meg tényleg direkt marketinges dolog volt, akkor pukkadjon meg :)
- A hozzászóláshoz be kell jelentkezni
Előrebocsájtom, hogy én a pacemakert nem ismerem, egy clustert építettem még csak ennek használatával (amennyiben ezen alapul a SuSE saját clustere). Serviceguardot több mint egy évtizede használok, igaz elsősorban HP-UX-on. Ezért a két terméket nem hasonlítanám össze, inkább leírom, miért találom jónak a Serviceguardot:
Az SG alapvetően egyszerű mint a bot. Egy szolgáltatást akarsz nyújtani, ehhez pedig erőforrásokra van szükséged (adatterület, hálózat, alkalmazás). Ezeket egy csomagban összegyűjtöd és meghatározod, a cluster mely tagjain képes futni. Felállítasz ezek közt egy sorrendet és elindítod a csomagot. Az aktiválja a tárterületet, felkonfigurálja az IP címét, elindítja az alkalmazást. Egy clusterben több ilyen csomag is futhat, bármelyik node-on, amelyik képes azt futtatni. Így egyik node-nak sem kell üresjáratban állnia. Ha egy szolgáltatás nyújtását valami akadályozza - mely nem hárítható el helyben, automatikusan - az SG azt elindítja egy másik node-on, figyelve arra, nehogy több helyen fusson ugyanaz a szolgáltatás. Ez lényeges, az adatok védelme fontosabb mint a szolgáltatás biztosítása.
A valóság ennél természetesen összetettebb, de szerintem a lényeg a fentiekben van.
Az SG egyszerűsége biztosítja a megbízhatóságát, tizenhét év alatt - melyből tizenkettőt szervizesként töltöttem - egyszer nem találkoztam olyan esettel, ahol adatok sérültek az SG hibájából.
Ave, Saabi.
- A hozzászóláshoz be kell jelentkezni
thumbs up
- A hozzászóláshoz be kell jelentkezni
Ez így működik pacemaker alatt is, a különbség, hogy itt resourceok vannak, nem package-k, és nem egy csomagba rakod, hanem colocationt képzel közöttük, alakíthatsz ki sorrendiséget, konfliktusskat különöbző resourceok között, mikor, melyik gépre kerülhet, és milyen feltételek mellett. Szerk.: és lehet csoportokat is alkotni, ezen belül is ordereket, gondolom ez felel meg a packagenak.
Ezeket a dolgokat kb 20 éve, vagy még régebben kitalálták már, a Digital idejében is, amit megvett a Compaq, abból jött létre többek között termékként a Compaq non-stop cluster is, meg más cluster termékek - azért nem teljesen ez, de ott már volt olyan, mint a vmware-ben a Fault Tolerance, csak nagyon drága eszközök kellettek hozzá és SCO unixon ment csak előszőr-, amiből lett HP megoldás, és sok dolog beépült a HP megoldásokba, vagy lecserélte azokat. Ezzel nincs is baj, mindössze azt akarja jelenteni, hogy az alapokat már jó pár éve, évtizede lerakták.
A SLES és RHEL ad grafikus konzolt ehhez, más disztribúciók nem, de ott meg van lehetőség az LCMC nevű eszközt használni, aminek én nem vagyok olyan nagy barátja - javas - de használható eszközzé fejlődött, és akinek ezt odaadtam, valamint egy nap alatt átnéztük a pacemaker főbb lehetőségeit, már önmaga felügyeli a szolgáltatásokat, állít be újakat, és csodálatos módon a dokumentációt is megtalálta - a segítségem nélkül, már a projekt indítása előtt.
- A hozzászóláshoz be kell jelentkezni
Nem tudom ki hogy van vele, de ezt a tradícionális HA clustert shared storage-on (azt tükrözve mindenféle DWDM-eken, meg másokon át a világba, hozzá húzva a L2 etherneteket metro szinten) mindig is oltári nagy kendácsolásnak tartottam.
Ha hasonlatot kellene hoznom, a fogyasztó tablettákat említeném. Vannak a túlsúlyos emberek, akik futtatnak redundáns működésre képtelen szoftvereket, és várják a gyógyszergyártóktól a tablettát, amit ha bevesznek, munka nélkül megoldja a gondjukat.
Ahelyett, hogy elkezdenének futni, mozogni, olyan alkalmazásokat építeni, amelyek nem arra a koncepcióra épülnek, hogy az alattuk lévő erőforrások (storage, network, gép) mindig elérhetőek lesznek.
Ez nem a state of the art, ez a state of the XIX. század. A SG-ot ugye lyukkártyán kell konfigurálni?
--
zsebHUP-ot használok!
- A hozzászóláshoz be kell jelentkezni
Azért a kép ennél árnyaltabb. Nyilván az átlagostól magasabb rendelkezésre állást várnak, és ezért használják ezt a megoldást, a szoftvert sem úgy írják meg,hogy majd valami jól megoldja a rendelkezésre állást. Amennyiben ez valami webszervíz, akkor a rendelkezésre állást terheléselosztással tudod kombinálni.
Azért a vas is kieshet, akkor mi van? Elszáll mind a két táp, vagy egy van benne, stb.
Akkor elindul egy másik gépen. Ha akarod, akkor több példányban is futhat, load balance megoldásként, és akkor egy ideig kap plusz terhelést az egyik gép, aztán közben elindul egy harmadikon a leállt második webszerver.
Olyan helyeken, ahol adatírás van, adatműveletek, pl SQL, ott ez természetesen nem megengedhető, ott az alkalmazásnak kell supportálni ezt. De ott is szükség van ilyen "barkács" megoldásra, mert ha valódi multi-master megoldásból kiesik egy szolgáltatás, nem árt újraindítani azt.
Mindent tudni kell a helyén kezelni.
De kíváncsivá tettél, hogy mi lenne a XXI-ik századi megoldás :)
- A hozzászóláshoz be kell jelentkezni
Vannak szép számmal olyan alkalmazások is, amik alkalmazás szinten oldják meg a redundanciát.
És millió egy, ami nem, és esély sincs rá, hogy alkalmazás szinten belefejlesztik.
A HA cluster+shared storage megközelítéssel biztosítani lehet gyakorlatilag bármilyen szolgáltatás nagyobb rendelkezésre állását.
A másik:
Egy adott cluster megoldás egységes keretet ad a rajta futó alkalmazások HA környezetének biztosítására. Gondolom láttál már pár HA cluster support mátrixot - van pár specifikáció, amit be kell tartani egy ilyen építésekor.
Ha minden szoftver alkalmazás alapon oldaná meg a HA működést, akkor jó eséllyel ahány alkalmazás, annyi specifikáció, és műszaki követelmény.
A harmadik:
A virtualizáció és a cloud korát éljük, ahol a magas rendelkezésre állást a virtualizációs platform adja. (Vagy legalábbis a legtöbb gyártó azt tolja.) Egy jól összerakott virtualizációs platformon felesleges még az alkalmazások HA tudásába is pénzt ölni.
- A hozzászóláshoz be kell jelentkezni
"A virtualizáció és a cloud korát éljük, ahol a magas rendelkezésre állást a virtualizációs platform adja. (Vagy legalábbis a legtöbb gyártó azt tolja.) Egy jól összerakott virtualizációs platformon felesleges még az alkalmazások HA tudásába is pénzt ölni."
- Az adatbiztonság meg smafu??? Meg a tranzakciók? Nem véletlenül akar a Canonical is natív master-master mysql replikációt.
- A hozzászóláshoz be kell jelentkezni
Félreértesz.
Nem feltétlen kell minden alkalmazást HA képességekkel felruházni, mert a redundanciát a platform biztosítani tudja.
Az adatbiztonság nem tudom hogy jön ide. Nagyon sok nagy cégnél a meglévő szirszar vasakat tucatjával tolják virtualizált infrastruktúrába. (Nem feltétlen public cloudra gondoltam.)
A master-master nem HA.
Nyilván vannak olyan alkalmazások, ahol az elosztott tranzakció kezelési igény és konzisztencia miatt nem megfelelő egy HA cluster. De sok alkalmazás esetében nem indokolt mindegyiket replikációs képességgel felruházni, és elegendő egy jó HA keretbe beletolni.
Sok, "enterspájz" környezetbe fejlesztett egyedi alkalmazásnál az is nagy teljesítmény, ha képes a fejlesztő így-úgy működő kódot generálni. Ha még replikálni is kéne, akkor ötször annyiba kerülne, és soha nem működne normálisan. (sarkított vélemény, de túl sok enterspájz szemetet láttam már).
Egy master-master jellegű adatbázis mellé egy olyan alkalmazást is rakni kell, ami tudja is normálisan használni. Láttam már olyan parallel oracle-re épülő (valószínűleg) drága alkalmazást, ahol az egyik node leállása esetén az érintett kliens konfig fájljában át kellett írni a db szerver címét, és újra kellett indítani. (Köpni nyelni nem tudtam.)
Összegzésként: egy Ha cluster egy álltalános és relative olcsó megoldás, hogy olyan alkalmazásoknak is legyen nagyobb rendelkezésre állása, amiknél nem éri meg vagy nem lehet alkalmazás oldalról biztosítani a redundanciát.
- A hozzászóláshoz be kell jelentkezni
senki nem vitatta, hogy sok alkalmazásnak jól. elbeszélsz mellettem. én azt mondtam, hogy sql db esetén ez nem jó megoldás, ha adatbiztonság kell, integritás, folyamatos elérés. fentebb található hozzászólásomban hivatkoztam a webszerverre, ami jól veszi a HA akadályt. és még jó pár másik alkalmazás van, gyakorlatilag majdnem minden, ami nem sql db, bármilyen.
A master-master megoldás nekem eléggé HA-nak tűnik.... csak jól kell implementálni, nem a mysql típusú barkácsolás szintjén.
- A hozzászóláshoz be kell jelentkezni
"A master-master megoldás nekem eléggé HA-nak tűnik.... "
HA-nak leginkább az olyan megoldásokat nevezik, ahol az elsődleges node elpatkolása esetén az alkalmazás (utomatikusan) a túlélő node-on újraindul
HA-ban álltalában ugyanazt az adatterületet látja vagy képes látni az összes node.
A master-master ezzel szemben egy elosztott/párhuzamos rendszer. Tény, hogy magas rendelkezésre állású, de a HA az leginkább egy technológiai elnevezés.
- A hozzászóláshoz be kell jelentkezni
amiről te beszélsz, az a failover HA. Csak a pontosítás véget. A magas rendelkezésre állású bármi az HA.
- A hozzászóláshoz be kell jelentkezni
Sziasztok !
Birnbauer Péter vagyok a Hewlett-Packard képviseletében.
Minden a cikkel kapcsolatos kérdésre, kommentre szívesen reagálok.
A túl mély technikai kérdésekre megpróbálom kollégáimtól begyűjteni a válaszokat
...és a lehetőségeinkhez mérten megpróbálom ezt időben tenni...
- A hozzászóláshoz be kell jelentkezni
Alakul ez. Kicsit még marketingszagú, de legalább szakmai, támogatott cikk, a kommentekben szakértő válaszol a kérdésekre. Tetszik.
- A hozzászóláshoz be kell jelentkezni
Errol a mysql hibaturo furtozesrol lehetne egy kicsit tobbet megtudni? Egyik ugyfelunknel pont ezzel kuzdunk, van egy mysql-re fejlesztett rendszeruk (windowson futo kliensprogramokkal, tehat NEM web-es!) amit jo lenne HA-ve tenni. Jelenleg master-slave replikacio van, a master-master nem megy mivel az alkalmazas nincs erre felkeszitve (elofordul hogy ugyanazt a rekordot piszkalja tobb kliens egyidoben). Van erre is megoldasotok, vagy csak a mar mukodo master-master felallasnal mukodik mint terheleseloszto?
A'rpi
- A hozzászóláshoz be kell jelentkezni
A master-slave replikáció olyan mint az oracle dataguard? Magyarán két adatbázis van, az egyiken dolgoznak, a másik meg követi az események alakulását?
Serviceguard esetében egyetlen adatbázisról beszélünk, mely alaphelyzetben az ő default serverén fut. Failover esetén az SG elindítja a másik - vagy harmadik, negyedik, etc... - node-on. Az eléréséhez használt IP cím változatlan marad, mivel az a többi erőforrással együtt vándorol a node-ok között.
Egy szolgáltatás nyújtásához szükséges erőforrások összességét hívjuk SG esetén package-nek - csomagnak a csak magyarul értők kedvéért - mely egyszerre egy node-on futhat. Egy clusterben több package lehetséges és ezeket - konfigurációtól függően - bármelyik node képes futtatni.
Ha jól értem, hogyan épül fel egy mysql master-slave konfiguráció, úgy az SG ehhez úgy viszonyul, hogy a master a szolgáltatás kiesésekor elindulhat egy másik serveren, nem szükséges átállni a slave-re. Ez feltételezem rövidebb kiesést eredményez mint az átállás a slave adatbázisra, illetve nem szükséges megtervezni a visszaállást. Mivel a mysql-t nem ismerem, a fentiek azon a feltételezésen alapulnak, hogy a master-slave konfiguráció olyan mint az oracle-nél a standby adatbázis archive logokból történő folyamatos frissítése.
Ave, Saabi.
- A hozzászóláshoz be kell jelentkezni
> A master-slave replikáció olyan mint az oracle dataguard?
az nem tudom milyen :)
> Magyarán két adatbázis van, az egyiken dolgoznak, a másik meg követi az események alakulását?
igy van. a master folyamatosan kuldi a tranzakciokat a slave-nek ami szinten vegrehajtja, igy elvileg mindig szinkronban vannak. ha a master megall, akkor most kezzel kell a slave-t masterba kapcsolni, atirni az ip-jet a masterere (miutan gondoskodtunk rola, hogy a regi master nehogy visszajojjon, pl gep kikapcs :))
> Failover esetén az SG elindítja a másik - vagy harmadik, negyedik, etc... - node-on.
na de hogy kerulnek at a masik node-ra az adatok? ha meg azon mar fut slave-ben a mysql akkor nem elinditani kell a mysql-t hanem atkonfigolni...
shared storage sem nagyon jo megoldas, hacsak nincs egy dual controlleres fc-s san alatta, akkor eleg lassu lenne :(
(sok giga db-rol beszelunk ami eleg gyorsan valtozik)
A'rpi
- A hozzászóláshoz be kell jelentkezni
"na de hogy kerulnek at a masik node-ra az adatok? ha meg azon mar fut slave-ben a mysql akkor nem elinditani kell a mysql-t hanem atkonfigolni..."
Ezek a failover megoldások tipikusan shared storage-ra lettek kitalálva.
- A hozzászóláshoz be kell jelentkezni
Így van, az SG shared storage-re van kitalálva.
Ave, Saabi.
- A hozzászóláshoz be kell jelentkezni
Nektek jo lehet az MMM fele multimaster is. Ez arrol szol, hogy a szerverek folyamatosan masterkent uzemelnek, viszont van egy virtualis IP, ami mindig az _aktualis_ masternel van. Ha az aktualis master meghal, akkor mindenfele varazslat nelkul a virtual IP atmasz a tartalek masterre. Igy nem kell az appnak felkeszulve lenni a multimaster kornyezetre, mert valojaban mindenki a virtual IP-t tolja adatokkal. Nem teljesen transzparens az atvaltas, van egy nagyon pici kieses, de nem szamottevo. De meg talan ezt is meg lehet oldani, ha a virtual IP ele felhuzol egy mysql proxyt, az talan kepes transzparensse tenni a failover folyamatat. Akkor meg a kapcsolat megszakadasat se kell az appnak erzekelni.
Ja, es gratisz, hogy a passziv master readonly lesz automatikusan. Tehat oda ha akarsz se tudsz irni. Viszont nagyszeruen lehet belole olvasni, ami peldaul statisztikazashoz jol johet. Okos cucc nagyon.
--
Ki oda vagyik, hol szall a galamb, elszalasztja a kincset itt alant. | Gentoo Portal - A hozzászóláshoz be kell jelentkezni
Erről Florian Haas annyit mondott, hogy messzire kerülendő.
Neki hajlamos vagyok hinni klaszter és HA kérdésekben.
- A hozzászóláshoz be kell jelentkezni
Es meg is indokolta?
Amit egyebkent Arpi leirt, az egy valid use case, es szerintem felesleges ra pacemakert meg hasonlokat rapakolni, hiszen vegulis ketto darab, ugymond irodai MySQL-rol beszelunk, tehat igazabol az sem gond, ha megall, de inkabb ne alljon meg. Ilyen megkozelitesbol viszont a problemara az MMM tokeletes megoldas lehet. A beszakado tranzakciok nyilvan beszakadnak, de azok pacemakerrel is beszakadnak, szoval azt mindenkepp app oldalon kell kezelni.
Raadasul szerintem az MMM-et sokkal egyszerubb is konfigolni, aki mar latott MySQL konfigot, az ezt is be fogja konfigolni, anelkul is akar, hogy tudna, mi az a HA. Kell egy fulladmin user mindket node-on, aminek a neveben az mmm-agent belep, es kb. ennyi. Az mmm-manager meg szinte barhol futhat, nulla terhelese van (monitoringot vegez csak).
Nem kampanyolni akarok az MMM mellett, csak szerintem egyszerubb feladatokra alkalmas lehet. Minden masra ott a pacamekar.
--
Ki oda vagyik, hol szall a galamb, elszalasztja a kincset itt alant. | Gentoo Portal - A hozzászóláshoz be kell jelentkezni
Az asszinkron replikálás minden baj forrása MMM-nél. Nem az épp futó tranzakció beszakadása a baj, hiszen azt egyébként is kezelni kell, hanem az, hogy a már sikeresen lefutott tranzakciód sincs biztonságban failover esetén. Minél nagyobb a replikációs lag, annál több tranzakció veszhet el. Ha a régi node visszajön egy reboot után, akkor az eltűnt tranzakciók újra megjelennek, ami könnyen inkonzisztenssé teheti az adatbázist és erre app oldalról nehéz felkészülni.
A gyakorlatban az a baj, hogy a túlterhelés egyrészt replikációs lagot, másrészt failovert triggerelhet, ez a kettő együtt pedig épp az, amiben az MMM rossz. Mondjuk épp ez az, ami irodai környezetben nem játszik.
- A hozzászóláshoz be kell jelentkezni
Igen, es pont ezert ajanlottam a kolleganak a cuccost. Noha a replikacios lag eszembe se jutott, az viszont igen, hogy egy valodi HA MySQL eseteben ugymond megelozo csapasra is szukseg lehet a teljesitmenyparameterek monitorozasaval.
--
Ki oda vagyik, hol szall a galamb, elszalasztja a kincset itt alant. | Gentoo Portal - A hozzászóláshoz be kell jelentkezni
Amire választ kaptál, hogy ez is csak azt tudja, hogy ha meghal a node, vagy a szolgáltatás a szerveren, akkor egy másik node-on, egy start metódussal elindítja a felügyelt szolgáltatást a rendszer, átrángatja a virtualIP-t, stb.. Pacemaker is ezt csinálja, és nem gondolnám, hogy a HP SG is csodát tudna tenni, ez a mysql belső lelki élete.
Az adatok egy shared storageon vannak, így csak az utolsó updateket veszíted el, de ezt meg le kellene kezelnie a rendszernek.
Ez inkább ilyesmi: http://www.mysql.com/products/cluster/ , de ezzel nincs tapasztalatom. A hétvégén említett cég egy korábbi verzióval - még SUN-os mysql időkből - találkozott ezzel.
A GPL-es verzió itt van:
http://www.mysql.com/downloads/cluster/
ne kérdezd meg mit tud :)
- A hozzászóláshoz be kell jelentkezni
A mysql cluster egy shared-nothing in-memory adatbazis, aminek majdnem 0 koze van a mysqlhez, csak rossz a neve. A mysql maga itt csak egy frontend, a fontos dolog benne az ndbcluster storage engine. Ez a kozhihedelemmel ellentetben nem egy altalanos celu adatbaziskezelo, annak ellenere, hogy mysql wire protokollt (is) tud beszelni.
MySQL HA state of the art:
- Percona XtraDB Cluster (vagy barmi, ami galeran alapul)
- Percona Replication Manager (mysql replikaciohoz ez a hivatalos resource agent pacemakerben)
- MHA
Ezeknek vannak kulonbozo elonyeik/hatranyaik, siman shared storage-en, drbd-n mysqlt nem szokas hasznalni, mert nagy innodb log fileok eseten a failover a masik gepre sokaig tarthat az instance recovery miatt. Az arpi_esp altal emlitett multi master megoldast nem feltetlenul kell az alkalmazasnak tamogatnia, ha eleg csak az egyik nodeot irni (a replikaciot managelo cluster framework meg eldonti, hogy melyiket irja). Ha minde a kettot irod nem lesz gyorsabb, sot.
MySQL-ben a durability konfiguralhato, te dontheted el, hogy mennyi tranzakcio elveszteset toleralod milyen korulmenyek kozott (cserebe nyilvan irasi teljesitmenynovekedest kapsz).
- A hozzászóláshoz be kell jelentkezni
szóval akkor az még mindig az in memory dolog, teljes egészében, ahogy régen volt. Én nem foglalkozom vele, valaki mondta, hogy újraírják.
Hallottam olyan _pletykát_ egy félmegjegyzésből Canonical-os emberektől, hogy készül egy valós Mysql master-master megoldás, de nem a kulcsokat a db-k számával növeljük, hanem valós, valódi konfliktuskezeléssel rendelkező megoldás. Gondolom az openstack miatt, ami a cloud megoldásuk alapja, és imádják mysql-ben tárolni az openstack konfigokat - mondjuk 2-3-400 gép esetén, és mondjuk 200 user felett már biztos jobb, mint az sqlite, főleg, ha nem egy központi gépen akarnak tartani mindent a nova nodeokon kívül.
- A hozzászóláshoz be kell jelentkezni
Az XtraDB cluster teljesiti a pletykakat, de amit irsz az nagyon kodos :) A mysql cluster nagyon sokat fejlodott az utobbi idoben, egyre inkabb kozebb van az altalanos celusaghoz, de nem az.
- A hozzászóláshoz be kell jelentkezni
nekem is ködös, többet nem mondtak :) lehet, hogy az xtradb-s kód visszatételén dolgoznak, nem tudom... de lehet, hogy teljesen új. Ez csak úgy hirtelen kicsúszott előadás közben az egyik előadó száján, aztán gyorsan másra terelődött a szó, igazából folytatta a megkezdett témát.
- A hozzászóláshoz be kell jelentkezni
A master-master replikációval nincs gond, ha nem várunk csodát tőle és nem loadbalancer-a használják. Az (nagyjából) remekül működik, hogy 2 darab master van és CARP-pal egy virtuális IP-vel oldom meg az IP-t. Ami ilyenkor problémás az az aktuális éles node halálakor elvesző tranzakció és a TCP kapcsolat nullázódása. Sima két gépes megoldásnál talán még MySQL proxyval lehetne okoskodni, hogy egyszerre mindkét gépre leküldi ugyanazt a tranzakciót, ha tud ilyet. Minden esetre a két gép+shared storage (ugye lesz plusz storage is backupnak...) opciónál olcsóbb a kétgépes történet.
- A hozzászóláshoz be kell jelentkezni
A MySQL-hez keszult egy sajat ilyesmi megoldas, virtualis IP-kkel, minden kutyafulevel, a legtobb disztroban benne van, es mysql-szeru konfigokkal dolgozik. http://mysql-mmm.org.
Kicsit jatszottam is vele, nagyon korrekt megoldas, nyilvan az IP vandorllast a kapcsolatok megsinylik, as usual, de egyeb szempontbol akarmi tortent az aktiv node-dal, pillanatokon belul a passziv volt az aktiv. Kicsit feljebb irtam is rola.
--
Ki oda vagyik, hol szall a galamb, elszalasztja a kincset itt alant. | Gentoo Portal - A hozzászóláshoz be kell jelentkezni
Az MMM annyira 2011 (tudom, azt mondani, hogy valami annyira 2000 valamennyi meg annyira 2007). A PRM (Percona Replication Manager) azert keszult, hogy az MMM gyengesegeit megoldja. A PRM az ujabb pacemaker verziokban mar a default resource agent mysqlhez.
- A hozzászóláshoz be kell jelentkezni
Siman lehet a master-master mysql-t is loadbalancolni :).
--
"ssh in a for loop is not a solution" – Luke Kanies, Puppet developer
- A hozzászóláshoz be kell jelentkezni
Shared storage és rajta InnoDB (nagy overhead, lassú failover) vagy nézzétek meg 5.5-ben a félszinkron replikálást (kis overhead, gyors failover). Persze ez utóbbi sem arra való, hogy loadbalance-olj, csak garanciákat ad a replikálás mellé.
- A hozzászóláshoz be kell jelentkezni
nemide.
- A hozzászóláshoz be kell jelentkezni
Van rendes volume manager tamogatas? ( hitachi / vxvm ), vagy itt is scriptek vannak, ill. lehetseges az md/lvm bohockodas is?
Amugy a HP ne tartson eloadast a megbizhatosagrol, ha kinyirta a pa-riscet es gyilkolja a hp-ux -ot...
- A hozzászóláshoz be kell jelentkezni
LVM-re épül. A VxVM-et most nem tudom (a nagy tesója HP-UX-on tudja, tehát valszeg vagy már most is tudja itt, vagy fogja hamarost), de az md-t nem tudom hogy jött a képbe, én azt nem tekintem volume management eszköznek.
A PA-RISC-cel egyetértek, a HP-UX-ot a Zorákulum próbálja kinyírni, azt azért lássuk be.
- A hozzászóláshoz be kell jelentkezni
Hivatalos anyagban szerepel a VxVM támogatás, megnyugodhatsz. (Valami ilyesmi szerepel: Linux LVM2, VxVM és CLVM.)
- A hozzászóláshoz be kell jelentkezni
Egy hódmezővásárhelyi társasházban, egy Debian szerver, 708 napja megy újraindítás nélkül,két feladata van, megosztja a netet, valamint fájl kiszolgálóként működik.
Remélem meg lesz az 1000 nap :)
- A hozzászóláshoz be kell jelentkezni
Pont ez a lényege a HA-nak: a remélem szó ott eléggé ritkán az egyetlen megoldás az 1000 nap elérésére :D
- A hozzászóláshoz be kell jelentkezni