Sziasztok, nem vagyok szaki, hobbi projektem ez. Van 2 darab elfekvő gépem, 8gb memória és 4 mag, több 300,500,1000gb Hddvel per gép, több háló kártya, alapból 1 gigabit per gép. Proxmoxszal szívtam, Ceph meg minden, de 2 géppel nem az igazi. Próbáltam úgy, hogy a 3. gép az egyik gépen egy Vm, hogy legyen 3 a Cephnek, de macera volt elindítani és nem is volt jó. Aztán raktam egyikre 2 Vmet másikra 1 Vmet, mindegyikhez külön hdd-t dedikáltan a Cephnek, de ez sem volt az igazi, bár működött, csak nagyon nem szép. A 3. fizikai gép csak ideiglenes mentésre alkalmas, néha fog menni. Ebből akarnám kihozni, hogy legyen shared storage, ami szinkronba tud állni a 3. gépen is akár, mint mentés,valamint az 1. és 2. gépen futó Vmnél lehessen live migrationt. Xcp-ng tudná a live migrationt,csak kellene harmadik gép mint shared storage hozzá, de az nem fér bele. Meg lehet Xcp-ngvel oldani, hogy egyben is legyen az Xcp-ng 2 szervere? Proxmox és Drbd elméletben jó lehet, de nem csináltam ilyet és sok problémás esetről olvastam. Ha ez lenne, hogy kellene feltelepíteni, használni, hogy menjen Proxmox alatt a live migration Drbdvel? Vagy kérlek mondjatok bármi mást, ami házi fájl szerverre és egyéb folyamatosan futó programok futtatására egy vmben alkalmas, ami tudja a live migrationt 2 gép esetén, de 3 gép esetén is. Ha 1-2, max 5 percre megáll, az még beleférne. Csak minimum 2 géppel menjen, így is sokat fognak fogyasztani, ha mindig mennek.
Frissítés 1:
Adott a 2 szerver ami régi desktop gép valójában, benne 2 gigabites hálókártyával, egyik alaplapi. Felraktam a legújabb xcp-ng 8.1.0-2 verziót a 2 gépre, linux raid 1, csak 2 hdd a gépekbe, azon minden. Létrehoztam egy közös xcp-ng poolt a 2 gépen, az még kellett a telepítés előtt. Halizardról letöltöttem az install scriptet ami 10 kbyte, az lehúzott minden csomagot. Megadtam az ip címeket, mi legyen a közös sannak az ip címe, és kész. Figyelmeztetett, hogy töröl mindent a poolból, de hát üres volt. A Drbd szinkronba állt, a második háló kártyán kommunikálva, létrehoztam egy linux vmet erre a közös tárolóra, futtattam rajta programokat és néztem, live migráltam egyiket a másikra, oda vissza, tök gyorsan ment. Azt is néztem, hogy a kettes gépre live migráltam a vmet, az elsőt kikapcsoltam. Majd ahogy visszajött, akkor szinkronba állt automatikusan, és újra live migrálás az első gépre. Tehát így megoldottam az automatikus mentést is. Ha akarom, így csak 1 gép megy, ha otthon vagyok, ha meg nem vagyok, bekapcsolom a másikat, és ha az első megáll, ott a másik.
Még azt fogom megnézni, ha az első gépen fut, majd áramtalanítom az első gépet, mi történik. Ahogy néztem be tudom állítani hány perc után indítsa el a közös tárolóról a maradék gép a vmet, meg van még sok opció.
Úgy, hogy mást csináltam közben, pár óra volt az egészet felrakni. Nem számítottam ilyen olajozott működésre.
- 1545 megtekintés
Hozzászólások
a minimum 2 magaban foglalja a 3-at is.....
linuxakademian volt hozza vmi hack, drbdvel. nezd meg.
- A hozzászóláshoz be kell jelentkezni
A 2 gép menne folyamatosan, a 3. csak néha, mint mentés, vagy olyasmi. Megnézem azt. Erre gondoltál?
https://devopsakademia.com/course/szerver-virtualizacio-xen-es-drbd/
https://xcp-ng.org/blog/2020/01/24/xcp-ng-and-linbit-alliance/
- A hozzászóláshoz be kell jelentkezni
ez lesz az
- A hozzászóláshoz be kell jelentkezni
Ha az egyik gépen van a storage és az áll meg, akkor mi a koncepció az átállásra? Ezek a gépek redundáns táposak, külön UPS-re tudod tenni a gépeket?
- A hozzászóláshoz be kell jelentkezni
Ezért írtam, hogy shared storageet akarok, ami megy 2 géppel, de hárommal is. Ha a Proxmox Cephnek 2 gép kellene csak, az lenne a megoldás. De 3 kell. Xcp-ng és Drbd megoldás lehetne?
- A hozzászóláshoz be kell jelentkezni
Jahogy úgy shared, igazából szerintem az distributed. :) A shared-et általában a több gép által elérhetőre használják, ami 1 doboz. A Xen és DRBD-t le kell tesztelni, hogy most mit tud. Ahol ilyenre van szükség, ott valamilyen cluster megoldást alkalmazok, általában egy FC vagy iSCSI storage-dzsel megtámogatva (dual controller).
- A hozzászóláshoz be kell jelentkezni
Rosszul neveztem meg, distributed vagy hyper-converged storage, amit ezek szerint keresek.
- A hozzászóláshoz be kell jelentkezni
Amit keresel szerintem azt úgy nevezik hogy hyper-converged storage. A koncepció lényege, hogy a hypervisorokon futnak VPS-ek, amik shared storageot valósítanak meg, gluster pl.: redundánsan. Majd ezt használha vissza a hypervisor és teszi rá többi VPS-t
Látható, hogy ehhez inkább SSD-k kellenek a sebességek miatt, akkor meg min 10GbE stbstb. Persze még mindig olcsóbb mint külön redundáns SAN hálózatot összedobni.
Fedora 42, Thinkpad x280
- A hozzászóláshoz be kell jelentkezni
Köszi javítottam. Bondingoljak, hogy 2*1 gbit legyen? Tudom, 2*10 vagy 2*40 sem túlzás, de Hdd van a gépekben, Linux Raid1 vagy Zfs raid1 lesz. Zfs gyorsabb érzésre, Proxmox alatt néztem.
- A hozzászóláshoz be kell jelentkezni
Itt egy teszt, hogy lásd kb mire lehet számítani:
https://xen-orchestra.com/blog/new-xosan-benchmarks/
https://xen-orchestra.com/blog/improving-xenserver-storage-performances-with-xosan/
Fedora 42, Thinkpad x280
- A hozzászóláshoz be kell jelentkezni
Bondingoljak, hogy 2*1 gbit legyen? Tudom, 2*10 vagy 2*40 sem túlzás, de Hdd van a gépekben
Kb. mindegy, a hdd miatt amúgy is foslassú lesz az egész.
- A hozzászóláshoz be kell jelentkezni
A Cephnek speciel elég kettő.
A Proxmox HA-nak nem.
Mondjuk ha van harmadik géped, akkor nem világos, hogy miért nem dobsz rá Proxmoxt, (Ceph-et nem kell) és meg is vagy...
- A hozzászóláshoz be kell jelentkezni
A harmadik gép gyenge, csak a hdd a megfelelő. Nem akarom, hogy menjen ezért 3 gép, a 2 az még oké.
- A hozzászóláshoz be kell jelentkezni
OK, ha Proxmoxból akarod, akkor kell 3 gép. A 3. lehet az rasberry is, mindegy.
- A hozzászóláshoz be kell jelentkezni
Mit ertunk az alatt, hogy "menjen"? Nincs penz hostolni? Osregi a vas, ezert barmikor elszallhat a rakba?
Mert amugy el nem tudom kepzelni, miert ne lehetne folyamatosan online a gep, meg ha VPS-ek nem is kerulnek ra. A Proxmoxnal tudomasom szerint megadhato, hogy mikor mi tortenjen, ha eleve keves memoriat raksz a gepbe (vegulis csak witnessnek kell a clusterbe), akkor nem nagyon fog odapakolni semmit.
A Proxmox HA eseten viszont egyaltalan nem opcionalis, hogy a 3. gep folyamatosan menjen. Ha csak 2 gep megy, es az egyik megdogik, elegge haromeselyes hogy osszeall-e ujra a cluster. Raadasul a splitted brain veszelye miatt nagyon fontos a paratlan szamu gep a clusterben.
Adatvesztes ritkan lehet belole, raadasul ha a Proxmox alatt szet is esik a cluster, a gepek ebbol mit sem vesznek eszre. Akar ujra is epitheted a Proxmox clustert alatta, a Qemu/KVM nem fog megallni emiatt. Inkabb az a problema, hogy eleg trukkos ujrahuzni a clustert, foleg, ha nem tudod, hogyan kell, vagy nem tudod egyaltlaan, mi a problema. Meg ha tudod se egyszeru. Ezert en semmikepp sem javaslom, hogy a clustert 3-nal kevesebb geppel futtasd barmikor.
Ahogy mondtam, a Proxmoxnal szabalyozhato, mit hol inditasz, ha az a felelem, hogy valami a gyenge gepen indul el - ne aggodj, nem fog, ha nem akarod. Viszont, cluster witnessnek egy kenyerpirito is alkalmas, es sokkal nagyobb hasznot hajt (szivasi idoben) mint amennyibe az uzemeltetese kerul.
- A hozzászóláshoz be kell jelentkezni
A harmadik gep regebbi, lassabb es sokat fogyaszt. Nem akarom, hogy menjen folyanatosan. Olyan megoldast keresek, ami 2 géppel is megoldás erre.
- A hozzászóláshoz be kell jelentkezni
a cephnek nem eleg ketto a gyakorlatban, csunyan be lehet szopni. aki jot akar maganak ne futtasson size=2 replikalt poolt legyszi.
- A hozzászóláshoz be kell jelentkezni
pont ahogy a min=3 nodeszamot is inkabb fole lojuk
- A hozzászóláshoz be kell jelentkezni
size=3 min_size=2 jol mukodik
- A hozzászóláshoz be kell jelentkezni
Pl. valami hasonló a https://logout.hu/cikk/vmware_es_glusterfs/bevezetes.html cikkben leírtakhoz.
--
Légy derűs, tégy mindent örömmel!
- A hozzászóláshoz be kell jelentkezni
Erre valo megoldas lehet az alabbi pl.?
- A hozzászóláshoz be kell jelentkezni
http://www.xtreemfs.org/
https://www.beegfs.io/
Proxmox alatt a mountot felveszed mint sima mappát (directory) és bepipálod "[X] Shared" opciót.
( GUI > Datacenter > Add > Directory )
- A hozzászóláshoz be kell jelentkezni
És arra mentem a vm-et és kész, Ceph sem kell? A proxmox HA meg elinditja a vmet a masodlagoson ha az elsodleges gep megall?
Érdemes bondolni egy alaplapi és egy pcie gigabites kartyat?
Ez a 2 miben más mint a drbd?
- A hozzászóláshoz be kell jelentkezni
Nem kell Ceph.
Proxmox HA esetén 3-node (3db gép) kell, nem fogja elindítani - kézzel kell indítanod.
Az alaplapi hálókártyákat nem preferálom, dedikált PCI-E kártyán lévő portokat érdemes (egyazon kártyán lévőket).
Aggregált sebességet nem mindegyik switch támogatja, tehát csak max 1G lesz akkor is a sebesség.
DRBD az blokk eszközt emulál, ami megjelenik az összes hoszton, de csak egy adott hoszt írhatja egyidőben - többi nem (fencing),
a fenti megoldások pedig "fájlrendszer replikációt" csinálnak - képes elosztott IO-ra (hasonló megoldás mint a Microsft Storage Spaces).
- A hozzászóláshoz be kell jelentkezni
Ez a lenti halizard jónak tűnik, Drbd+iscsi:
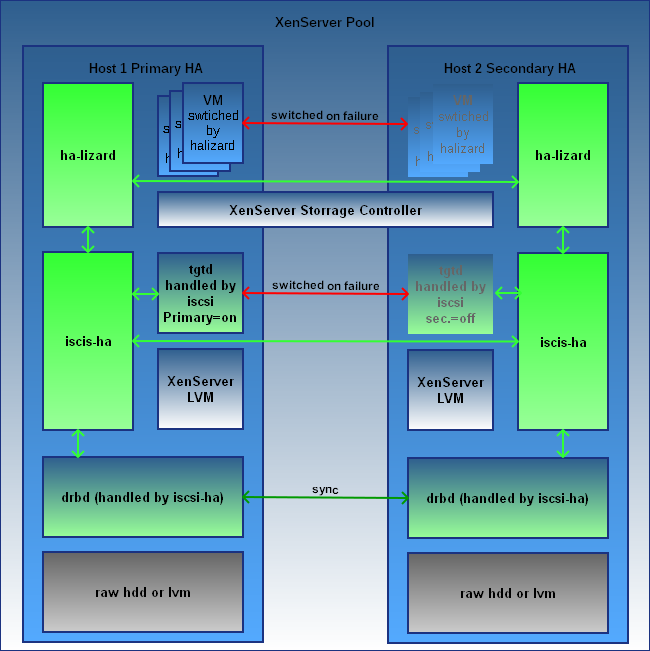{kind=link}
- A hozzászóláshoz be kell jelentkezni
(bonding) " dedikált PCI-E kártyán lévő portokat érdemes (egyazon kártyán lévőket). " - ezzel megoldod azt, hogyha a kártya rotty, akkor a bonding interfész mindenestől rotty. A bondingot a rendelkezésreállást _is_ növelő megoldásként célszerű összerakni, azaz két fizikailag független adapter/eszköz legyen lehetőleg a kábel mindkét végén. Szerintem...
- A hozzászóláshoz be kell jelentkezni
Akkor ne 2*1 gigabit egyben, hanem 1+1 gigabit, akár külön subneten, switch-en? Vagy alaplapi 1 + 2*1 pcie gigabit? Ha a bonding meghal, kártya csere és kész.
- A hozzászóláshoz be kell jelentkezni
Mehet a bonding/teaming, csak célszerű két fizikailag független kártyára rakni. Így ha az egyik fizikai lábát kiszolgáló kártya megkotlik, a másik még -fele sávszélességgel- el tudja vinni a forgalmat addig, amíg a karbantartáshoz (kártyacsere) szükséges leállásra időt lehet szakítani. Ugyanezért célszerű (ha van rá eszköz) a másik oldalon két switchet használni (stackelve), és úgy kialakítani a lacp trönköt a túloldlaon is - így egy switch kiesését is "túléli" a rendszered.
- A hozzászóláshoz be kell jelentkezni
Hasznos. 2 kulon halozati kartya, 2 switch. Ha a routerem megall, akkor ugysem erem el wifin a gepeken levo vmet, amiben ott a fajl szerver. Meg nem eri el a wifis cuccokat. Meg nem lesz net. De ez masik problema lehetőség. Lehet ezt meg bonyolitani, nem kicsit. 2 router, 2-3 switch, dizel aramgenerator, olomfalu bunkerben, 1 ev szaraz elelemmel es oxigénnel :)
Ha a 2 halokartyabol az egyik megkotlik, akkor perec van, mert a masikon meg csinalok egy live migrationt, atallok a masik gepre, lekapcsolom es halo kartyat vagy hddt cserelek. Ha kesz, vissza live migration. Jo otlet, koszi.
- A hozzászóláshoz be kell jelentkezni
Ez is megoldás lehet?
- A hozzászóláshoz be kell jelentkezni
Azert fontos cuccot ne bizz ra ;)
- A hozzászóláshoz be kell jelentkezni
Jó, de mit javasolsz? A 2 géppel van bajod vagy mással?
- A hozzászóláshoz be kell jelentkezni
Gondolom arra utal, amire énis probáltam, hogy szép a HA, de azért vasból sem jó bármit alászórni, illetve minimum két külön szünetmentes kell. Lelkileg én még ott járok, hogy a HA cluster jellemzően akkora ráfordítást igényel (hogy az munka vagy eszköz ár, az most lényegtelen), hogy egyáltalán nem biztos, hogy nyersz vele annyit valójában. Ha desktop szerű dolgokból rakod össze, pláne desktop diszkekkel és nincs hotswap opciód, akkor ha kísérleti/hobbi projekt, akkor szerintem ok, de élesben inkább egy jóféle rendundás szerverrel próbálkoznék. Aztán ha az üzleti igények kilőnek az égbe, akkor prezentáljuk a költségét a szuperHA-sohanemállmeg c. sztorinak és rögtön nagyon el szoktak gondolkodni.
A szűk keresztmetszetek általában az áramellátás és az internet kapcsolat vagy a helyi hálózat, nem a hardware. Hardware fronton nagyon kényelmes, hogy az ember livemigrál, node-ot frissít, akár még ki is porolja (kompresszorral kirobbantja az előző év féltonna porát) és mindezt munkaidőben és mindezt szolgáltatás kiesés nélkül. A másik szűk keresztmetszet az a cluster megoldás mondjuk úgy "elszakadása a valóságtól". Partnernek volt Proxmox hálózat megállási problémája, gyakorlatilag semmi se ment sehova, ismerősnél a Ceph köszönt el és sokórás állásideje volt. Én Windows-os vonalon láttam, hogy a szerintük "seamless rolling update" az inkább volt hegyomlás, mert nem vette észre, hogy a másik cluster node még azért frissít és leküldte a másikat is, mindezt persze éjjel 3-kor. A clusternyugalomban töltött szundiidő után meg fél8-kor kellett mindenfélét trükközni, hogy egyáltalán távolról nyakon lehessen vágni a gépeket. Amik abszolút stabil részei voltak a clustereknek, azok a két controlleres FC vagy iSCSI storage-ek, bár más meg ebből látott nagy fejreállást.
Szóval arra próbálok utalni, hogy a rendszered bonyolításával ezzel négyzetesen arányos (minden bonyolító lépéssel...) problémacsomagot veszel a nyakadba. Úgy indulnék neki, hogy alulról a hw-ből elindulva megnézném, hogy önmagában vagy párban mire számíthatok, milyen az áramhelyzet és a nethelyzet, a gépek hálózati elérhetősége mennyire lehet redundáns. Ha példul van egy egytápos switch a gépek előtt (melyik UPS-re kötöd...), vagy ha egy switch van, akkor máris ott a szűk keresztmetszeted. Persze egy switch ritkán hal meg, de itt mindíg lehetőségekről és azok kizárásáról beszélünk, amivel csökken a szolgáltatás előrhetőségének vagy leállásának veszélye.
- A hozzászóláshoz be kell jelentkezni
Van egy szinuszos régi szünetmentesem új akkukkal, azon van a net, router, switch meg ez a 2 gép. Fájl szerver és a hobbi Home Assistant futna ezen, meg ami még kell majd. Családi célra, semmi üzletileg kritikus nincs itt. Csak jó lenne ha menne és nem lenne adatbukta. Kicsit kihívásból is 2 gép, meg mert van.
- A hozzászóláshoz be kell jelentkezni
Adatbukta az valóban nemfinom, de én többfelé mentéssel védekéznék ellene. Akár egy kicsi NAS-sal (inkább erre használnám el a másik gépet, úgy hogy a másik gép problémája esetén ezen is mehessenek a szolgáltatások) másik UPS-en és úgy beállítva, hogy áramszünet esetén hamar lekapcsoljon, e mellett valamilyen felhős szolúcióba szinkronizálnék. Extra mentés, hogy hetente vagy havonta egy külső HDD-re mentenék, amit bár lakáson belül lehetőség szerint messze tárolnám. A két gép párhuzamos futásának a villanya se túl barátságos, illetve nagyban csökkenti a szünetmentes áthidalási idejét.
- A hozzászóláshoz be kell jelentkezni
Jogosak az érvek. Amit lentre írtam, hogy a halizard xcp-ng clusterből folyamatosan csak 1 megy, a másik néha, az jó lehet?
- A hozzászóláshoz be kell jelentkezni
A klasszikust idézve: az a jó cluster megoldás, ami nem csökkenti a rendelkezésre állást. A két node-os felállás, a kevés üzemeltetési tapasztalat azt mondatja, hogy a fenti rendszer nem lesz jó megoldás.
Ha a legjobb rendelkezésre állást akarod kihozni a 2 gépből, akkor én az egyik gépet hidegtartaléknak használnám, ezzel jóval egyszerűbb lesz a software stacked, kevesebb hibalehetőseggel, és a HW hibák esetén is van hova nyúlni azonnal.
- A hozzászóláshoz be kell jelentkezni
Hát ja. Egyszerűbb lenne, ha 1 gépes lenne, a másik meg tartalék. De ha Xcp-ng és halizarddal megcsinálom a 2-3 gépes ha clustert, még akkor is lehet az, hogy csak 1 megy, karbantartáskor vagy frissítéskor bekapcsolom a másikat, ha szinkronban van, live migration, aztán kicsit a másik megy. Tanulságos lesz, hogy mi lesz.
- A hozzászóláshoz be kell jelentkezni
Ez kissé ellentmondásban van azzal, hogy: "max 5 perc leállással".
Azért azt vágod, hogyha csak 1 géped megy és elhal, akkor nincs a világon olyan rendszer ami bekapcsolja a tartalékot és átviszi a halott gép adatait...
- A hozzászóláshoz be kell jelentkezni
Nem ellentmondas. Attol, hogy 1 gep egyszerubb, meg 2 gep lesz. Nem is gondoltam arra amit irtal, mert hulyeseg a jelenlegi gepekkel.
Ez a halizard lehet megoldja,2 gep, ha egyik megall, a masikon elindul a vm, ez kell. Ilyesmi.
- A hozzászóláshoz be kell jelentkezni
2 gép lehet, de automata failovert ne akarj. Split brain esetén majd te tudod, hogy melyik maradt abban az állapotban, amelyik használható. 2 gépes cluster nem fog jó döntést hozni magától. Illetve van rá 50% esélyed, hogy igen. Ha ez neked jó, csináld.
- A hozzászóláshoz be kell jelentkezni
Ha split-brain lesz a clustered, akkor nagy valószínűséggel rosszul konfiguráltad. 2 gép esetén a védelem utolsó vonala a STONITH ami meg kell hogy akadályozza a split-braint.
- A hozzászóláshoz be kell jelentkezni
Nem csináltam ilyet, de veszek 2 ilyen ip áram ki/be/reset kütyüt, rajta a 2 gép, amivel stontholom a másik gépet, és kész? Vagy hogy illik? Fegyverrel csak nem lőhetik le egymást a gépek :-)
- A hozzászóláshoz be kell jelentkezni
Ha egy fázisod van, akkor ebből kettő jó. Ha 2 fázisod van, akkor bonyolodik a helyzet, mert a két gépet nyilván külön fázisra teszed, de a STONITH eszköz vezérlése másik fázison kéne hogy legyen mint ami vezérelve van (vagy akkun) és ez azt nem tudja. Ha egy fázisod van, az viszont nem valami jó HA, mert pl egy zárlatos táp egyszerre fogja lerántani a gépeket.
A redundáns tápos szerverek és a dedikált porton figyelő IPMI alapú STONITH gyakran a legegyszerűbb megoldás.
- A hozzászóláshoz be kell jelentkezni
Akkor ipmi kártya lesz, redundáns táp elsőre nem lesz.
- A hozzászóláshoz be kell jelentkezni
Az lesz a gond, hogy ha meghal a táp, akkor megáll az ipmi, és a STONITH nem lesz nyugtázva amire reagálhat úgy a cluster, hogy a potenciális split-brain helyzet miatt nem migrál (unclean node). Fel tudod úgy scriptelni/konfigolni, hogy ebben az esetben vegye úgy hogy halott az alany, de erre külön gondot kell fordítanod. Ezért hasznos ha a fencing device tápja eleve redundáns vagy legalább független az alany betápjától — egy gonddal kevesebb.
- A hozzászóláshoz be kell jelentkezni
Ha jól olvastam a halizard ezt is kezeli. Ha meg visszajön a kiesett gép, beszél a másikkal, látja hogy ott megy a vm, így szinkronba áll és ez lesz a másodlagos.
- A hozzászóláshoz be kell jelentkezni
IPMI kártya? Milyen szerver/gép az, hogy csak úgy beleraksz egy valamilyen IPMI kártyát?
- A hozzászóláshoz be kell jelentkezni
Ezt belerakom a 2 gépbe: https://www.ebay.com/itm/Supermicro-AOC-SIMLP-3-Dual-Port-IPMI-2-0-Remo…
- A hozzászóláshoz be kell jelentkezni
Ezek szerint X7-es Supermicro lapjaid vannak? Csak úgy nem tudsz IPMI kártyát tenni egy random alaplapba.
- A hozzászóláshoz be kell jelentkezni
Ja nem. Joval dragabban lattam univerzalis ipmi kartyat, orultem is ennek. Korai öröm.
Hogy szokták megoldani a stonith / fencinget megoldani ipmi nelkuli szervereknel? Veszek valami wifis vagy ethernetes relay kapcsolot, legalabb 2 portosat, es egyik gep lekapcsolja a masikat? Mondjuk nem tunik szep modszernek lekapcsolni az aramot, de ha ez kell... Az nem jo, hogy egymast le tudjak kapcsolni sshn shutdownnal?
Kell ez az egész? A halizard nem lehet, hogy kezeli ezt is szoftveresen? Lehet osszerakom hetvegen halizardra a gepeket, 2 halo kartyaval, 2 switchen. Megirom a tapasztalatokat majd.
En nem ragaszkodom a halizardhoz, csak nem talaltam mas, kesz cuccot erre.
- A hozzászóláshoz be kell jelentkezni
A hw-től építkezel felfelé. Amit papíron kitalálsz, azt végig kell tesztelni mindenféle esetre. A sima puff kikapcsolás nem túl nyerő. Olyat szoktak, hogy A és B út van a két szerver között, akár mindkettő hálózati és ennek függvényében megy az átállás/kikapcsolás. A fő problémád az lehet, hogy mindkét gépet azt hiszi, hogy ő maga az elő cluster, pláne ha a storage is mindkettőn ott van. Arra próbálunk rávezetni, hogy adott esetben többet árt, mint használ egy ilyen történet. Minden esetre a választott megoldást ha összerakod, akkor mindenképp teszteld mindenféle esetekre, hogy hogyan viselkedik.
Amiket én láttam, ott "ezt megoldja a rendszer" szinten voltak ezek kezelve, illetve ott az FC vagy iSCSI storage*, amin ott figyel a quorum -ra használt LUN. E mellett a hálózat és elektromos ellátás független volt, illetve a redundáns tápokat tudtuk különféle UPS-eken variálni, akár 3-4-en, ezzel próbáltuk a fölösleges átállási procedúrát elkerülni.
* A storage-et defacto elpusztulhatatlannak vettük a dupla controller és dupla táp és minden miatt, ott kellett meghúzzuk a határt, mert az anyagi keretek miatt nem tudjuk duplázni/replikálni.
- A hozzászóláshoz be kell jelentkezni
Aha. Hát nincs ilyen komoly storageem. Megnezem mi lesz, tesztelem majd. Ha mar 1 vmben fut majd, az is elorelepes, tudok snapshotot es mentest csinalni leallas nelkul. Aztan ha a masik gepen el is indul, az mar igazi csoda :)
- A hozzászóláshoz be kell jelentkezni
Megoldás lehetne még az is, h veszel Synology NAS-t, kiajánlasz belőle iSCSI kötetet...
- A hozzászóláshoz be kell jelentkezni
"megoldani ipmi nelkuli szervereknel" - milyen szerver az, amiben nincsen IPMI/ILO/stb és redundáns táp? :-)
- A hozzászóláshoz be kell jelentkezni
Kiszolgáló funkciókra használt desktop gép. Maximum.
- A hozzászóláshoz be kell jelentkezni
Pl. HP Microserver Gen 10
--
Légy derűs, tégy mindent örömmel!
- A hozzászóláshoz be kell jelentkezni
Hogy szokták megoldani a stonith / fencinget megoldani ipmi nelkuli szervereknel?
Az a kánagy igazság, hogy a rendes fencinghez külső hardver kell, az ideális pl. a külső intelligens storage eszköz, ami egyszerre adja a közös diszkeket (és akkor nem kell drbd-vel se bohóckodni), plusz ezen keresztül egy nagyon egyszerű fencing mechanizmust is tud adni (akinek nem szabad működnie, azt nem engedi oda az adatokhoz, így nem tud benne kárt tenni).
Ez a stonith, ez a szegény ember fencingje. Kicsit savanyúbb, kicsit sárgább...
Az nem jo, hogy egymast le tudjak kapcsolni sshn shutdownnal?
Azt ugyan hogy csinálják, amikor éppen mondjuk rebootol a másik gép? Vagy szimplán nem megy a kernel? Vagy amikor fizikailag ki van kapcsolva a másik gép, mert beszart a tápja?
es egyik gep lekapcsolja a masikat?
Az az eset megvan ugye, hogy ha mind a kettő kikapcsolja a másikat, akkor egyik sem fog kiszolgálni?
- A hozzászóláshoz be kell jelentkezni
Aztán pont akkor nem fog működni, amikor szükség lenne rá. Olyan gyakran nem lehet tesztelni egy ilyen eszközt.
- A hozzászóláshoz be kell jelentkezni
Nyilván monitorozni kell a cluster állapotát, ami pl fél percenként lefuttatja a fencing eszközök öntesztjét, ha pedig valami nem stimmel akkor jön a riasztás.
- A hozzászóláshoz be kell jelentkezni
https://www.linbit.com/linstor-setup-proxmox-ve-volumes/
promoxnal csak akkor kell 2 tobb gep ha automata vm inditgatast akarsz, stb. amugy ketto geppel is kivaloan mukodik, ha megpusztul az egyik node, akkor kezzel kell inditani a masik node-on a vmeket (de ez hazi gepnel belefer). ha kell az automata cucc, akkor tegyel hozza egy rpi vagy valami alacsony fogyasztasu gepet.
A vegtelen ciklus is vegeter egyszer, csak kelloen eros hardver kell hozza!
- A hozzászóláshoz be kell jelentkezni
Értem, köszi. Mivel 2 gépben gondolkozom ezért xcp-ng halizardot fogom megnézni ipmi kártyákkal. Ez elvileg elinditja a másik gépen a vmet ha megáll az első.
- A hozzászóláshoz be kell jelentkezni
nagyon szornyen hangzik :( ipmi kartya, joeg.
azt aruld el nekem micsoda hobby projekt lehet az otthon ahol max 5 percet allhat a cucc?:)
- A hozzászóláshoz be kell jelentkezni
Nekem eszembe sem jutott az ipmi kartya, az itteni szakik javasoltak, gondolom okkal. Home Assistantot akarok hasznalni, vezetek nelkuli szenzorokkal, relékkel, öntöző rendszer, redőny, ki tudja még mi jut eszembe. Gondoltam jo lenne valami megbizhato megoldas, ami folyamatosan megy. Igy jutottam idaig. Nyilvan allhat 5 percet, akar orakat is, de ha nyaralni megyek, jol lenne, ha mukodnenek az elore kitalált rendszeres folyamatok, ez a gep meg felugyelne. Aztan ott a file szerver, ha mar lesz ez a 2 gép, az is legyen ezen, a vmben. Kicsit kihivas, hogy jo lesz-e, meg ha maceranis megcsinalni. Maximalizmus, ami nem indokolt. Ha meg lehet oldani, hogyha megall az elso gep, a masodikon ujra elindul a vm, automatikusan, akkor miert ne? Egyszerubb lenne egy hp mikroszerver, csak 1, aztan kesz, de ha van vele valami es nem vagyok ott, az sem katasztrofa, de mivel adott a 2 gep, kihozom belole a ha clustert, ha megoldhato.
5-7-9 szerver is lehetne, elosztva kulonbozo foldrajzi helyen, duplan tappal, sok halo kartyaval, vagy helyben kulonbozo switcheken, de nyilvan ez mar az overkill overkillje lenne. En megelegszem a sima overkillel, 2 geppel, sima, jo tapokkal, erre keresem amit ki lehet hozni szoftveresen. Ha megall mind a 2 gep, megall, de megprobaltam. Tobb eselyem van, mint 1 geppel ha megall vagy adatbukta lesz. Attol, hogy neked overkill, felesleges, tulbonyolitott, nekem meg lehet pont jo es hasznos.
Volt, hogy régen a Desktop Linuxomra mindent csomagbol forditottam, amikor nagyon lassu gepem volt. Hogy gyorsabb lesz. Nem ereztem, hogy gyorsabb lett volna, de legalabb onnantol nem tudtam csomagokkal frissiteni a fuggosegek miatt. Nem sikerult, aztan ujra telepitettem mindent csomagokkal es ugy karbantarthatobb lett. Azota ketszer is meggondolom, hogy mit rakok fel kezi forditassal. De kiprobaltam.
- A hozzászóláshoz be kell jelentkezni
vagy 1, vagy 3 gep legyen. 2 semmikepp. igen, ha 1 van, es megall, akkor megallt, de ezek azert nem tortennek meg olyan surun igazi szerver vasakkal.
en azt javaslom vegyel hasznalt szervert ami nem olyan regi (mondjuk dellt v supermicrot), ezeket olyan 60-120k korul utanad vagjak darabonkent, aztan mar csak penztarca kerdese hogy 1 v 3 lesz.
- A hozzászóláshoz be kell jelentkezni
Ismered a halizardot? Azt irja, hogy 2 gepes piacvezeto ha cluster free megoldas. En csak olvastam a honlapjat, azert kerdezem. Nem lehet, hogy jo lesz?
- A hozzászóláshoz be kell jelentkezni
nem ismerem, de nem kell ismernek: 2 gepes rendes HA nem letezik.
- A hozzászóláshoz be kell jelentkezni
Én hiszek nekik, csak nem hoax, idézet:
"It's official, we are the number one solution around the world when it comes to Citrix Xenserver and High Availability on two-node clusters using standard internal storage! It's easy to use, 100% reliable and no strain on hardware resources. Best of all, it's free with no purchase requirements, no adware, and no hidden code."
- A hozzászóláshoz be kell jelentkezni
arra akarnak rávilágítani, ha 2 gép van, le vannak szakadva egymástól és mindkettő magát gondolja az egyedüli gépnek qrvanagy szívásnak nézhetsz elébe.
A 3. gép pedig arra való, hogy megerősítse a gépet abbéli hitében hogy tényleg csak ő működik. De ezt is leírták más sokan.
- A hozzászóláshoz be kell jelentkezni
Hinni a templomban kell. Ők azt mondják, hogy ebből a fos felállásból ők tudják a legjobbat kihozni (csak kicsit marketingesül fogalmazták meg). De ebből egyáltalán nem következik, hogy ez abszolút értékben is jó valami lesz (amúgy nem lesz, a lehetetlent ők sem tudják megugrani).
- A hozzászóláshoz be kell jelentkezni
Na, lassan csak kiderul a "miert" is:)
Ha tenyleg ennyi, akkor szerintem felejtsd el ezt az egesz bonyolult dolgot amit kitalaltal. Futtasd az egyik gepen a HA-ot, az sqliteot mented 5 percenkent backup apival, rsynceled a masik gepre, a konfig fajlokat szinten. Van telepitve ott is egy HA-od, ami nem fut, amig a masik nem all le. Ha leall felhuzod azon a gepen az IP-t, es elinditod amit el kell. Ha van MySQL-ed akkor csinalz egy master-slavet, ha van Prometheus akkor futtatsz mindket gepen, stb. App oldalon sokkal konnyebben megoldod, mint ha tapasztalat nelkul akarsz megbizhato ket nodeos clustert epiteni. Ahogy szinte mindig: kiveve ha tanulni akarsz, es nem szamit ha all:)
- A hozzászóláshoz be kell jelentkezni
Hat, amit leirtal az talan nagyobb melo, mint xcp-ngt felrakni es ra a halizardot, es megy is. Onnantol meg eleg 1 vmet kezelni.
Tanulni akarok, de a te javaslatod nem oldja meg, ha nem vagyok ott es megall a Ha. Mentesem lesz, de ennyi. Mondjuk az is tobb, mint a semmi. Ilyen alapon felhobe is menthetnek majdnem.
Ha nem lenne 2 gepem erre, es nem erdekelne, hogy menni fog vagy nem a 2 gepes hazi ha cluster, berelnek valami olcso felhos vmet.
No offense, peace meg minden, de aki le akar beszelni a 2 gepes ha clusterrol, ti probaltatok a gyakorlatban is elkesziteni es uzemeltetni, hasznalni? Peldaul azt a halizardot? Mert elvileg mindent megold magatol. Bocs a hülye kérdésért.
- A hozzászóláshoz be kell jelentkezni
Hat, amit leirtal az talan nagyobb melo, mint xcp-ngt felrakni es ra a halizardot, es megy is. Onnantol meg eleg 1 vmet kezelni.
hajra, csinald akkor:)
Tanulni akarok, de a te javaslatod nem oldja meg, ha nem vagyok ott es megall a Ha. Mentesem lesz, de ennyi. Mondjuk az is tobb, mint a semmi. Ilyen alapon felhobe is menthetnek majdnem.
ooo, elinditod? leirtam ezt is, a megvalositas a fantaziadra van bizva, olyan 20 sor lehet bashben.
No offense, peace meg minden, de aki le akar beszelni a 2 gepes ha clusterrol, ti probaltatok a gyakorlatban is elkesziteni es uzemeltetni, hasznalni? Peldaul azt a halizardot? Mert elvileg mindent megold magatol. Bocs a hülye kérdésért.
igen. halizardot nem, soha nem hallottam rola. a 2 nodeos cluster alapvetoen egy elmeleti problema, amit szepen korbe lehet bastyazni mindenfele "hekkekkel", de ehhez vegig kell gondolnod sokmindent, nem eleg egy random IPMI kartyat megrendelni netrol. dap leirt sokat ebbol (neki is hihetsz, o is latott mar ilyet:), de ettol meg boven lesz hazi feladatod, ha az nagy melonak hangzik, amit leirtam. ketsegkivul jobb ha csak a fu szarad ki, mint ha a fonokod hiv fel orditozva, hogy miert all minden, ezert mondtam, hogy ha tanulni akarsz, akkor hajra:)
- A hozzászóláshoz be kell jelentkezni
Nyilván munkára nem erőltetném a 2 gépes Hat, ha meg ez lenne a munkám meg tudnám talán oldani jól. Kompromisszumot kotok: adott hardveren kihozni a Hat, ahogy lehet. Az eredmenyrol beszamolok.
- A hozzászóláshoz be kell jelentkezni
az talan nagyobb melo, mint xcp-ngt felrakni es ra a halizardot, es megy is. Onnantol meg eleg 1 vmet kezelni.
Aztán amikor jön a silent adatvesztés, és az 1 szál vm-ed nem indul többet, na akkor lesz majd igazán sok meló...
- A hozzászóláshoz be kell jelentkezni
"Home Assistantot akarok hasznalni, vezetek nelkuli szenzorokkal, relékkel, öntöző rendszer, redőny, ki tudja még mi jut eszembe"
Aha, na ettől kezdve overkill az egész topik. Ezt százan megcsinálták már előtte valami mikrovezérlőre. Akár arduino, 433MHz rádiós adó-vevőkkel beszélnek a modulok a központi arduinoval és kész. Ha kevés az atmel, lehet stm32 irányba nézelődni. Ezek nem állnak meg és nem fogyasztanak száz wattokat, mint a felvázolt borzadalom :)
Egyébként meg, ha a modulokon van egy RTC, a központi mikrovezérlőtől megkapják az ütemezést, mikor kell locsolni, redőnyt leereszteni és ha lefagyott a központ, elmennek a korábban kapott ütemezés szerint.
A redőny vezérlőhöz köthetsz helyben fényérzékelőt, de igazából az RTC-ből is sejti, hogy este van...nem kell a központra támaszkodni.
És akkor az ész nem centralizálva van, ha annyira félsz, hogy fejreáll, akkor megállt mindent. Bár, ha megáll, minden mi van? Pár millió ember elmegy nyaralni ilyen cuccok megléte nélkül is és semmi nem történik.
Szóval az egész annyira rossz végén lett megfogja, hogy hűha :)
- A hozzászóláshoz be kell jelentkezni
Nem vagyok én rádióműszerésforrasztófénykardmester. :) Beleolvastam itt sok mikroelektronikai, arduinos temaba, hat mindenki mashogy neheziti az eletet. Haverom Xiaomi kész wifis okosotthon termékekkel Raspberryn használ Home Assistantot, jo lassu, meg megdoglott az sd kartyaja es mindene elveszett, kezdhette ujra az egeszet. Meg elotte is valami volt es lagalabb haromszor ujra beallitott mindent. En ezt probalom elkerulni ezzel. Neki kulon Nas van, nekem az egyik gepen most linux es samba megosztasok, lamp, stb. Ezek kerulnek majdba vmbe a Home Assistanttal egyutt. Mi abban az overkill, hogy amugy is megy egy gep, ami mindenes linux, most vmben fut majd, 2 gepen? Fogyaszt majd a 2 gép 50-90 wattot, drága hobbi.
- A hozzászóláshoz be kell jelentkezni
ha mar eldontotted hogy szopatod magad es mindenki mas csak hulye akkor nem ertem miert nyitottad ezt a topicot
- A hozzászóláshoz be kell jelentkezni
Én nem mondtam, hogy mindenki hülye, sőt, ti vagytok a szakik, és onnan nézve csak én a hülye kezdő amatőr kontár inkompetens machinátor. A te szóhasználatoddal: javaslatot várnék tőletek, ha már úgy is sz*pni fogok, a legkevésbé kelljen. Mert lehet kicsit, közepesen, nagyon, 1 és 2 bubival is.
- A hozzászóláshoz be kell jelentkezni
irtam mar en is hogy 1 v 3 gep, mas is irta hogy valami embedded cucc vezerelni. ezek a legszopasmentesebb utak szerintem. a 2 gep semmikepp.
- A hozzászóláshoz be kell jelentkezni
Én biztos nem bonyolítanám túl ennyire a sztorit :D
Ha mindenképp 2 géppel akarod megoldani, szerintem egy x időnkénti rsync a fő gépről a másikra, illetve a második gép mondjuk folyamatosan pingelné az elsőt. Amennyiben hosszútávon kimaradást észlel az első gép irányába (x>5perc mondjuk), akkor a második gép elindítja az adott szolgáltatásokat és ha IP érzékeny a dolog akkor a gép címét is átvésné. Max egy rebootot lehet közbeiktatni. Amikor meg hazaérsz mindent visszadobsz kézzel/automatizálva. (Reflektálva az öntözőrendszer, stb részre)
Nem a világ legjobb megoldása, de ez ilyen "lowbudeget-homemade HA" lehetne.
- A hozzászóláshoz be kell jelentkezni
Ertem, koszi a javaslatot. Ha lehet, nem akarom feltalálni azt azt, ami kész.
- A hozzászóláshoz be kell jelentkezni
Félreértés ne essék, nem kötözködésből: de az általad futtatni kívánt programokat 'out of the box' módon keresed végülis? Mert amit én írtam az nem újrafeltalálás, szimplán pár extra kör szenvedéstől megkímél.
- A hozzászóláshoz be kell jelentkezni
Úgy értem, ha van az a halizard peldaul, ahol xcp-ng-hez megcsinaltak a drbd, iscsi, stb modon a mukodest, scriptelve ami logikus, akkor en nem akarnek csinalni ilyet magamnak nullarol vagy egy felkesz modszert tokeletesre, ha ez mar elerheto. Megirom a halizard tapasztalatot, aztan kiderul bevalik vagy nem. Koszonom a segitseged neked es itt mindenkinek.
- A hozzászóláshoz be kell jelentkezni
Frissítés 1:
Adott a 2 szerver ami régi desktop gép valójában, benne 2 gigabites hálókártyával, egyik alaplapi. Felraktam a legújabb xcp-ng 8.1.0-2 verziót a 2 gépre, linux raid 1, csak 2 hdd a gépekbe, azon minden. Létrehoztam egy közös xcp-ng poolt a 2 gépen, az még kellett a telepítés előtt. Halizardról letöltöttem az install scriptet ami 10 kbyte, az lehúzott minden csomagot. Megadtam az ip címeket, mi legyen a közös sannak az ip címe, és kész. Figyelmeztetett, hogy töröl mindent a poolból, de hát üres volt. A Drbd szinkronba állt, a második háló kártyán kommunikálva, létrehoztam egy linux vmet erre a közös tárolóra, futtattam rajta programokat és néztem, live migráltam egyiket a másikra, oda vissza, tök gyorsan ment. Azt is néztem, hogy a kettes gépre live migráltam a vmet, az elsőt kikapcsoltam. Majd ahogy visszajött, akkor szinkronba állt automatikusan, és újra live migrálás az első gépre. Tehát így megoldottam az automatikus mentést is. Ha akarom, így csak 1 gép megy, ha otthon vagyok, ha meg nem vagyok, bekapcsolom a másikat, és ha az első megáll, ott a másik.
Még azt fogom megnézni, ha az első gépen fut, majd áramtalanítom az első gépet, mi történik. Ahogy néztem be tudom állítani hány perc után indítsa el a közös tárolóról a maradék gép a vmet, meg van még sok opció.
Úgy, hogy mást csináltam közben, pár óra volt az egészet felrakni. Nem számítottam ilyen olajozott működésre.
- A hozzászóláshoz be kell jelentkezni
Azt nézd meg, hogy mi van akkor, ha széthúzod a hálózato(ka)t a két gép között...
- A hozzászóláshoz be kell jelentkezni
Másik edge case: egyik gépet leállítod, a másikon változtatsz valamit, aztán azt is leállítod, és beindítod az elsőt (nyilván a múltbéli állapotból fog továbbmenni), csinálsz rajta valamit, majd beindítod a második gépet. A helyes kérdés ugye az, hogy melyik adatod fog elveszni, és csendben, vagy szól.
- A hozzászóláshoz be kell jelentkezni
+1 teljes áramszünet és utána egyszerre indítás. Ki mit hisz magáról. Vár-e bizonyos ideig, hogy indítás után megtalálja a haverját, vagy rögtön kinevezi magát főnöknek? És kinek az időbélyege lesz erősebb?
- A hozzászóláshoz be kell jelentkezni
nyilvan ilyen esetben keruljuk el az automatikus inditast es bizzuk a "fonokre" (ertsd: human)
- A hozzászóláshoz be kell jelentkezni
Ha nincs otthon, akkor a magasabb rendelkezésre állás miatt beindítja a második gépet is, volt az alapvetés. Én mondjuk azt csinálnám, hogy alapvetően az "a" gép lenne a master, akarom mondani elsődleges és a "b" gép a sla... izé, másodlagos kiszolgáló.
Power off/on esetére beállítanám a b-t, hogy maradjon kikapcsolt állapotban, a-t pedig hogy kapcsoljon be. Ezzel az áramszünet után csak az "a" gép indul el, és riasztja a gazdát, hogy oldja meg a helyzetet (Humán quorum).
Automatizálva meg azt lehet, hogy ugyanígy csak az "a" bootol fel, de szolgáltatások nélkül, majd elindítja a "b"-t, és vár x percet, hogy az is elinduljon (link a direkt kábelen, illetve a b ip-je válaszoljon mondjuk ssh-n).
Ez után az "a" meg kell nézze, melyik gép volt az, aki legutóbb a szolgáltatásokat "vitte" (hol van frissebb "i_am_the_master" állapot rögzítve (ezt az elsődleges kiszolgálónak kell lokálisan és rendszeresen touch-olni pl.)), és azt az állapotot kell scriptelve visszaállítani. Ezzel az áramszünet előtti "borulás" is kezelve van.
- A hozzászóláshoz be kell jelentkezni
"Tehát így megoldottam az automatikus mentést is." - redundacia != backup, csak mondom (ez alapjan, mar az elso gepeden is van mentes)
- A hozzászóláshoz be kell jelentkezni