Sziasztok!
Szeretném a segítségetek kéri. Adott egy régi HP Proliant DL360 G4 szerver 2 db 72.8-GB 10K ULTRA320 SCSI HHD-vel hardwares RAID1-ben.
Eddig Debian 6 futott rajta gond nélkül. A Debian 7 kiadása után újra lett telepítve. Ekkor kezdődtek a bajok.
A szerver többször az alábbi hibaüzenettel elszállt.
"echo 0 > /proc/sys/kernel/hung_task_timeout_sec" disables this messages.
http://kepfeltoltes.hu/130514/IMG00457-20130513-0757_www.kepfeltoltes.h…
{kind=link}
Érdekesség képen megnéztem, hogy mekkora a HDD használat.
Az alábbi eredményt kaptam:
bwm-ng v0.6 (probing every 0.500s), press 'h' for help
input: disk IO type: rate
/ iface Rx Tx Total
==============================================================================
fd0: 0.00 KB/s 0.00 KB/s 0.00 KB/s
ccissc0: 1133059.91 KB/s 10720950.39 KB/s 11854010.30 KB/s
ccissc0: inf KB/s -nan KB/s inf KB/s
ccissc0: inf KB/s inf KB/s inf KB/s
ccissc0: inf KB/s -nan KB/s inf KB/s
sr0: 0.00 KB/s 0.00 KB/s 0.00 KB/s
------------------------------------------------------------------------------
total: 0.00 KB/s 479.04 KB/s 479.04 KB/s
http://kepfeltoltes.hu/130514/debian_www.kepfeltoltes.hu_.png
{kind=link}
Azt szeretném megkérdezni, hogy miként tudnám kideríteni, hogy mi használja ilyen bődületesen a HDD-t?
Jelenleg 32bites a rendszer és ext4 a fájlrendszer a szerveren.
Minden segítséget előre köszönök!
- 12286 megtekintés
Hozzászólások
pl.: iotop
Ezzel csak anniy a gubanc, hogy real-time kell nézned, nem logol (max a kimenet irányítható fájlba, de az nem lesz valami szép).
- A hozzászóláshoz be kell jelentkezni
Szia!
Tökéletes, pont ilyenre volt szükségem. Meg is találtam, hogy a munin-graph és a munin-html dolgozik ilyenkor a HDD-re. Volt pár RRD amit nem tudott feldolgozni.
Érdekes minden esetre, hogy ha a cron futtatja a munin-html-t és a munin-grap-ot akkor az össze core 100%-on pörög.
Köszönöm a segítséged!
- A hozzászóláshoz be kell jelentkezni
Ismerős eset. Munin sajnos rajzoláskor nagyon meg tudja húzni a gépet. Érdemes még esetleg megnézni, hogy a muninban az io plugin fent van-e, sok disk/partíció esetén tud ám zabálni. Egy kisebb szerveren nekem az io plugin eltávolítása oldotta meg a kérdést (nem örültem neki, de ez van sajnos).
- A hozzászóláshoz be kell jelentkezni
Minden szerveren be van állítva az iostat plugin. Megnézem, hogy segít-e majd a plugin eltávolítás. Igaz nem sok partíció/disk van bennük. De egy próbát megér.
- A hozzászóláshoz be kell jelentkezni
most rajzoláskor vagy IO plugin?
vagy vagy helyett ÉS van?
úgyértem nekem központi munin "collector" van a helyi gépeket csak lekérdezi.
(bár néhol a XEN-es virtgépeknél az IO nem jön át)
- A hozzászóláshoz be kell jelentkezni
A tárgyal kis teljesítményű gépen van a teljes munin, nincs külön gép az adatfeldolgozásra. Természetesen adatgyűjtéskor ölte meg a gépet az IO plugin, mivel ezen a gépen baromi sok logical volume van (ne kérdezd az okokat, így van). Aztán persze a rajzolás is elég sok volt neki, mivel ugyebár munin szinte mindent külön RRD-be pakol és ezeket illik kikérdezni is, hogy rajzolhasson belőle.
- A hozzászóláshoz be kell jelentkezni
ionice -c3 sokat tud segíteni ilyen esetben
--
Gábriel Ákos
http://i-logic.hu
- A hozzászóláshoz be kell jelentkezni
Gondolkodtam én is prioritás állításon, de aztán nem foglalkoztam a dologgal, a gép használata elég statikus, terhelésnövekedés nem lesz rajta.
- A hozzászóláshoz be kell jelentkezni
munin-t kéne ionice-al kezelni, akkor a többi processzek is tudnának diszkhez jutni
--
Gábriel Ákos
http://i-logic.hu
- A hozzászóláshoz be kell jelentkezni
értem én, max a válaszom nem volt egyértelmű :)
- A hozzászóláshoz be kell jelentkezni
a munin-html cgibe pakolása valamiért nekem nem jött össze rövid idő alatt, viszont a munin-graph viszonylag sima ügy. Ha nem nézed folyamatosan a grafikonokat, akkor fölösleges minden 5 percben legenerálni őket. (a htmlt is, csak azt nem triviális, 2.0 muninban is kísérleti)
- A hozzászóláshoz be kell jelentkezni
Elsőnek apt-get install atop
Aztán ha akarsz logolást, akkor a /etc/init.d/atop-ban állíts be valami szimpatikus értéket ebben a sorban:
DARGS="-a -w /var/log/atop.log 120"
/etc/init.d/atop restart. Később vissza lehet venni, mert jó eséllyel riasztó mennyiségű logot tud csinálni.
- A hozzászóláshoz be kell jelentkezni
Szia!
Köszönöm szépen a hasznos tippet. A biztonság kedvéért beállítottam a logolást, pár napig biztos nézni fogom.
- A hozzászóláshoz be kell jelentkezni
Szia!
Nálam ez a jelenség Debian 5-ről -> Debian 6-ra történő átállásnál kezdődött és tart a mai napig. Általában hetente elő szokott fordulni egy ilyen túlcsordulás (Workaround: iLO reboot).
http://cvk.hu/kep/host-hiba.jpg
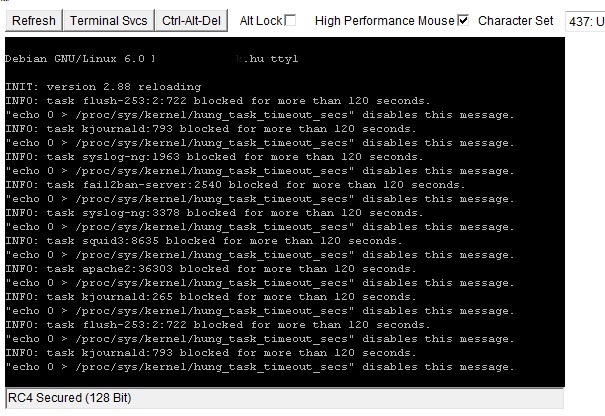{kind=link}
Feltételeztem, hogy a hiba okát az új kernelben lévő hibás cciss driver okozza, és mivel másnál is előjöhetett és bejelenthették többen, így talán majd a 7 kiadásban megjavul. A te mostani panaszod alapján úgy tűnik, rosszul gondoltam.
A HP SMH Smart Array Controller nem jelez semmilyen hibát sem esemény előtt sem utána.
http://cvk.hu/kep/hp-smh-hdd.jpg
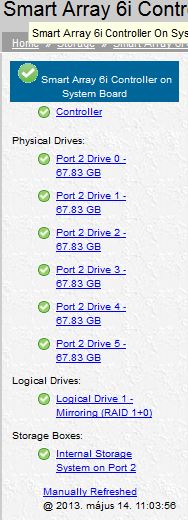{kind=link}
HP DL380 G4, Deb6 64 bit, ext3.
Jelenleg egy komplett gépcsere van kilátásba helyezve, a csereterv egy Ml110 G6 lenne.
- A hozzászóláshoz be kell jelentkezni
Szia!
Nálam ez a hiba nem jelentkezett Debian 6 alatt. Arra gondoltam, hogy annó én non-free telepítőt használtam a 6-os telepítésénél.
A 7-es Debian-t nem non-free telepítővel telepítettem.
Próbaképen feltettem a firmware-linux-free és a firmware-linux-nonfree csomagokat és a 32bites kernelt lecseréltem 64bites-re.
Az a furcsa még az egészben, hogy teljesen kiszámíthatatlan a hiba. Hol bír a gép 3-4 napot, hol pedig csak 1-2 órát. Rém bosszantó.
Ha minden kötél szakad, akkor sajnos nálam is gépcsere lesz.
Köszönöm, hogy megosztottad a tapasztalataidat.
- A hozzászóláshoz be kell jelentkezni
en is kuzdok egy ilyen :hung timeout 120 sec" problemaval.
centos 5.8, intel alaplap, 4x wd raid edition diszk, alaplapi raid, 16 GB ram.
teljesen random mod fagyott, volt hogy orankent, volt hogy kibirt ket honapot.
sokmindennel probalkoztam, de csak az a workaround segitett valamennyit, hogy a mysql tempet ramdiskre tettem, igy mar "csak" 120+ naponkent rohad le.
- A hozzászóláshoz be kell jelentkezni
Ezek teljesen fals számok, remélem látod.
iostat 5 szerintem reálisabb eredményt ad, és ott is inkább a tps a lényeg, mint a kb/s.
Egyébként mit jelent az, hogy a szerver "elszállt" ?
Ez a hibaüzenet annyit jelent, hogy ez a bizonyos taszk 120 sec-ig nem jutott diszkhez (valaki más megette).
Elsősorban hw hibára gondolnék, másodsorban driver hibára.
BBU megy egyébként még ebben a régi gépben? Ha az megállt, onnantól nem használja a raid controlleren a cache-t, baromi tetű lesz tőle a gép.
--
Gábriel Ákos
http://i-logic.hu
- A hozzászóláshoz be kell jelentkezni
Szia!
A kapott számok ténylegesen valótlanok. Az iotop-al reális értékeket kaptam.
Az elszállt alatt azt értettem, hogy a szerver ping, de nem tudok ssh-n és konzolon bejelentkezni.
A monitoron pedig a fenti hibaüzenettel van teli, újabb hibákat pedig nem ír a monitorra.
Nem reagál semmire, csak a hard reset marad.
A raid controllert teszteltem, elég sok fájlművelet van a diskeken napközben.
- A hozzászóláshoz be kell jelentkezni
BBU megy?
hpacucli megmondja.
amúgy meg ilyet a már félig döglött de a raidből éppen még ki nem dobott diszkek szoktak produkálni. ebben az a ciki, ha a jó diszket húzod ki, akkor borul a gép és a rajta levő adat.
smartctl -el esetleg még körül lehet nézni, hátha valamelyik érték gyanús.
--
Gábriel Ákos
http://i-logic.hu
- A hozzászóláshoz be kell jelentkezni
ja igen és mennyi a tps?
80-100 körül bírnak a diszkek, ha tartósan ennyi vagy efölött van, akkor van a gond.
ha megy a bbu, akkor amíg a cache kapacitása bírja (512mb mondjuk) addig 800-at is elvisz.
ha ssd lenne benne, annak a 80000 sem gond :)
--
Gábriel Ákos
http://i-logic.hu
- A hozzászóláshoz be kell jelentkezni
Az alábbi adatokat kaptam:
root@netcheck:/home/user# setarch x86_64 --uname-2.6 hpacucli ctrl all show config detail
Smart Array 6i in Slot 0 (Embedded)
Bus Interface: PCI
Slot: 0
RAID 6 (ADG) Status: Disabled
Controller Status: OK
Hardware Revision: Rev B
Firmware Version: 2.84
Rebuild Priority: Low
Expand Priority: Low
Surface Scan Delay: 15 secs
Surface Scan Mode: Idle
Post Prompt Timeout: 0 secs
Cache Board Present: True
Cache Status: OK
Accelerator Ratio: 100% Read / 0% Write
Total Cache Size: 64 MB
No-Battery Write Cache: Disabled
Battery/Capacitor Count: 0
SATA NCQ Supported: False
Array: A
Interface Type: Parallel SCSI
Unused Space: 0 MB
Status: OK
Logical Drive: 1
Size: 67.8 GB
Fault Tolerance: RAID 1
Heads: 255
Sectors Per Track: 32
Cylinders: 17433
Strip Size: 128 KB
Status: OK
Array Accelerator: Enabled
Unique Identifier: 600508B1001FFFFFA011B405CE440007
Disk Name: /dev/cciss/c0d0
Mount Points: None
OS Status: LOCKED
Logical Drive Label: A011B405CE44
Mirror Group 0:
physicaldrive 1:0 (port 1:id 0 , Parallel SCSI, 72.8 GB, OK)
Mirror Group 1:
physicaldrive 1:1 (port 1:id 1 , Parallel SCSI, 72.8 GB, OK)
physicaldrive 1:0
SCSI Bus: 1
SCSI ID: 0
Status: OK
Drive Type: Data Drive
Interface Type: Parallel SCSI
Transfer Mode: Ultra 320 Wide
Size: 72.8 GB
Transfer Speed: 320 MB/Sec
Rotational Speed: 10000
Firmware Revision: HPB2
Serial Number: AAL1P570AUG40529
Model: COMPAQ BD0728856A
physicaldrive 1:1
SCSI Bus: 1
SCSI ID: 1
Status: OK
Drive Type: Data Drive
Interface Type: Parallel SCSI
Transfer Mode: Ultra 320 Wide
Size: 72.8 GB
Transfer Speed: 320 MB/Sec
Rotational Speed: 10000
Firmware Revision: HPB2
Serial Number: AAL1P570AU1R0529
Model: COMPAQ BD0728856A
Tps:
root@netcheck:/home/user# dstat --disk-tps
-dsk/total-
reads writs
1 120
0 218
0 58
0 504
0 48
0 44
0 44
0 32
0 502
0 48
0 70
0 44
0 44
0 342
0 614
0 42
0 52
0 48
0 46
0 494
0 54
0 40
0 42
0 42
0 616
0 826
0 32
0 50
0 56
0 38
0 600
0 46
0 46
0 48
0 38
0 328
0 44
0 48
0 44
0 20
0 262
0 62
0 42
- A hozzászóláshoz be kell jelentkezni
1. dstat -ot nem ismerem. Nekem kicsit gyanús hogy nulla darab read-ot mér.
2. a write-ok (ha helyesek) akkor pl. a 600 az borzasztó sok
3. nem értem miért nem tudsz egy iostat kimenetet idetolni
4. a hpacucli kimenet szerint nincs BBU-d (tehát a battery nem is bírt tönkremenni, nem az a baj)
5. a raid1 vezérlő miatt a diszkeken levő cache ki van kapcsolva
6. így csak az a 64mb read cache van amit a hpacucli mond
7. tehát ne csodálkozz, hogy borzasztó szarul ír a rendszer
A jelen konfiggal jobban járnál ha JBOD módban használnád (ekkor a diszkeken levő cache-t vissza lehet kapcsolni) és a Linux-szal csináltatnál md RAID1-et, legalább tudna írni.
Vagy veszel bele BBU-t.
--
Gábriel Ákos
http://i-logic.hu
- A hozzászóláshoz be kell jelentkezni
Ez tényleg kimaradt:
root@netcheck:/home/user# iostat
Linux 3.2.0-4-amd64 (netcheck) 2013-05-24 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
4,56 13,43 2,93 1,40 0,00 77,68
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
cciss/c0d0 60,19 2,52 1095,30 615011 267002832
Valamit nagyon elszúrhattam:
root@netcheck:/home/user# dstat --disk-tps --top-io-adv --disk-util --top-bio-adv
-dsk/total- -------most-expensive-i/o-process------- c0d0 ----most-expensive-block-i/o-process----
reads writs|process pid read write cpu|util|process pid read write cpu
0 184 |mrtg.cfg 255153058k2755k6.8%|60.0|mrtg.cfg 25515 0 2960k6.8%
0 186 |mrtg.cfg 255153123k2742k7.2%|60.4|mrtg.cfg 25515 0 2984k7.2%
0 144 |mrtg.cfg 255152677k2415k6.8%|46.4|munin-update 25517 0 5276k 23%
0 152 |munin-cron 255143483k2305k 0%|46.0|munin-cron 25514 0 29M 0%
0 194 |mrtg.cfg 255152468k2201k6.5%|50.8|mrtg.cfg 25515 0 2380k6.5%
0 164 |munin-html 262797040k 40k 21%|52.8|mrtg.cfg 25515 0 2680k6.8%
0 160 |munin-html 262796784k 40k 22%|51.2|mrtg.cfg 25515 0 2592k6.8%
0 172 |mrtg.cfg 255152240k1930k6.2%|56.8|munin-html 26279 0 2576k 22%
0 166 |mrtg.cfg 255152122k1840k6.5%|52.8|mrtg.cfg 25515 0 2004k6.5%
0 174 |mrtg.cfg 255152028k1740k6.0%|60.8|mrtg.cfg 25515 0 1904k6.0%
0 164 |mrtg.cfg 255151972k1700k6.5%|57.6|mrtg.cfg 25515 0 1856k6.5%
0 180 |mrtg.cfg 255152283k1972k6.5%|59.6|mrtg.cfg 25515 0 2156k6.5%
0 188 |mrtg.cfg 255152312k2024k6.5%|58.8|mrtg.cfg 25515 0 2220k6.5%
0 170 |mrtg.cfg 255151950k1689k6.2%|57.2|mrtg.cfg 25515 0 1840k6.2%
0 204 |mrtg.cfg 255151712k1476k5.5%|56.8|mrtg.cfg 25515 0 1612k5.5%
0 166 |mrtg.cfg 255151859k1608k6.0%|52.0|mrtg.cfg 25515 0 1756k6.0%
0 166 |mrtg.cfg 255151802k1565k6.2%|53.2|mrtg.cfg 25515 0 1708k6.2%
0 174 |mrtg.cfg 255151774k1529k5.8%|51.2|mrtg.cfg 25515 0 1676k5.8%
0 952 |mrtg.cfg 255151097k 965k3.5%|80.4|mrtg.cfg 25515 0 1048k3.5%
0 1400 |mrtg.cfg 25515 327k 282k0.8%| 100|mrtg.cfg 25515 0 312k0.8%
0 1028 |mrtg.cfg 25515 265k 223k1.2%| 101|mrtg.cfg 25515 0 244k1.2%
0 1508 |mrtg.cfg 25515 528k 456k1.8%| 101|mrtg.cfg 25515 0 496k1.8%
0 1128 |mrtg.cfg 255151233k1076k4.0%|80.4|mrtg.cfg 25515 0 1172k4.0%
0 192 |mrtg.cfg 255151836k1582k6.0%|57.6|mrtg.cfg 25515 0 1732k6.0%
0 218 |mrtg.cfg 255151865k1604k6.0%|68.0|mrtg.cfg 25515 0 1752k6.0%
0 194 |mrtg.cfg 255151917k1663k6.2%|56.0|mrtg.cfg 25515 0 1804k6.2%
0 168 |mrtg.cfg 255152116k1852k6.8%|52.0|mrtg.cfg 25515 0 2008k6.8%
0 834 |munin-cron 25514 18M5628k 0%|80.4|munin-cron 25514 0 5800k 0%
0 584 |mrtg.cfg 255151888k1633k6.2%|69.6|mrtg.cfg 25515 0 1780k6.2%
0 202 |mrtg.cfg 255152053k1773k6.2%|66.8|mrtg.cfg 25515 0 1928k6.2%
0 196 |mrtg.cfg 255152161k1862k6.2%|62.4|mrtg.cfg 25515 0 2032k6.2%
0 210 |mrtg.cfg 255152433k2096k6.8%|64.0|mrtg.cfg 25515 0 2288k6.8%
0 200 |init [2] 1 2800k3231k 0%|56.4|init [2] 1 0 3800k 0%
0 1008 |mrtg.cfg 255151820k1582k4.5%|85.6|mrtg.cfg 25515 0 1716k4.5%
0 206 |mrtg.cfg 255152301k2001k6.5%|55.6|mrtg.cfg 25515 0 2172k6.5%
0 198 |mrtg.cfg 255152649k2288k6.8%|49.6|mrtg.cfg 25515 0 2496k6.8%
0 172 |mrtg.cfg 255152639k2316k7.0%|44.4|mrtg.cfg 25515 0 2500k7.0%
0 192 |mrtg.cfg 255152658k2284k7.0%|51.2|mrtg.cfg 25515 0 2500k7.0%
0 696 |mrtg.cfg 255152053k1773k5.2%|74.4|mrtg.cfg 25515 0 1940k5.2%
0 196 |mrtg.cfg 255152482k2153k6.0%|57.6|mrtg.cfg 25515 0 2336k6.0%
0 192 |mrtg.cfg 255152649k2299k7.0%|55.2|mrtg.cfg 25515 0 2496k7.0%
0 190 |mrtg.cfg 255152473k2138k6.8%|54.8|mrtg.cfg 25515 0 2340k6.8%
0 196 |mrtg.cfg 255152716k2350k7.0%|57.6|mrtg.cfg 25515 0 2560k7.0%
0 504 |mrtg.cfg 255152456k2147k6.2%|69.6|mrtg.cfg 25515 0 2320k6.2%
Erősen gondolkodom egy újratelepítésben.
- A hozzászóláshoz be kell jelentkezni
2.6.35-tol (ha emlekem nemcsal) van uj driver a smartarraynak, d7-ben meg joval frissebb kernel van. probald meg azzal
--
A vegtelen ciklus is vegeter egyszer, csak kelloen eros hardver kell hozza!
- A hozzászóláshoz be kell jelentkezni
Frissíthető a raid vezérlő és/vagy BIOS?
- A hozzászóláshoz be kell jelentkezni
Szia!
Sem a logolás sem a kernel csere nem oldotta meg a problémát. Kisebb terhelés mellett tovább bírta a gép.
2005-ös BIOS van a szerverben. A mai nap folyamán megpróbálom frissíteni.
- A hozzászóláshoz be kell jelentkezni
Én előszőr is megnézném, hogy mekkora rrd és png fájlok keletkeznek összesen. Nálam ez nagyobb volt mind 10GB, amit kicsit sok kiírni 5 percenként.
Két dolgot tettem:
1. beállítottam az rrdcache daemont.
2. a cron helyett munin-cgi-graph és munin-cgi-html beállítást használtam.
Így jelentősen lecsökkent az IO és csak akkor készíti el a png képeket, ha éppen meg akarod nézni.
- A hozzászóláshoz be kell jelentkezni
A szerver többször az alábbi hibaüzenettel elszállt.
"echo 0 > /proc/sys/kernel/hung_task_timeout_sec" disables this messages.
Ez nem a hibaüzenet. Sőt, ezzel a sorral tudod elérni, hogy a felette lévő INFO üzeneteket ne írogassa a konzolra.
- A hozzászóláshoz be kell jelentkezni