Tud valaki valamit hogy a hardverapro és prohardver oldalakkal mi van?
- 14220 megtekintés
Hozzászólások
Gyors helyzetjelentés, sajnos semmi igazán lelkesítőt nem tudunk írni:
- az adatbázisszerveren hardveres hiba lépett fel, ami jelenleg úgy fest, hogy a februárban upgrade-elt processzorhoz köthető
- ez a hiba magával rántotta a teljes adatbázist, a könyvtárstruktúra is sérült
- a hardveres rendszert sem tudtuk helyreállítani mostanáig, eleinte jónak tűnt, de aztán a recovery-be is beleborult
- visszakerült a régi cpu, és most tűnik először stabilnak a gép
- telepítődik a rendszer, másolódnak az adatok (egy-egy rész másolása is 4-5 óra)
- ha minden fent van, utána tudjuk csak elkezdeni megnézni, hogy az elvileg meglévő adatok gyakorlatilag is megvannak-e, tényleg minden el tud indulni stb.
Sajnos ezen a ponton biztosra kizárni az adatvesztést nem tudjuk (de reméljük, hogy elkerüljük), ahogy azt sem, hogy mikor lesz ebből újra működő lapcsalád. Ma nem túl valószínű.
Nagyon sajnáljuk!
Update: látjuk a rosszindulatú feltételezéseket, "legyen végetek" jellegű kommenteket, "én otthon fél nap alatt egy Pentium 2-n megoldom" vonalat is. Ezekre nem fogunk reagálni, nem nagyképűségből, hanem mert nincs rá erő és értelme sincs. Cikk az egészről lesz majd, csak tartsunk már ott...
- A hozzászóláshoz be kell jelentkezni
Majd legközelebb kiszervezik olyanoknak az üzemeltetést, akik profik.
- A hozzászóláshoz be kell jelentkezni
Az nem mondanám, hogy profik, de 24 éve üzemeltetik az oldalt. Mondjuk nekem kicsit bullshitnek tűnik, hogy a procit hibáztatják. Az a legritkább esetben hibás hardver, ritka, mint a fehér holló, hogy egy proci hibás, ha pedig hibás is, az még ritkább, hogy valami rejtett hibája legyen, és na azonnal legyen tégla, vagy ne fagyjon azonnal, ne essen ki memóriacsatorna, stb., tehát az esetek többségében azonnal érzékelhető. Hacsak nem 14. genes i7-i9 asztali prociról hajtották, illetve most volt egy Asrock AM5 alaplap is, ami odaégette a procit rossz feszelés miatt, de ennek kicsi az esélye, mert ezek konzumer/home hardverek, nem szervernek valók.
Ez a lekicsinylő, otthon P2-őn megoldom kezdetű leoltás is elég tróger, hiába teszi oda, hogy nem nagyképűségből, de nagyképűségből írja, lesüt róla. Mert ők jobban értenek hozzá. Vagyis mint az ábra mutatja, lehet, hogy mégse.
Mindegy, mert nem látogatom az oldalt. Nem élek otthon, így a hardveraprón nem veszek semmin, a fórumukat egy jó 15 évig látogattam, de teljesen elvetette a sulykot a moderálás, random törölgetnek hozzászólásokat, indoklás nélkül, a moderátor és a topikgazda is, már több esélyt kaptak, mire megelégeltem, hogy szopatnak, felesleges bittemetőbe írogatni. Ha az utóbbit akarnám, csak beleírnám egy text editorba, amit mentés nélkül bezárnék vagy elmenteném a /dev/null-ba.
“Windows 95/98: 32 bit extension and a graphical shell for a 16 bit patch to an 8 bit operating system originally coded for a 4 bit microprocessor, written by a 2 bit company that can't stand 1 bit of competition.”
- A hozzászóláshoz be kell jelentkezni
Hagyd már. feszelés, meg AM5 meg ilyenek. Servers are cattle, not pets. Egy ilyen dolgot régóta eleve virtualizáltan/konténerizáltan, urambocsá felhőben futtatsz. Még ha saját felhőben, akkor is. De ezt külföldi felhőben üzemeltetni triviális dolog, és nem is drága.
Meghal az egyik hardver? Le van szarva, minden redundáns, majd a többi gép kiszolgálja, a hibás hardvert meg lehet menet közben cserélni.
Főleg, hogy ők ebből éltek, bevételi forrásról beszélünk, nem egy hobbiprojektről.
- A hozzászóláshoz be kell jelentkezni
Persics Mérnök Úr, szerintem jelentkezz hozzájuk cloud-evangelistának.
Le™ vannak™ maradva™, lehetnél számukra a fejlődés™ nagykövete.
- A hozzászóláshoz be kell jelentkezni
Mondjuk persicsb mellett szól, hogy azóta eltelt egy újabb nap, és ugyanúgy áll az egész.
Nem mondom, hogy felhőbe kell rakni mindent, mert a felhő az mégis csak egy szép szó arra, hogy egy olyan gép, amiről nem tudod hogy hol van, és pontosan mi fut rajta.
De azért ahol a saját hardveren futtatott kritikus szolgáltatás 2 napra leállhat csak úgy, ott azért lehet meg kellene fontolni a felhőt is (legalább "backup" szervernek).
Nagy Péter
- A hozzászóláshoz be kell jelentkezni
Nem kell ide felhő. Ha van mentés, vissza lehet tolni a tartalék vasra, amit aznap vesznek a sarki PC boltban. Szerintem a hardver hiba csak egy fedősztori.
- A hozzászóláshoz be kell jelentkezni
Szerintem sem kell ide felhő. Inkább sokakat meglep, hogy évtizedek óta ebből élnek, és komolyan egy singe-server-en fut az egész?
- A hozzászóláshoz be kell jelentkezni
Nem meglepő, sok helyen látni a "spóroljunk az IT-n" tendenciát. Na itt az egyiknek az eredménye. :-(
- A hozzászóláshoz be kell jelentkezni
Nem ebből élnek, hanem írnak róla, nem is feltétlen erre a szakterületre fókuszálva. Ha nem is feltétlen saas cloud alapon kialakítva, de ez egy elég komoly lapcsalád, és attól még ha a sw stack saját munka, lehetne valami type-1 hypervisoron és virtuális gép(ek)en amit így gyorsan lehet menteni, másik hw-re áttenni az akár húsz éves sw stacket... tudom, nagyon ritkán kell ezzel foglalkozni, de mint látni lehet, akkor nagyon.
- A hozzászóláshoz be kell jelentkezni
Dehogynem ebből élnek. Az egész "lapcsalád" hardverapróstul / mobilarénástul / prohardverestül / etc ment a levesbe. Jó eséllyel számszerűsíteni lehet az elszenvedett veszteségekt pl. a reklámokból, mert azért elég nagy látogatottságú oldalakról beszélünk. Számomra is tök bizarr, hogy egy jó eséllyel "commodity" x86 hardveren futó rendszert nem lehet mondjuk egy napon belül rendes mentésből visszatölteni valami másik gépre.
- A hozzászóláshoz be kell jelentkezni
A cloud részében nem értek egyet. Igen, a felhős üzemeltetés könnyebb, olcsóbb. Amíg az egész felhős infrastruktúra le nem térdel, lásd nagyobb AWS, MS Azure, MS Outlook leállás, kiesés, aztán várhatsz másra. A saját üzemeltetésű szerver lehet megbízhatatlanabb, de az a saját kontrollod alatt áll, és mivel saját rendszer, a security through obscurity esete is játszik.
Az AM5-öt azért írtam, hogy annak nem kéne ebben szerepet játsszon, az konzumer cucc, nagyon remélem, hogy nem akkora idióták, hogy túlfeszelt asztali prociról viszik az oldalaikat.
Nekem az is morbid, hogy egy backup visszahúzásán mi 4-5 óra 2025-ben? Mikor NVMe tárolók meg több tizen gigabites kapcsolatok vannak. Nekem még az is új, hogy egy hibás proci, hogy sérhet meg egy fennálló mappastruktúrát. Mert az oké, ha az új fájlok meg mappák hibásak, de a régiek hogy sérülhetnek meg?
“Windows 95/98: 32 bit extension and a graphical shell for a 16 bit patch to an 8 bit operating system originally coded for a 4 bit microprocessor, written by a 2 bit company that can't stand 1 bit of competition.”
- A hozzászóláshoz be kell jelentkezni
AM5 böl amugy pont van versenyképes szerver megoldás az epyc 4004 széria képében, vanak hozzá rendes szerver vasak, meg kapsz külön táblát is. Pofás kis cucc :)
- A hozzászóláshoz be kell jelentkezni
Amíg az egész felhős infrastruktúra le nem térdel, lásd nagyobb AWS, MS Azure, MS Outlook leállás, kiesés, aztán várhatsz másra
Jah, csak közben a topik lényege, hogy ~74 órája nincs prohardver. :)
és mivel saját rendszer, a security through obscurity esete is játszik.
ROTFL
- A hozzászóláshoz be kell jelentkezni
Ezt a cloudban ugyanugy elo tudtak volna idezni.
Ott is esnek-kelnek az instance-ok.
Nem ettol jobb v. rosszabb az egyik v. a masik. Mindegyiknek megvan a maga baja, limitacioja.
- A hozzászóláshoz be kell jelentkezni
Az elterjedtebb felhős szolgáltatóknál aktívan el kell rontanod az adataidat, hogy rossz legyen. Mert egyébként alapból van redundancia és rendelkezésre állás vállalás. Eleve lehet snapshotokat és backupokat is készíttetni.
De az, hogy elromlik egy szerver és ezért napokig nem sikerül újraindulni, olyan nem lehet felhős szolgáltatóval. Max ha kitör a világháború vagy ufótámadás lesz, vagy globális katasztrófa történik és a csótányok veszik át a hatalmat.
Ha nem saját maguknak rontják el az adatokat szoftveresen, akkor a redundancia is adott. Akár különböző adatközpontokban futtatva is. Szóval minden csak azon múlik, hogy mennyire akarnak biztosra menni. Ha néha történik is kiesés, az max szünet, adatvesztés nagyon ritka. De a nagyon ritkát is ki lehet kerülni, ha fontos, több adatközpont, több régió vagy akár több különböző felhős szoglátató használatával is. Attól függ mennyit szánnak rá és milyen fontos.
A PH úgy tűnik nem ezzel játszik egy ligában, hanem valami szerverszobában, esetleg szerverhotelben álló gépről van szó, redundancia és hibatűrés nélkül.
- A hozzászóláshoz be kell jelentkezni
Erted, hogy amit irsz, azok adotttak v. adottak lehetnek a nem cloud providereknel vagy epp irrelevans?
> mert egyébként alapból van redundancia
Vagy van, vagy nincs. De igazabol tokmind1, sehol nincs 100%-os garancia. Onnantol meg dobalozas a szamokkal
> és rendelkezésre állás vállalás.
A Foldon nem letezik olyan szolgaltato, amelyiknel nincs rendelkezsre allas vallalas. De meg ha lenne, akkor se jelentene semmit, mert nincs osszefugges a vallalas es a gyakorlat kozott (mint ahogy a topic is egy olyanbol kepzodott, hogy vki vallalt vmit, aztan megis szopo lett belole).
> olyan nem lehet felhős szolgáltatóval.
Na kivele, meseld el, miert nem lehet. Ne azt, hogy mennyire valoszinu, hanem hogy ki-van-zarva.
Azt is mondd el pls, hogy egy hagyomanyos szolgaltatoval miert *lehet*.
> Max ha kitör a világháború vagy ufótámadás lesz
Amikor vki ilyen vakon bizik egy cloud (3rd) szolgaltatoban, azt en messzire kerulom, sot kifizetodo kerulni.
> a redundancia is adott. Akár különböző adatközpontokban futtatva is.
OK, akkor egyelore ott tartunk, hogy a lehetoseg adott. Jo esetben olyan szolgaltatast is vesz az ember, ahol ez a redundancia ki sem lehet kapcsolni. Akkor mar csak annyirol van szo, hogy vajon a redundancia mennyire valtja ki a backupot. De majd mindjart elmondod:)
Lehetoleg azert almat az almaval hasonlitsuk ossze es ne mondjuk S3-at a lokalisan posix FS-en tarolt adatokkal. OK?:)
> adatvesztés nagyon ritka.
Nahat, most meg mar ritka.
Igazabol on premise is ritka am:)
> több régió vagy akár több különböző felhős szoglátató
Hubakker, itt meg mar egy multi-cloud architekturat bedobtal gyorsan.
Szoval ott tartunk, hogy kisujjbol kirazta az emberke a PH szukseges architekturat, rentabilisan, funkcionalisan, meg ahogy kell. Nem lehet, h forditva ulsz a pacin?
> esetleg szerverhotelben álló gépről van szó, redundancia és hibatűrés nélkül.
Leirtak masok, hogy nem a redundancia es a hibatures hibadzik. A ketto kozott mi amugy a korrelacio, miert soroltad fel mind2-t. Mert jol hangzik?:)
- A hozzászóláshoz be kell jelentkezni
amazanon, google és ms cloudban is alapvető, hogy redundáns clusterekben futnak a vm-ek, szolgáltatások, amiknél rögtön máshová kerül át a folyamat probléma esetén. És ezt lehet még tovább fokozni azzal, hogy az alkalmazásokat is úgy állítjuk be, hogy azok redundánsan fussanak. És úgy veszem fel a vm-eket, hogy több adatközpontban, több régióban fussanak, ha olyan rendelkezésre állás kell.
Nem 100% rendelkezésre állásról van szó, csak sokkilencesről. A pisikebt szobájában futó gép meg addig fut amíg nincs baj, aztán meg nem fut. A szerverhotelben ülő gép is csak annyiból jobb ennél magában, hogy ott általban az áram és a net redundáns legalább. De a gépek redundanciáját ott neked kell biztosítani. Gondolom nem érted a különbséget a között, hogy egy szál vas ül és addig megy amíg a sors másképp nem gondolja vagy pedig kifejezetten redundánsra kiépített vm környezet van. Jaj de ezek biztos csak buzzwördök neked, ha ennyre nem érted. Remélem legalább döntéshozó pozícióban vagy és előadod ezt a szakértelmet akkor is, amikor a cégetek rendszereinek futtatásáról van szó.
Nem vakon bízom a szolgáltatóban, hanem tudom, hogy a baszott nagy szerverparkjaikban baszott sok szervert futtatnak évtizedek óta és kifejzetten ezzel foglalkozó szakembergárdájuk van. Ismert, hogy mikor milyen leállásaik voltak és az is ismert, hogy a nagyon ritkán beütő problémáknat hogyan lehet elkerülni (több központba széttett feladattal pl).
Nem ülök fordítva a lovon, hanem esetleg jobban értek hozzá, mint te. De itt vagy a másik topicban is elolbashatod pl Frankó leírását is arról, hogy ő milyen redundáns és többlábon álló rendszert üzemeltet szolgáltatóknál és mi az ára. Az is egy jó példa, valsz jobban ért hozzá nálam. Árban pedig a méretgazdaságosság és az, hogy nem kell erre külön csapatot felvenni, az is kedvezővé teszi a felhős szolgáltatás igénybevételét. Meg persze a mentésekhez, visszaállásokhoz is kész megoldásokat adnak. A mentés arra kell, hogy ha vissza kell állni, legyen hová. A redundancia arra kell, hogy lehetőleg ne kelljen visszaállni.
Ha akkora kapacitás kell, aminél már megéri fenntartani komolyabb csapatot, akkor érdemes helyi vassal, szerverteremmel foglalkozni. Vagy ha nincs semmi pénz és pistike megoldja, de az akkor lutri.
Nem tudom ki képzeli azt, hogy a ph esetén nem redundancia és hibatűrés volt a baj, amikor pont a redundancia és a hibatűrő rendszer hiánya miatt áll az egész cégük kedd óta.
- A hozzászóláshoz be kell jelentkezni
ok, kar volt idejonnom
ezzel cseszni az idot ilyen melegben, bakker, en vagyok a marha
- A hozzászóláshoz be kell jelentkezni
tényleg kár volt, de legalább tudjuk, nem téged kell kérdezni ilyen témában
- A hozzászóláshoz be kell jelentkezni
Legalabb ebben egyetertunk.
Hasonloan gondolom rolad:)
- A hozzászóláshoz be kell jelentkezni
De az, hogy elromlik egy szerver és ezért napokig nem sikerül újraindulni, olyan nem lehet felhős szolgáltatóval.
Ó, dehogynem :D Még komplett cég is volt kénytelen bezárni, amikor úgy elbaszták az userek adatait a felhőben, hogy még mentésből sem tudták visszaállítani :D
https://hup.hu/cikkek/20091011/az_ugyfelek_backup_adatainak_majdnem_biz…
Hagyjuk már ezeket misztikumokat.
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
ott sem a mai cloud infrastruktúra szart be, hanem a megvett cég üzemelt valami szaron backup nélkül. Tönkre lehet tenni az adatokat, ha valaki nagyon akarja vagy szándékosan nem használ semmit a rendszer lehetőségeiből és letörli az egy szál vm-ének fájl rendszerét és aktívan minden backup lehetőséget is. De nem a szolgáltató a hülye akkor.
Annak misztikum, aki nem ért hozzá. Vagy nem akar érteni hozzá, mert hagyományos vas üzemeltetős szolgáltatást árul.
Azt viszont elhiszem, hogy van erre is igény. Van, hogy kell egy izzadó csapat, akinek a válla fölött liheghet a manager, aki fontos ember és fontos, hogy fontosnak érezze magát, amikor a fontos döntést meghozza, hogy fontos legyen. Hm, piaci rés: lehetne erre színészeket felvenni, akik eljátszák a hekkert, mint a filmekben, villogó kijelzőkkel és futó szöveggel.
- A hozzászóláshoz be kell jelentkezni
ott sem a mai cloud infrastruktúra szart be,
Lejjebb azt fejtegettétek, hogy már az is felhő, ha valaki bérel egy vasat, ami egy adatközpontban van.
Tönkre lehet tenni az adatokat, ha valaki nagyon akarja vagy szándékosan nem használ semmit a rendszer lehetőségeiből
Vagy kimegy a központi storage - ami minden gép alá adja a tárterületet - szervize, elbasz egy firmware frissítést, elveszik az összes adat, a backup meg nincs/nem használható. Ez is felhő a definícióitok szerint, oszt' mégis ott a szopóka.
Vagy, megeszi a kripto a felhőben levő központi infrát és visz magával mindent is.
Nem mondtam, hogy nem jó a felhő, csak megvilágítottam, hogy abban sem érdemes vakon bízni. A szerződések mögött lehet bármi, főleg akkor, ha a szolgáltató kb. egy havi szolgáltatási díjnyi kötbért vállal, vagy még azt se. A papír sok mindent elbír.
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
"abban sem érdemes vakon bízni."
ez így van, érteni kell ahhoz is. És használni kell a lehetőségeket, de ha valami nagyon fontos, akkor több lábon is lehet állni, akár nem csak egy szogláltatónál.
Ez a szál arról szólt, hogy egy csomó olyan biztosíték van már egy profi szolgáltató rendszerében, amire egy kkv-nak sosem lesz pénze, hogy saját magának hasonlót csináljon. És ezen felül van még az, hogy még tovább fokozható a biztonság. A felsoroltakból egy csomó szintet a szolgáltató biztosít, kifejezetten rosszul kell használni, szoftveres oldalról szétcseszni az adatokat, hogy hasonló helyzet előálljon. Nem hitből, hanem gyakorlati tapasztalatból.
Nem trógek bt sufnijában futó "felhől" volt szó.
- A hozzászóláshoz be kell jelentkezni
Nem trógek bt sufnijában
Ez akkor szokott kiderülni, amikor baj van.
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
lehet be kéne kapcsolnod a szál nézetet :D
- A hozzászóláshoz be kell jelentkezni
A papír sok mindent elbír.
+sok
Ezt már apám is mondogatta 40+ évvel ezelőtt :-)
- A hozzászóláshoz be kell jelentkezni
De az, hogy elromlik egy szerver és ezért napokig nem sikerül újraindulni, olyan nem lehet felhős szolgáltatóval.
Mindhárom nagy cloudnál extra feature, hogy lehessen például cross-region helyreállítást csinálni, és mindenhol vannak megkötések benne.
A GCP-ben például nem tudtál immutable backupot csinálni, csak a védett resource saját régiójában. Ez most nyárra lett csak megcsinálva, valamikor februárban kértem még a GCP illetékes product managerét, hogy ez így nem lesz jó, siessenek vele.
- A hozzászóláshoz be kell jelentkezni
amit írsz az már bőven más szint. A ph esetén egy fiziai szerver nem lehetséges pótlásával küzdöttek a hírek szerint. Az, hogy a gcp infra szarjon be annyira, mint a ph szervere és amiatt legyen több havi adatesztés, az nem valószínű. És persze felhőben is igaz, hogy tudni kell kihasználni a lehetőségeket, ha plusz biztonság kell. Csak ott már az alap is magasabb szintű biztonság, mint az egy szál vas egy szerverszobában. Kifejezetten rosszul kell használni a szogláltatást, hogy hasonló eset előállhasson a gcp-nél is.
Voltak csúnya leállások, amikről utólag írtak szép beszámolókat. Pl az egyik amazon régióban amikor az államban már szükségállapot volt a hurrikán miatt és a többszöri áramszolgáltatói leállások után a generátorok indulásáig nem bírta el a szünetmentes rendszer, mert nem volt ideje újratöltődni és nem gondoltak erre az extrém esetre - hogy ilyenkor inkább szabályos leállás legyen, ne próbáljon élesben maradni. És akkor volt akinek kisebb adatvesztése lehetett. De az is kivédhető volt annak, aki elosztott szolgáltatást nyújtott direkt több adatközpontba széttéve.
Az alapszitu az, hogy biztosítékok nélkül futott a ph. Ennél alapból több biztosíték van a nagy felhős szogláltatásoknál. Szóval a felhős alapszinttel nem állhat elő ez ami lett. Így nem is kell ebből helyreállni, nincs ilyen eset.
És azon felül lehet még sokféle szinten fokozni, hogy adatvesztés vagy egyáltalán üzemszünet esélye mennyire legyen még kisebb. A gcp-nél a véletlen / user hiba miatt letörlom a felhős előfizetés eset áll legközelebb ehhez.
- A hozzászóláshoz be kell jelentkezni
Jaja, világos, a példa inkább arról szólt, hogy a felhős natív backup sem atombiztos (by default), még ha elég sokat is lehet javítani rajta.
- A hozzászóláshoz be kell jelentkezni
Ez így van, mert közben kiderült, hogy ők is az üzemeltetőre várnak, ami lehetne most a felhő is. Tény, hogy innen nézve nem jobb. De ha a saját üzemeltetéstől indulunk, akkor viszont nem lenne 74 órája. Meg ha letérdelés van, akkor nem esne feltétlen egy időbe a globális letrédeléssel. Tény, hogy ez így nem sikertörténet nekik, de ne szólogass be, mert te is megkapod, hogy P2-es szakértő vagy, meg ők jobban értenek hozzá.
“Windows 95/98: 32 bit extension and a graphical shell for a 16 bit patch to an 8 bit operating system originally coded for a 4 bit microprocessor, written by a 2 bit company that can't stand 1 bit of competition.”
- A hozzászóláshoz be kell jelentkezni
Mondjuk nekem kicsit bullshitnek tűnik, hogy a procit hibáztatják. Az a legritkább esetben hibás hardver
Az Intel 13-14 generációját érintő leolvadást figyelembe véve kissé túlzó a kijelentésed.
Ez a lekicsinylő, otthon P2-őn megoldom kezdetű leoltás is elég tróger, hiába teszi oda, hogy nem nagyképűségből, de nagyképűségből írja, lesüt róla. Mert ők jobban értenek hozzá. Vagyis mint az ábra mutatja, lehet, hogy mégse.
Pont ugyanaz, amit te nyomsz állandóan a Linux CLI-ddel. Egyébként honnan tudod, hogy P2-n ne tudná jobban megoldani? :P Még az is stabilabb, mint az Intel multika szarul-húgyul implementált, leolvadó processzora.
- A hozzászóláshoz be kell jelentkezni
Nem túlzó, pont arra céloztam, hogy 13-14. genes procik azok konzmer cuccok, nem szerver üzemeltetésére vannak. Az utóbbi időben csak 2 ilyen procihalálozás volt, az egyik a 14. genes Intel, a másik az az AM5-ös AMD, de annál csak egyetlen egy Asrock alaplap, nem általános, és nem a procihoz köthető. Tehát még egyszer: a procik ilyenkor se hibásak, az alaplap feszeli túl, rossz UEFI beállítás miatt. Ezek a modern procik ugyanis alapból gyárilag tuningoltan túlhajtják magukat, ameddig csak lehet, amíg az alaplap érzi, hogy van még energia-hőkeret (bírja még a táp, alaplapi VRM, a proci még nincs hőlimitnél), addig növeli az órajelet, feszeli felül a procit, hogy minél jobban kihajtsa, ha turbózásra van szükség. Csak ezt, ha nem állítják be, olyan jól sikerül, hogy belefüstöl az egész CPU, már pedig itt a botrányt pont az képezte, hogy a túlfeszelési határokat nem szabta meg rendesen az Intel, az alaplapgyártók meg túl magasra nyomták.
Meg is nyugodhatsz, nekem a Linux CLI-mben nem is tart egy backup visszahúzása 4-5 órákat, meg az én üzemeltetésem alatt, még ha el is q-rok valamit, nem állna egy ilyen oldal már 3. napja lényegében, még egy P2-esen sem. Egyébként meg nem is baj, ha kóklerek, csak akkor ne P2-es analógiás lóról osszák az észt, hanem oldják meg, vagy tényleg menjenek felhőbe, amit én nem támogatok, de idiótáknak könnyebb és olcsóbb az tényleg, minden hátrányával együtt.
“Windows 95/98: 32 bit extension and a graphical shell for a 16 bit patch to an 8 bit operating system originally coded for a 4 bit microprocessor, written by a 2 bit company that can't stand 1 bit of competition.”
- A hozzászóláshoz be kell jelentkezni
"vagy tényleg menjenek felhőbe, amit én nem támogatok, de idiótáknak könnyebb és olcsóbb az tényleg, minden hátrányával együtt."
Ezt amúgy miért kell?
- A hozzászóláshoz be kell jelentkezni
érintő leolvadást figyelembe véve
"a TB nagyságrendű adatbázisunk nem futott volna el egy desktop i7-ről (64 magos enterprise procink van. volt csak hát az meg - valószínűleg nem önmagában, hanem az alaplappal tandemben - nem tette meg azt a szívességet, hogy leállt, hanem működött, néha hibásan, és szétverte az adatokat a könyvtár struktúrával bezárólag az adatbázis-szerveren)." PH FB
Ezt elemezné valaki?
- A hozzászóláshoz be kell jelentkezni
{kind=link}
- A hozzászóláshoz be kell jelentkezni
> 24 éve üzemeltetik az oldalt.
Valójában nem, volt egy váltás menet közben, kb 10 éve átkerült egy másik céghez.
De a hardverhibát nincs üzemeltetés, ami ki tudja zárni, és ha mégoly ritka is egy proci hiba, nem lehetetlen, következésképp ki sem zárható, hogy tényleg egy procihoz köthető dolog okoz gondot.
- A hozzászóláshoz be kell jelentkezni
De a hardverhibát nincs üzemeltetés, ami ki tudja zárni,
Kizárni nem, tenni viszont lehet ellene:
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
aki egy szervert tud venni, az tud 2-t is...
1944. Július 30.
Az amerikai légierő 300 bombázója két szőnyegbombázást hajt végre a szigetszentmiklósi repülőgépgyár ellen. Nádasdladány térségében honi vadászrepülők két B–24 Liberatort lelőnek.
- A hozzászóláshoz be kell jelentkezni
Ezt gyanítottam, de nem tudtam. Szerintem most ők nem oldanak meg semmit, várnak a másik cégre. Akkor ezt mondják, ne P2-esezzenek.
Nyilván az nem zárható ki, hogy a proci, azt nem is mondtam, hogy lehetetlenség, de csillagászatian kicsi az esélye.
“Windows 95/98: 32 bit extension and a graphical shell for a 16 bit patch to an 8 bit operating system originally coded for a 4 bit microprocessor, written by a 2 bit company that can't stand 1 bit of competition.”
- A hozzászóláshoz be kell jelentkezni
tényleg egy procihoz köthető dolog okoz gondot.
A backupok már nem szalagra történnek, amik a fiókban várják, hogy hátha szükség lesz rájuk?
Én Joomláról csináltam csak régen biztonságit, de ott vagy egy Akaeba plugin -al vagy a tárhely /html könyvtárának és az adatbázisnak a lemásolásával.
- A hozzászóláshoz be kell jelentkezni
Ha nem 4 hete futottam volna bele, hasonló proci hibába, én is egyetértenék veled.
Az érdekes, hogy a proci minden szerveres belső teszten átmegy, viszont natív telepítésnél a linux is elpánikol és a windows is kékhalálozik, mindkettő ismeretlen hibával.
( •̀ᴗ•́)╭∩╮
"speciel a blockchain igenis hogy jó megoldás, ezért nagy erőkkel keressük hozzá a problémát"
"A picsat, az internet a porno es a macskas kepek tarolorandszere! : HJ"
Az élet ott kezdődik, amikor rájössz, hogy szart sem kell bizonyítanod senkinek
Ha meg akarod nevettetni Istent, készíts tervet!
- A hozzászóláshoz be kell jelentkezni
Én még nem futottam bele semmilyen CPU hibába személyesen. Egyszer volt egy határeset, 2004-ben, mikor segítettem valakinek gépet összerakni, az vett egy tálcás 3,06 GHz-es 533 MHz FSB-s Northwood P4-et, az halott volt, nem is bootolt. De rendes, dobozos procival, meg saját cuccal egyáltalán nem.
Félre ne értsd, pánik, fagyás, kékhalál volt nálam, de azt mindig más okozta, szar táp, puposodós kondis alaplap, kiöregedő RAM, döglődő HDD, stb.. Illetve voltak fagyások, leállások, kikapcsolások, hűtési gond miatt, amiben a CPU is érintve volt, de akkor sem döglött meg, ahogy helyre lett állítva a hűtés, ment minden tovább rendben. Persze nálam az is közrejátszik, hogy nem vagyok Tuning Matyi, mindent a gyári alapértékeken használok, régebben volt egy kis tuning, de nagyon enyhe, épp csak annyi, amit feszemelés nélkül még túlmelegedés nélkül tudott hozni a proci. Már jó 15 éve olyan erősek a hardverek, hogy nem látom értelmét a tuningnak.
Nyilván tudom, hogy a proci lehet hibás, neten én is láttam rá precedenseket, elhiszem, hogy van ilyen, én csak azt mondtam, hogy olyan ritka, hogy nagyon kicsi az esélye, hogy a Prohardver belefusson, főleg úgy, hogy a proci eleinte hibátlannak tűnt, és csak utána hibázgatott. Fehér holló szintje. Maradjunk abban, hogy én úgy látom, hogy ők nem értenek hozzá, nem tudják mi a hiba, ráfogták a procira. Vagy az üzemeltető ködösített ezzel. Nekem még az is büdös, hogy egy hibázó proci, a meglévő mappastruktúrát hogy sérthette meg.
“Windows 95/98: 32 bit extension and a graphical shell for a 16 bit patch to an 8 bit operating system originally coded for a 4 bit microprocessor, written by a 2 bit company that can't stand 1 bit of competition.”
- A hozzászóláshoz be kell jelentkezni
Nekem a fentiekből az jött le, hogy a DB egy gépes felállásban működött, és lehet, hogy az alkalmazásszerver réteg is. Ha ez igaz, akkor a "profi" jelző khm. erősen túlzó... És most még finom voltam...
Éles, üzletileg kritikus szolgáltatás alá legyen már normális DB cluster (aminél a hardverhiba okozta adatsérülés illendően node-on belül marad(!), és ugyanígy az alkalmazásszerverből se egy legyen... Persze ehhez nem elég csak a hardverhez érteni...
- A hozzászóláshoz be kell jelentkezni
WOW! Köszönöm!
- A hozzászóláshoz be kell jelentkezni
Karma. Megszűntették a 15 éve regisztrált ~200 pozitívos fiókomat amikor beszántották megvették a vipmail-t. Csak arról a mailról tudtam volna hitelesíteni a fiókomat. Így jártak. Jó lenne, csak egy kis rugalmasság hiányzott. Egyébként blikkk az username, csak karmaoldás miatt mondom.
- A hozzászóláshoz be kell jelentkezni
A karma inkább ott kezdődik, ahány számítógépet eddig újravásároltattak, egyre silányabb, tervezettelavulásosabb kínai szarra, a rovataik mellett arcokba villantott reklámokkal, bértollnokok által írt, tesztnek álcázott, fizetett hirdetésekkel.
- A hozzászóláshoz be kell jelentkezni
"abu" elég undorítóan tolta az amd-t és fosozta az intel,nvidiát minden cikkjében...
- A hozzászóláshoz be kell jelentkezni
Intel hívőknek nem tetszik az ilyesmi. Pedig, meg kell hallgatni, hátha a másik cpu-ja ebben-abban jobb, s ha az ár, hasonló teljesítményért, akkor számítson az.
- A hozzászóláshoz be kell jelentkezni
Mondjuk intel esetében, az amd ellenében meg is van rá mostanság az alapja. Vga fronton is szépen összekapták magukat, az új sorozat igen derekasan jó lett középkategóriáig.
- A hozzászóláshoz be kell jelentkezni
Úgy néz ki sajna a kutya nem veszi a b570/b580-akat. Alza-nál március óta nem fogyott el az a >5-ös készlet. Mivel már leállt az intel a limited edition gyártásával, nem pótolják utána a készletet, szóval tényleg 1 darabot sem adnak el belőle.
Az egyik legnagyobb német nagykernél mutatják a statisztikákat rendszeresen, elkelt június(július?) hónapban 15 db b580, mellette meg 6000+ rtx5xxx
A b770-et egyik hónapban elkaszálják, másik hónapban mégis meg fog jelenni... így álljon féllábon aki olyan hülye h. intel arc-ot akar venni nvidia helyett.
A most már biztosan megjelenő pro b50 / pro b60-at (lehet h. csak utóbbit) meg egyedileg kapni se lehet majd állítólag, csak 100-asával(!). Intel abból nem is hoz ki saját sku-t, csak partner board-ok lesznek. Ergo az msrp is csak kamuzni lesz jó, megvenni annyiért senki nem fogja tudni.
A driver fejlesztés is úgy látom szépen beleállt a fődbe a nagy lendület után. Kihoznak már havonta csak 1-1-et, abba beleraknak 2-3 megjelent aktuális játék profilját, oszt csókolom. A megjelenés óta szar OBS-t nem képesek javítani. A githubon ezrével vannak csak a benyitott issue-k (a tényleges hibák száma emiatt valószínüleg 10x vagy 100x több lehet). Ebből amiket lezárnak, azok között alig van 1-2 tényleges fix. A többit meg kamu-indokkal force-close-olják, megoldás nélkül.
Látszik h. kirugdosták a melósokat. A mihaszna menedzserek, könyvelők, hr-es picsák meg -milyen meglepő?- nem tudnak előrébb vinni egy tech céget. A kirúgott intel mérnökök helyében céget alapítanék, összeszedném a talent-et mielőtt a kínaiakhoz mennének, és utána vissza-kontraktorkodnék a volt munkaadómhoz. Természetesen jó pénzért!
- A hozzászóláshoz be kell jelentkezni
Nem teljesen értem ezt a saját gépes vergődést manapság. Az egyik vezető online sportlap teljesen az AWS-ben fut, havi elérés ~egymillió fő, az oldalletöltést nem tudom hirtelen, de ennek többszöröse, havonta kijön kb. 300 dollárból, tesztrendszerrel együtt, autoscaling, canary release, toronyóra lánccal, mentéssel. Kevéssé hiszem, hogy a prohardver ennél nagyobb elérésű lenne, szóval valószínűleg ennek töredékéből kijönne felhőben.
Másik az, hogy egy gépen fut? Minden is, ami PH? 2025 közepe van, azért egy active-passive cluster már a minimum lenne, de egy active-active lenne elvárható; illetve szét lehetne választani szolgáltatások szerint is, hogy ne egyszerre álljon meg minden. Mondjuk az is igaz, hogy ezek szerint nem veszítenek túl sokat a leállás miatt... :)
- A hozzászóláshoz be kell jelentkezni
Nem teljesen értem ezt a saját gépes vergődést manapság.
Neked elég annyit értened, hogy ha az AWS rohad le, akkor is e-szendvicsemberkeded és protektorkodod a cloud-buzi megoldásokat és az ügyfeleket áldozathibáztatod, hogy miért nem fizettek elő minimum kettő cloudra. 🤡
Ezt hívják kettős mércének, Frankó Mérnök Úr.
Másik az, hogy egy gépen fut? Minden is, ami PH? 2025 közepe van, azért egy active-passive cluster már a minimum lenne, de egy active-active lenne elvárható; illetve szét lehetne választani szolgáltatások szerint is, hogy ne egyszerre álljon meg minden. Mondjuk az is igaz, hogy ezek szerint nem veszítenek túl sokat a leállás miatt... :)
Ezzel meg kivételesen és sajnos egyetértek. Már amennyiben a javasolt fejlesztés nem jár a több másodperces latencykkel és fossá-húggyá innovált™, csiligány, erőforráspazarló UI-jal, amit megszokhattunk már az iparban, akár a kedvenc cloud-multikád EC2-jében is.
- A hozzászóláshoz be kell jelentkezni
Egyetértek bár azt gondolom, hogy az online sportlap és a prohardver közötti párhuzam nem teljesen jó, mert el tudom képzelni, hogy a sportlap 99% fölötti cache hittel dolgozik, miközben a prohardveren elég komoly a felhasználói aktivitás és általuk produkált adatbázis írás. Tehát szerintem drágább üzemeltetni a PH-t. Ettől függetlenül a mai technikával nem szabadna, hogy ekkora leállást okozzon egy hardverhiba.
A backuppal kapcsolatban pedig ha ilyen kérdések merülnek fel, hogy jó lesz-e a backup, visszatölthető-e... ajjajj :) Jó régen volt amikor ilyesmivel kellett szívni.
Persze nem látunk rá a pénzügyekre, mennyire érte meg egyáltalán az egész nekik, de ettől függetlenül azért egy projektmunka keretén belül kifizethettek volna egy architectet aki megcsinálja rendesen az infrastruktúrát, hogy ne kelljen ilyesmivel szívni.
- A hozzászóláshoz be kell jelentkezni
Persze nem látunk rá a pénzügyekre, mennyire érte meg egyáltalán az egész nekik
Az E-beszámolón elérhető, nézz utána. 5 alkalmazottja van a Prohardver KFt-nek, 170 milliós árbevételt érnek el.
- A hozzászóláshoz be kell jelentkezni
Megnéztem, de nyilvánvalóan "kreatív könyvelést" alkalmaznak. Személyi jellegű ráfordítás 5 alkalmazottal éves 20 millió Ft... Hagyjuk már :)
- A hozzászóláshoz be kell jelentkezni
Melyik oldalon látod a kiadásokat részletesen?
- A hozzászóláshoz be kell jelentkezni
Egyetértek bár azt gondolom, hogy az online sportlap és a prohardver közötti párhuzam nem teljesen jó, mert el tudom képzelni, hogy a sportlap 99% fölötti cache hittel dolgozik, miközben a prohardveren elég komoly a felhasználói aktivitás és általuk produkált adatbázis írás.
Hagyjuk már ezt az elég "komoly felhasználói aktivitást"... valószínűleg elfutna egy kis instance-on is.
Ettől függetlenül a mai technikával nem szabadna, hogy ekkora leállást okozzon egy hardverhiba.
Igazából az a probléma, hogy több napos leállást okoz bármilyen hiba.
Az üzemeltetésük valahol 10-15 évvel van lemaradva attól, ahol manapság tart az üzemeltetés... gondolom nincs automation tool használva; a szerver filozófia még a "pet"; a szolgáltatások nincsenek konténerben; nincs azonosítva, hogy mi az immutable, mi az ephemeral és mi a persistent storage; nincs rendes mentés, nincs RPO/RTO, se DRP; és a többi. Egy ilyen problémát a kurrens technológiák egy sárga warning üzenettel jeleznének a monitoring felületen, hogy az egyik szerver köhögött egyet, ez miatt az automatikus drain és poweroff megvolt, a pool többi tagja átvette a feladatait és/vagy a hibrid felhő létrehozott az igények szerint resource halmazt és kell human decision, hogy mi legyen a problémával.
Amúgy én kezdek arra hajlani, hogy beszoptak egy zsarolóvírust és a mentésük is kompromittálódott, mert nem volt rendes mentésük és/vagy nem tudják, hogy kell visszaállni mentésből.
- A hozzászóláshoz be kell jelentkezni
Igen, nagyrészt megint egyetértek, de én továbbra sem becsülném alá a fórum resource igényeit. Nyilván a huppal nem lehet összehasonlítani a terhelést amit a PH kap, és azt gondolom, hogy a hup sem futna el egy kis instance-on. Persze az is igaz, hogy a PH alatti fórummotor valószínűleg ki van hegyezve.
De a lényeg továbbra is az, hogy sajnos az infra oldalt azt borzasztóan benézték.
- A hozzászóláshoz be kell jelentkezni
Korántsem biztos, hogy nekik szükségük van a fent felsorolt „modern” dolgokra. Lehet az az üzemeltetési modell (vagy üzleti modell?), hogy egyszer összerakták, és onnantól az fut a világ végéig, éppen csak a szükséges mértékig módosítva, modernizálva (amennyit az új verziók megkívánnak, már ha van egyáltalán patchelés és upgrade). Ha erőforrás kell vagy elromlott valami, akkor beleraknak egy picit jobb vasat (alkatrészenként), de csak a minimálisat. A DR tervnek meg megteszi az, hogy ha elpukkan valami, akkor majd foglalkoznak a kérdéssel. Ebben a felállásban persze benne vannak ilyen több napos leállások, de mit tudjuk mi így távolról, hogy nekik mi fér bele?
- A hozzászóláshoz be kell jelentkezni
Ebben a felállásban persze benne vannak ilyen több napos leállások, de mit tudjuk mi így távolról, hogy nekik mi fér bele?
Nem ismerem az oldalt, de olyan azért lehet benne, hogy ha eladott hirdetések és kampányok futnak rajta, akkor azért a hirdető elvárhat folyamatos működést és bizonyos fokú rendelkezésre-állást. Persze, az is kérdés, hogy mit fizet a rendelkezésre-állásért a hirdetések árában. Ha lófaszt se, akkor nem gond, ha áll, max. 2 nappal tovább futnak a hirdetései. Max. nem jön vissza legközelebb hirdetni.
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Korántsem biztos, hogy nekik szükségük van a fent felsorolt „modern” dolgokra.
Ezek nem modern dolgok. Az automation tool-ok többsége 15-20 éves. A "pet" vs "cattle" 12 éves filozófia (és már akkor se volt új). A konténerek és a storage racionalizálása szintén 12 éves, egyidős a "pet" vs "cattle" megjelenésével. Minimum 10 éve mature minden olyan, amit említettem és 0 forint licencköltséggel is teljesen jól használhatóak. Nyilván meg kell tanulni, de egy IT portáltól elvárható lenne, hogy 10 év alatt azért ezeket megugorja, főleg, ha üzleti alapokon működik.
A másik dimenziója a kérdéskörnek az, hogy sok kisebb-nagyobb cégnél járva azt vettem észre, hogy az első IT generáció - akik kb. mi, az ötvenesek vagyunk - egyszerűen kiöregedett, kiégett, a többsége ennek a generációnak már nem tud, nem akar új dolgot tanulni, megragadt ott, ahol kb. 35 éves korában tartott, az volt számára az aranykor, addig minden újdonság izgalmas és érdekes volt, azóta meg minden csak szarabb lett, szóval igen sok cég, ahol az IT terület ezekből a kb. ötvenesekből áll, megállt 10-15 évvel ezelőtti szinten. És sajnos látszólag a PH csapata is pont ilyenekből áll.
- A hozzászóláshoz be kell jelentkezni
Jól van ez így. Az eszkimóknál ezért kellett megdugni a vendégnek az asszonyt. Most milyen lenne ha belterjes körúti random húszéves csicskákból állna a csapat?
- A hozzászóláshoz be kell jelentkezni
50es vagyok, de még ha a 15 évvel ezelőtti tudásommal terveztem volna a backupot és a DR-t - akár olyan archaikus eszközökkel mint a tar/dd/mysqldump/pgdump, akkor sem kell két nap ahhoz, hogy egy tetszőleges vason (akár csak egy röptében előrángatott cloud instancián) fel lehessen építeni a működő rendszert.
Feltéve, ha az OS aktuális, nem most kellene azon variálni, hogy egy 10 évvel ezelőtti OS-t hogyan tudunk feltelepíteni, mert az aktuális verzióval nem indul be az alkalmazás.
- A hozzászóláshoz be kell jelentkezni
Korántsem biztos, hogy nekik szükségük van a fent felsorolt „modern” dolgokra
Ezek nem annyira modern dolgok, azért. Filléres commodity megoldások vannak mindegyikre, ha nem kell valami nagyon specializált megoldás valamiért.
- A hozzászóláshoz be kell jelentkezni
Amúgy én kezdek arra hajlani, hogy beszoptak egy zsarolóvírust és a mentésük is kompromittálódott, mert nem volt rendes mentésük és/vagy nem tudják, hogy kell visszaállni mentésből.
Erre utaltam én is azzal, hogy szvsz a hardverhiba fedősztori. De majd megíratják a post mortem elemzést a chatgpt-vel.
- A hozzászóláshoz be kell jelentkezni
> valószínűleg elfutna egy kis instance-on is.
vs
"otthon elfuttatom egy P2-n is"
Nem tudod mi van mögötte, nem tudod mekkora az erőforrásigénye, de már véleményed az van. Plot twist: nem futna el egy kis instance-n.
Mi lenne, ha visszanyitnád az IntelliJ-t, az üzemeltetést meg meghagynád az üzemeltetőknek?
- A hozzászóláshoz be kell jelentkezni
Nem tudod mi van mögötte, nem tudod mekkora az erőforrásigénye, de már véleményed az van. Plot twist: nem futna el egy kis instance-n.
Elég baj az, ha egy többszörös forgalmat elviselő rendszernél nagyobb igénye van. Szóval akkor ott a fejlesztőknek és az üzemeltetőknek közösen kicsit át kellene gondolniuk, hogy mit és miért csinálnak.
Mi lenne, ha visszanyitnád az IntelliJ-t, az üzemeltetést meg meghagynád az üzemeltetőknek?
Lehet, hogy meglepődsz, de én igen sokat üzemeltettem és az utóbbi években főképp üzemeltetéssel foglalkozom... igaz, leginkább cloud és K8s vonalon, a PH rendszereinél jóval nagyobb forgalmú, terhelésű és rendelkezésre állású rendszereket.
- A hozzászóláshoz be kell jelentkezni
Nyilvánvalóan nem jó amit csinálnak, de nem ilyen egyszerű az élet.
Nem látsz bele az üzletbe, nem tudod hogy milyen tudás áll rendelkezésre, nem ismered a rendszert amit fejleszetettek / üzemeltetnek.
- A hozzászóláshoz be kell jelentkezni
Nem látsz bele az üzletbe, nem tudod hogy milyen tudás áll rendelkezésre, nem ismered a rendszert amit fejleszetettek / üzemeltetnek.
Hát, az egyre inkább kilátszik, hogy milyen tudás áll rendelkezésre... és messze nem egy komplex rendszer. Ne tegyünk úgy, mintha egy nagy komplex rendszer lenne.
- A hozzászóláshoz be kell jelentkezni
Úgy teszünk hogy az elmúlt 10 - 15 nem hozott annyi hasznot, hogy érdemes legyen modernizálni.
IT az üzlet része, nem magától és magáért él.
- A hozzászóláshoz be kell jelentkezni
Úgy teszünk hogy az elmúlt 10 - 15 nem hozott annyi hasznot, hogy érdemes legyen modernizálni.
Akkor meg az van, mint a mellékelt ábrán is látszik.
- A hozzászóláshoz be kell jelentkezni
.. és ebből milyen üzletre vonatkozó konzekvenciát tudsz levonni?
Én nem tudom megmondani hogy a három napos leállás veszteségben nagyobb számot jelent-e mint az elmúlt 15 évben IT-ra el nem költött pénz.
100 millió körüli éves bevétel mellett úgy sejtem, a szaldó még bőven az el nem költött pénz felé mutat.
- A hozzászóláshoz be kell jelentkezni
Itt igazából egy havi ~3-5 dolláros külső mentés hiányáról beszélünk elsősorban, másodsorban arról, hogy ha saját vasban is gondolkodnak, akkor képesek-e 40 dollárért bérelni egy fizikai gépet a felhőben, amíg a saját vasat gyógyítják. Szerintem ezek nem olyan összegek, amelyekbe beleroppanna a cég anyagilag.
- A hozzászóláshoz be kell jelentkezni
Na, ez már releváns nekem is: hol kapok 5 USD-ért olyan DB mentést, ami megpróbálja garantálni a konzisztenciát?
- A hozzászóláshoz be kell jelentkezni
Franko külső mentést említett, nem DB mentést.
"olyan DB mentést, ami megpróbálja garantálni a konzisztenciát?"
Ezt megoldod magadnak, aztán elrakod a külső 5 USD-ért bérelt külső helyre
// Happy debugging, suckers
#define true (rand() > 10)
- A hozzászóláshoz be kell jelentkezni
Az ár persze sokmindentől függ, de például a cloudnativepg is tud olyat, hogy például legyen napi mentés amazon (s3 kompatibilis) bucketbe feltolva és akár 5 percenkénti különbözet (wal) is felszinkronizálva. A feltöltés és tárolás olcsó, ha egyszer szükség van rá és nagy a db, akkor némi költsége van a letöltésnek.
Persze a teljes mentés ritmusát még az is befolyásolhatja, hogy milyen a net sávszélesség, hogy feljusson a bucketbe.
És gondolom nem muszáj oda menteni, lehet olcsóbb alternatíva is, vagy talán akár saját másik szerver is, ami megfelelő protokollon fogadja az adatokat. Meg ugye áltlában úgy szokás, hogy legyen közeli mentés, akár házon belül és amellett még offsite is, ami akkor kell, ha helyben megsemmisült vagy régebbi időtávból kell valami.
- A hozzászóláshoz be kell jelentkezni
Na, ez már releváns nekem is: hol kapok 5 USD-ért olyan DB mentést, ami megpróbálja garantálni a konzisztenciát?
Már írtam, hogy ilyen low-end és middle-end környezetben gond nélkül megy az, hogy "backup stage start" parancsot megkapja a DB, a DDL műveletek blokkolásra kerülnek, a disk-re kimegy a flush minden lezárt tranzakcióról és a journal-ba kerülnek az újak, ez néhány másodperc sincs kurva nagy DB esetén is, ezek után rámehet a snapshot a fájlrendszerre, mehet a "backup stage end", majd a snapshot-ról mehet a mentés. Az eredménye az, hogy lesz egy konzisztens mentésed. Nyilván ehhez kell olyan fájlrendszer, ami tud snapshot és olyan DBA, aki ismeri ezt és olyan backup tool, ami tud snapshot kezelést. És van 1TB storage box 5 USD körül, de mehet akár S3 kompatibilis bármibe is, az se drága.
- A hozzászóláshoz be kell jelentkezni
tl;dr sehol, de monduk erősen függ a storage-től, amit a snapshotok felzabálnak
szerk: mármint ha ez valamelyik cloud saját backupja, ha 5 dollárért bérelsz valami low cost VPS-t, mint backup appliance, akkor gondolom igen
- A hozzászóláshoz be kell jelentkezni
TLDR: Szerintem az van, hogy ha kizárólag enterprise környezetben mozogtok és a cloud az az Amazon/Microsoft/Google trió valamelyike lehet csak, akkor nem tudjátok, hogy mi van azon kívül és valahogy azt a képet építitek fel, hogy vagy a high-end trió van, vagy vérpistikebété és közötte légüres tér és tücsökciripelés.
- A hozzászóláshoz be kell jelentkezni
Igazad van. Akkor hol kap Tassadar 5 USD-ért olyan DB mentést, ami megpróbálja garantálni a konzisztenciát?
- A hozzászóláshoz be kell jelentkezni
Igazad van. Akkor hol kap Tassadar 5 USD-ért olyan DB mentést, ami megpróbálja garantálni a konzisztenciát?
Igen, le is írtam a módszerét olyan DB mentésnek, ami nem csak megpróbálja garantálni, hanem garantálja a konzisztenciát.
- A hozzászóláshoz be kell jelentkezni
| S3 Glacier Deep Archive *** - For long-term data archiving that is accessed once or twice in a year and can be restored within 12 hours | |
| All Storage / Month | $0.00099 per GB |
Úgy látom a google arhive drágább $0.0012 /GB/M
Viszont szükség esetén letölteni drága lesz, hiszen ez csak vész esetére kell. Mellette egy közelebbi, gyorsabban elérhető példány sem árt, akár egy másik saját szerveren. Gyorsabban elérhető/gyakrabban hozzáférendő változat drágább, cserében azt meg olcsóbb lekérni.
- A hozzászóláshoz be kell jelentkezni
Csak itt meg 180 nap retentiont mindenképpen ki fogsz fizetni, úgyhogy a napi, heti, stb. backupra felejtős. Arra jó, hogy mondjuk 3-6 havi snapshotot eltegyél 10 évre.
- A hozzászóláshoz be kell jelentkezni
Ha a topic és a sub-topic kapcsán maradunk, akkor ~1 TB adat mentése heti egy full + óránként incremental az 180 days retention mellett is kb. havi ~25 dollár lenne...
- A hozzászóláshoz be kell jelentkezni
Én konzisztens állapotot biztosító SQL backup-ot írtam, ez pedig egy storage megoldás.
Arra gondoltál hogy kiexportálod bacpac / SQL fájlba, ezzel le van tudva a mentés?
- A hozzászóláshoz be kell jelentkezni
nem tudom kitalálni, hogy éppen milyen téveszmét találtok ki. De ott lehet olcsón tárolni az eredményt, amit a rendszer kiad és fel is szinkronizál. A cloundnativepg alapból tudja ezt. Az, hogy egy szar rendszerből szarul lehet kimenteni adatok, nem különösebben érdekel, mert nem szar rendszert kell csinálni, ez az alapfeltétel.
https://cloudnative-pg.io/documentation/1.16/backup_recovery/
- A hozzászóláshoz be kell jelentkezni
Ez olyannyira cloud-native hogy managed Postgre-t nem is támogat, tehát te szophatsz a K8 alapú üzemeltetéssel is?
- A hozzászóláshoz be kell jelentkezni
ja, hogy már az az elvárás a mozgó célpontnál, hogy ingyen is legyen minden, de vas se kelljen, de más dolgozzon vele :D Esetleg ne fizhessenek érte, mert használni akarod?
- A hozzászóláshoz be kell jelentkezni
Én egy szóval sem mondtam hogy ingyen legyen - pontosan azt boncolgattam hogy egy használható backup megoldás nem 5 USD per hó.
- A hozzászóláshoz be kell jelentkezni
Viszont ha az IT infrastruktúra egy honlap esetén nyugodtan lehalhat, és utána ott rohadhat meg, akkor ezek valamiféle hobbiprojektek voltak, és el is lehet őket felejteni. Ha viszont ezzel valakik pénzt akarnak keresni, akkor felmerülhet a gyanu, hogy egyszeűren csak lerohadt, mert nem azzal sproltak, hogy nem költenek a modernizációra, és most a fejükre esett az egész.
Ha tartós rendszert építesz és okos csapatot nevelsz, akkor száz kiadásban sem érheti baj; ha csak a gépekre hagyatkozol, akkor egyszer jól jársz, máskor rosszul; de ha sem a rendszer nem bírja a terhet, sem a csapat nem tanul a hibákból, akkor minden egyes kiadás kockázat.
- A hozzászóláshoz be kell jelentkezni
Többször modernizálást említetek, de itt most valsz nem a hardver modernségéről, hanem a megfelelő folyamatok hibájáról és reduncancia hiányáról van szó.
A jól menő nagy cégektől leselejtezett 5 éves szerverekben is bőven van még élet. Pláne, ha nem egy darab, hanem redundánsan több darab lesz.
Szoftveres oldalról is van sokminden, ami ingyen van, kell némi tanulás a megismeréséhez de pont az ilyen esetek ellen nagy mértékben védene. De még ha nem is vezetnek be modernebb szoftveres futattatási környezetet, mert mondjuk túl legacy az alkalmazásuk náluk, de a db szoftverek ezer éve tudnak redundáns működést.
Nem ismerem a stábot, de azt hiszem talán 1-2 ember van náluk, aki fejleszt és/vagy üzemeltet, szóval lehet erősen hobbista körülmények lehetnek.
A többiek meg inkább újságírók, lelkes amatőrök, akik tartalmat gyártani tudhatnak inkább, vagy felhasználói szemmel tapasztaltabbak, nem üzemeltetésileg.
Remélhetőleg tanulnak belőle és ha taplra tudnak állni (nem veszett el a tartalom), akkor ilyen hw hibával nem fognak felborulni még egyszer.
- A hozzászóláshoz be kell jelentkezni
ÉN azon nem lepődnék meg, ha 24 éve redunncia/normális backup nélkül indultak volna el, csak azóta tovább kellett volna fejlődni. Ez láthatóan nem sikerült.
De értem, amit mondasz, igazad is van, ez nem modernizációs krédés, hanem architektúrális antipattern probléma.
Ha tartós rendszert építesz és okos csapatot nevelsz, akkor száz kiadásban sem érheti baj; ha csak a gépekre hagyatkozol, akkor egyszer jól jársz, máskor rosszul; de ha sem a rendszer nem bírja a terhet, sem a csapat nem tanul a hibákból, akkor minden egyes kiadás kockázat.
- A hozzászóláshoz be kell jelentkezni
Elég tág intervalumon mozog a pénzkeresés.
100 millió nagyságrendű éves bevétel mellett 3 nap leállás egymillió Forint bevételkiesés sincs - ide nem értve az üzleti bizalmat.
- A hozzászóláshoz be kell jelentkezni
Plot twist: nem futna el egy kis instance-n.
Plz elaborate, akkor, hogy mi kellene egy ilyen alá
- A hozzászóláshoz be kell jelentkezni
"miközben a prohardveren elég komoly a felhasználói aktivitás és általuk produkált adatbázis írás." - Anno 1000 éve az iwiw-en megoldottuk, hogy kellően nagy terhelést elvigyen... Jó, anno vuduka (RIP) ott volt, és a MySQL sharding meg aktív-passzív párok elég jól össze lettek csiszolva :-) De említhetném az árukeresőt is - mostani szemmel nevetséges erőforrásokkal vitte a karácsonyi/ilyen.olyan extra terheléseket is... Igen, egyik rendszer sem egy gépes péhápépistike szinten összerakott motyó volt...
"A backuppal kapcsolatban pedig ha ilyen kérdések merülnek fel, hogy jó lesz-e a backup, visszatölthető-e..."
- A hozzászóláshoz be kell jelentkezni
Ami árulereső alatt van azt legkevésbé se nevezném nevetséges mennyiségű vasnak :D
Btw az iwiw szerintem bünlassú volt anno.
- A hozzászóláshoz be kell jelentkezni
Anno az ak alatt volt néhány nagyon érdekes/ötletes megoldás, hogy költséghatékonyan működjön. A wiw alap funkciói nem voltak bűn lassúak, miközben nem volt olyan eleme a rendszernek, amit kikapcsolva/amiből a tápot kihúzva felhasználók észrevették volna a változást.
- A hozzászóláshoz be kell jelentkezni
az az iwiw, ami esett-kelt folyamatosan, és a T sem bírt alá akkora vasat rakni miután megvették, h. jól bírjon menni?
- A hozzászóláshoz be kell jelentkezni
Amikor a T megvette, már lefelé ívelt... Maradjunk annyiban , hogy nem akartak erőforrást/pénzt beletolni pluszban... Nem véletlen, hogy az egyébként előkészített többnyelvűség is csak poc szintig jutott...
- A hozzászóláshoz be kell jelentkezni
Nyilván, lehet frankón optimalizálni mindent, én csak arra utaltam, hogy egészen más a terhelési karakterisztika, így teljesen más erőforrás igénye lehet egy nagy látogatottságú de inkább read-only oldalnak (híroldal), mint egy fórumnak, ahol sok az adatbázisművelet.
- A hozzászóláshoz be kell jelentkezni
Az, hogy egy cpu-csere megfekteti a teljes szolgáltatást az... Mondjuk úgy, a szakmának nehezen hihető - vagy ha tényleg ez történt, akkor rettenet nagy lámaság is kellett hozzá... Lehet több node-os in-memory DB-t is használni, ahonnan szépen megy perzisztens tárolásra az az adat, ami oda való...
- A hozzászóláshoz be kell jelentkezni
Anno 1000 éve az iwiw-en megoldottuk, hogy kellően nagy terhelést elvigyen
Hmm én valószínűleg pont nem ebben az időszakban voltak aktív user, hanem amikor még nem volt megoldva :D
- A hozzászóláshoz be kell jelentkezni
Én userként annyira emlékszem, hogy amikor még csak wiw volt (ez ugye megvan?), akkor jól működött. Mikor iwiw-lett belőle, na akkor kezdődtek a problémák.
- A hozzászóláshoz be kell jelentkezni
"Anno 1000 éve az iwiw-en megoldottuk, hogy kellően nagy terhelést elvigyen"
Hát, akkor én egy másik univerzumban éltem.
- A hozzászóláshoz be kell jelentkezni
Ja, és mondjuk azért egy sorry-server sem ártana, komolytalan, áll a cucc másfél napja, és connection timed out? Bárhol fel lehet húzni egy static weboldalt, DNS átír és akkor oda ki lehetne írni mindezt, nem egymástól kérdezné mindenki fórumokban, hogy mi van.
- A hozzászóláshoz be kell jelentkezni
Na ja, sértődni tudnak a Facebook postjukban, de egy statikus oldalra irányítani a domain-eket, az már sok. Nem lennék a helyükben és nem is fikáznám látatlanul a technikai hátteret, de kommunikáció az bukta náluk.
Színes vászon, színes vászon, fúj!
Kérem a Fiátot..
- A hozzászóláshoz be kell jelentkezni
Nekem amikor teljesen szétborult az asszony szervere, az aláírásomban szereplő cuccot bedugtam a konnektorba, öt perc alatt felraktam rá egy html-t ami közölte a kedves látogatóval, hogy javítás alatt, hamarosan visszajön.
- A hozzászóláshoz be kell jelentkezni
Azért a FB-os kommentek :D
Innentől a nevetek "NEMPROHARDVER"
- A hozzászóláshoz be kell jelentkezni
Mert hát az újabb generációs Intel proci megint jobb™ volt.
Egészen mostanáig, amikor már belátják, hogy a régebbi volt a jobb.
Csak a szokásos fejlődés™ történt.
- A hozzászóláshoz be kell jelentkezni
Megfelelő -és tulajdonképpen a legalapvetőbb szakmai elvárásoknak megfelelő - tervezés esetén ezt a hardver problémát észre sem lett volna szabad venni senkinek az üzemeltetésen túl. Mindegy, hogy cloud, nem cloud, üzletet szogláló infrát már húsz éve sem adtam át renduncia nélkül. Igaz, 20 éve még belefért pár perc adásszünet. Ma meg már annyi sem.
Ha tartós rendszert építesz és okos csapatot nevelsz, akkor száz kiadásban sem érheti baj; ha csak a gépekre hagyatkozol, akkor egyszer jól jársz, máskor rosszul; de ha sem a rendszer nem bírja a terhet, sem a csapat nem tanul a hibákból, akkor minden egyes kiadás kockázat.
- A hozzászóláshoz be kell jelentkezni
Nem hp, ph ;)
I don't run often, but when I do, I run as administrator.
- A hozzászóláshoz be kell jelentkezni
Előzőre ráfúzve (nem hp, PH!):
Nem AMD, MAD!
"A fejlesztők és a Jóisten versenyben vannak. Az előbbiek egyre hülyebiztosabb szerkezeteket csinálnak, a Jóisten meg egyre hülyébb embereket. És hát a Jóisten áll nyerésre." By:nalaca001 valahol máshol
Sose fulld trollba a kretént.
- A hozzászóláshoz be kell jelentkezni
HPE, csak hogy precízek legyünk ;)
- A hozzászóláshoz be kell jelentkezni
A felhő rossz, értem?
Volt ilyen tapasztalatom egy melóhelyen, ahol mindig ment a kínlódás amikor bedöglöttek a vasak. Ment a matekozás meg a kukázás. (sok-sok milliárd nyereséges cég). Végül a felhős átállás oldotta meg. Nem is a felhő a lényeg, hanem az, hogy a vasat bérled és ha bedöglik valami, akkor a szolgáltató lerendezi úgy, hogy azt jó esetben észre sem veszed.
- A hozzászóláshoz be kell jelentkezni
A multinál ahol az alkalmazottnak semmi köze semmihez, ott jó. A párom szervere a budiban van, el nem tudnám képzelni hogy egy idegen helyen bérelt szolgáltatásként menjen. Ha beszarik rendberakom / faszolok.
- A hozzászóláshoz be kell jelentkezni
..budiban... beszarik.. stílszerű :)
- A hozzászóláshoz be kell jelentkezni
A párom szervere a budiban van, el nem tudnám képzelni hogy egy idegen helyen bérelt szolgáltatásként menjen.
Mert, mi van azon, amit nem lehet "idegen helyen" futtatni?
- A hozzászóláshoz be kell jelentkezni
Ezt nem tudnám elképzelni hogy nem itthon van. Egyébként tényleg a sloziban figyel.
- A hozzászóláshoz be kell jelentkezni
Azt értem, csak azt nem, hogy mi az oka, hogy nem tudod elképzelni?
Mármint technikailag ha jól látom (a favicoból, azt cseréld már ki ;) ) ez egy wordpress, remekül el tudhatna futni kb akárhol is, nem hiszem, hogy a kedves érdeklődő kevésbé lesz értékes és szerethető, hogy az aws szolgálja ki neki.
- A hozzászóláshoz be kell jelentkezni
Nem ismerem, hogy pontosan mik a körülmények itt, de szerintem az oldal látogatottsága nem olyan magas (nincs rajta gyakran egyidejűleg 100 látogató), jó eséllyel egy Raspberry Pi is ki tudja szolgálni.
Ha pedig az otthoni net elegendő a kiszolgálására, és esetleg egy amúgy is futó NAS végzi azt, vagy más okból kb. "ingyen van", akkor nem nagyon van értelme akár csak havi 10 dollárért felhőben futtatni.
Ha ugyanezt a wordpress.com-tól bérelve futtatná, az évi 99 dollár lenne. Nyilván ha csak erre futna otthon egy dedikált gép, akkor nem érné meg, mert évente 20 ezernél többet enne csak áramból, de pl. nálam is otthon van egy NAS, ami mindenképp fut, azon egy ilyesmi oldalt már plusz költség nélkül ki lehet szolgálni.
Nagy Péter
- A hozzászóláshoz be kell jelentkezni
Évi 99 dolláron spróolni. cserébe napokig áll az oldal? Vannak itt bajok.
Ha tartós rendszert építesz és okos csapatot nevelsz, akkor száz kiadásban sem érheti baj; ha csak a gépekre hagyatkozol, akkor egyszer jól jársz, máskor rosszul; de ha sem a rendszer nem bírja a terhet, sem a csapat nem tanul a hibákból, akkor minden egyes kiadás kockázat.
- A hozzászóláshoz be kell jelentkezni
Hát, azon múlik, hogy az oldal napok alatt hoz-e 99 dollárt, vagy sem. Gondolj bele, hogy mondjuk az oldal hatására évente bejön 100 000 forint. Ha ebből 35 ezret elköltesz az üzemeltetésre, az nagyobb bukta, mint ha 2 napig nem megy, és szerencsétlen esetben emiatt elbukod az éves bevétel 10%-át. Nekem van olyan oldalam, amire havi 99 dollárt is megéri elkölteni (el is költöm rá), és olyan is, amire évi 99 dollár is kidobott pénz lenne.
Nagy Péter
- A hozzászóláshoz be kell jelentkezni
A gyerekeim több zsebpénzt kapnak egy évben, mint 99 dollár. Ez nem üzleti vállalkozás - maximum egy a villanyszámlába besegítő side projekt.
Ha tartós rendszert építesz és okos csapatot nevelsz, akkor száz kiadásban sem érheti baj; ha csak a gépekre hagyatkozol, akkor egyszer jól jársz, máskor rosszul; de ha sem a rendszer nem bírja a terhet, sem a csapat nem tanul a hibákból, akkor minden egyes kiadás kockázat.
- A hozzászóláshoz be kell jelentkezni
"A gyerekeim több zsebpénzt kapnak egy évben, mint 99 dollár"
Azért na... amik eszembe jutottak, hogy az is egyfajta befektetés, hogy tanuljon meg bánni a pénzzel, plusz családban marad, plusz sok kicsi sokra megy. Én bőven megértem, ha valaki nem akar feleslegesen pénzt szórni (és hogy mi a felesleges, az nagyon szubjektív tud lenni).
- A hozzászóláshoz be kell jelentkezni
Hát, nem is látom az oldal impresszumában a vállalkozás nevét (impresszumot sem), inkább tűnik egy magánszemély hobbioldalának. Nem hiszem, hogy ez egy milliós bevételű vállalkozáshoz tartozna, és mint általában a hasonló helyeken, inkább a törzs-ügyfelek adják a bevétel döntő részét.
Illetve vélhetően lehet róla backupot készíteni egy átlagos pendrive-ra pár havonta, és ha teljesen megsemmisül a gép, 15 perc alatt visszaállítható egy másik szerveren.
Nagy Péter
- A hozzászóláshoz be kell jelentkezni
Na de itt nem az volt a mondás, hogy nem éri meg, hanem az, hogy el se tudná képzelni, hogy felhőbe legyen, ami azért nem ugyanaz :)
Egyébként ezen úgy látom kolléga kedves párja csak "blogol", szóval nem kellene alá wp, de ha már mindenképp de ha ragaszkodunk hozzá, hát felteszem a lapoptra, beleteszek egy static export plugint, aztán pont nulla dollárért szolgálja ki a cloudflare vagy valaki. De a random gugli is ilyen évi 10 körül már dobál magyar wordpress szolgáltatókat.
- A hozzászóláshoz be kell jelentkezni
Ezt én is csak úgy tudom elképzelni, hogy mondjuk olyan helyzetben van, hogy otthon mindenképp fut a szerver, vagy valami barterüzlet keretében ingyen van neki az üzemeltetés, és tele van szabad kapacitással.
Mármint én sem tudnál elképzelni, hogy máshol akár csak fillérekért fizessek elő felhő-tárhelyre, miközben a saját NAS-omon is szabadon állnak a TB-ok (RAID 6-ban, LTO mentéssel). Ha valaki havi 1 dollárért kínálna nekem 1 TB felhő-tárhelyet, az is csak 1 dollár kidobott pénz lenne nekem; miközben maga az ajánlat az emberek 99%-nak remek lehetőségnek tűnne. Valami hasonló helyzetet tudok elképzelni nála is.
Nagy Péter
- A hozzászóláshoz be kell jelentkezni
Nyilván én se mondtam, hogy háziszervert is felhőben kell tárolni. Bár van az ami jobb helyen van ott magánszemélynél is. (egy havi 5 dodós VM nem nagy dolog).
Egyébként nekem is saját épített NAS-om van itthon amiről fut egy csomó dolog:
https://i.postimg.cc/mgkC2Nzv/Screenshot-From-2025-07-24-08-11-25.png
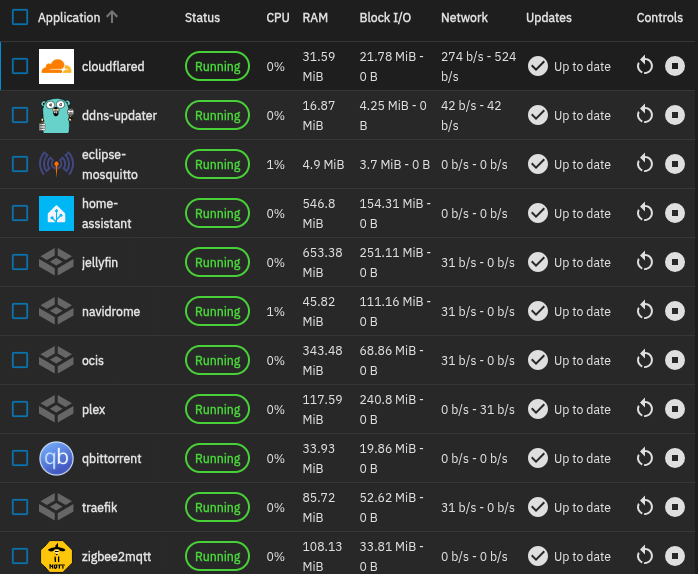{kind=link}
Ezeket én se tenném felhőbe. (apropó, a plex-et törölnöm kell mert a Jellyfin leváltja)
- A hozzászóláshoz be kell jelentkezni
Nem is a felhő a lényeg, hanem az, hogy a vasat bérled és ha bedöglik valami, akkor a szolgáltató lerendezi úgy, hogy azt jó esetben észre sem veszed.
Valóban, mert ehhez semmi felhő sem kell.
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Csak egy olyan szolgáltató akinek akkora infrája van, hogy ezt meg tudja tenni.
Annó amikor a CTO a felhős átállást tervezte, akkor megkérdeztem, hogy mit tekintenek felhőnek (mert nem volt egyértelmű). Azt válaszolta, hogy azt ahol nem a saját gépünk fut.
Ez ennél nyilván árnyaltabb, mert most is lehet bérelni itthon is szervert, csak épp ha bedöglik, akkor simán órákra kiesik minden, plusz továbbra is a tiéd a teljes felelősség.
- A hozzászóláshoz be kell jelentkezni
"Annó amikor a CTO a felhős átállást tervezte, akkor megkérdeztem, hogy mit tekintenek felhőnek (mert nem volt egyértelmű). Azt válaszolta, hogy azt ahol nem a saját gépünk fut."
És ő volt a CTO? :) Hm...
Ezeknek az embereknek azt kell mondani, hogy a "felhő" egy absztrakciós réteg -> CNCF
- A hozzászóláshoz be kell jelentkezni
Már több éve más van helyette, de sokkal rosszabb mint ő volt. Bár én már nem dolgozom ott szerencsére. A CTO volt a legkisebb probléma.
- A hozzászóláshoz be kell jelentkezni
Mi megmértük, hogy mennyibe kerülne az új vas a régi, erkölcsileg amortizálódott, nullára leírt szerver helyett, vettünk egy ötéves futamidőt és havi amortizációt összemértük egy ezzel egyenértékű vas bérleti díjával a felhőben (pontosabban egy németországi üzemeltetőnél). Az jött ki, hogy még úgy is olcsóbb bérelni, ha nem számolunk semmilyen karbantartási költséget a hardverhez és abból indulunk ki, hogy öt éven keresztül nem lesz nálunk se áramszünet se internetkiesés (mondjuk ennek a veszélye nagyságrenddel alacsonyabb a bérelt gép helyszínén, mint nálunk). Mondjuk az is igaz, hogy az ár, amit fizetünk, fele-harmada annak, mint amennyiért ugyanezt idehaza magyar szolgáltató kínálta. Szerintem itt az igény, az ismeret és a mázli játsszák a döntő szerepet (ha pont van olyan hardver a kínálatban, ami pont megfelel az igényednek és erre rá is találsz), szerencsés együttállásban, mint nálunk, nem érdemes a hardverrel a saját telephelyen baszkódni.
- A hozzászóláshoz be kell jelentkezni
A felhővel kapcsolatban egy (sok) dolgot szem előtt kell tartani: a kupi a felhőben is kupi.
- A hozzászóláshoz be kell jelentkezni
Amennyire tudom, régen mindent maguk csináltak – saját motor, reklámszerver, full házon belüli cuccok. Én is sokáig aktív voltam, aztán egyszer végleg kivágtak, mert egy személyeskedő vitában kicsit elszálltam. Elég gyerekes volt, na. Azóta se bánom, hogy szurkolok nekik, szerintem a 2000-es évek közepe volt az ilyen oldalak igazi csúcskorszaka. Ma már inkább a videók tarolnak. Az akkori konkurencia meg kb. sehol. Ez meg a hátránya annak, ha mindent saját kézben akarsz tartani – mindenhez érteni kell. De ettől függetlenül szerintem elég profin nyomják, az ilyen technikai malőrök meg benne vannak a pakliban.
- A hozzászóláshoz be kell jelentkezni
Az a szomorú, hogy egy kifejezetten IT-val foglalkozó, üzletét arra építő cégnél sincs meg a megfelelő tudás egy ilyen egyszerű helyzet elkerülésére, vagy kezelésére. Sőt, az a tudás sincs meg, hogy "nem tudjuk ezt vagy azt, meg kell kérdezni valakitől" (ritkább esetben tudják, csak túl büszkék, de inkább nem tudják).
Ugyan ez van az iskolákban (minden szinten, általánostól egyetemig) az IT tanárok terén, ők sem tudják, és még azt sem tudják, hogy nem tudják.
Mi meg várjuk, hogy majd a felnövő generáció tudja amit kell, úgy, hogy akitől megtanulhatnák, a Dunning-Kruger görbe alján van.
- A hozzászóláshoz be kell jelentkezni
"ritkább esetben tudják, csak túl büszkék"
Pont ezen gondolkoztam. Ez a leállás már annyi ideje tart, hogy ha nem ez lenne a helyzet, akkor már régen kiálltak volna, hogy légyszi segítsen valaki. Sokan megtennék jófejségből is, ingyen.
És igen, sajnos ezt egy társadalmi/kulturális problémának tartom. Kérdezz, de ne túl sokat mert akkor butának tartanak majd. Ego mindenek felett... Persze itt a hupon ezt nem kell mondani :)
- A hozzászóláshoz be kell jelentkezni
Sokan megtennék jófejségből is, ingyen.
Szerintem meg nem. Nehéz dió, mert a PH is csak egy profitorientált cég. Bjiznisz. Írni kellene egy 30 oldalas szerződést, amiben az ingyen segítségért cserébe vállalod h. a családi házadat meg a gyerek taníttatására spórolt pénzt is elviszi a végrehajtó ha elbaszod a segítséget és marad a baj v. mégnagyobb gebaszt is okozol. Nyilván az országban nem találsz embert aki ezt elvállalná. Nem hogy ingyen, még pár százezerért sem.
A másik oldalról meg kiben bíznál meg a PH ügyvezetője helyében, h. ismeretlenül odaengedj bárkit is a teljes céged megélhetési forrásod infrastrukturájához? Mert lehet h. jelentkezne 5-10 ember az országban, de hogy döntesz közöttük? Nyilván minden hup-os szuper-tapasztalt ilyen kérdésekben, ezrével veszi fel, alkalmazza, rúgja ki, küldi el a bedolgozós embereit. Egyesével leinterjúztatni minden jelentkezőt, az napok-hetek, ráadásul ahogy egy állásinterjún lehet kamuzni, és mellényúlni, úgy itt is. Főleg mert időszűke van.
Nyilván 1 nagy IT cég tudna megoldást. De ha sos kell a segítség, az 1) nem lesz még annyira se olcsó mint a normál esetben végzett külsős munka 2) mire lepapírozzák, az még 1 hónap. Mert papír nélkül nincs munka-elkezdés, ezt ugye mindenki tudja? Máskülönben az még drágább lesz utólag mint az 1) esetben.
- A hozzászóláshoz be kell jelentkezni
Értem amit mondassz, de nekem úgy tűnik, hogy a PH messze van attól az üzleti professzionalizmustól amit feltételezel.
edit: hogy a kérdésedre is válaszoljak. FB-on sokan jelezték nekik hogy segítenének, ergo kiraknék egy posztot a helyükben, hogy hát ez van, elbénáztuk HELP. Aki hajlandó segíteni, jelentkezzen egy linkedin profillal, és akkor össze lehetne hozni egy kis community war roomot pár önként jelentkezővel. És akkor kerekedhetne belőle egy community sikersztori is.
- A hozzászóláshoz be kell jelentkezni
Céges példát erre (community összefogás, a stenvedő fél alázata beismerése és segítségkérése) én ebben az országban nem tudok mondani az elmúlt 20 évből emlékezet alapján.
FB-on sokan jelezték nekik hogy segítenének
--> ahhoz h. segítséget tudj adni, azt a másik félnek el is kell tudnia fogadni
Az h. valami nonprofit alapítványt, kis home szervert javított már meg a hazai közösség, azt el tudom hinni. De ez itt most nem ez a szint. Aki ingyen elvállalja, és elcseszi, azon hogy hajtod be a felelősséget? Hiába a jószándék vezérelte. Vagy ha a megrendelői oldal kezd el újabb és újabb feladatokat hozzárakni a helyreállításhoz. Felállsz és otthagyod őket? Szóval bonyolult szituáció tud ez lenni, mindkét fél oldaláról.
1-2 (3?) éve keresett itt valaki bme v. elte (már nem emlékszem) egyik tanszékére AD rendebrakós embert. Abból se lett emlékeim szerint semmi, pedig ott még valamennyi pénz is szóbajótt. Ráadásul ott nem is volt havária, ráadásul kutyaközönséges onprem AD volt, alacsony komplexitás és rizikó.
Community sikersztori: mintha rémlene ez a februári szerver karbantartós történet. Meg is kétdezte tőlük valaki, h. árulják már el a PH milyen vason fut? Nem kell minden üzleti titkot elárulni, csak egy nagyjából válasz is elrg lett volna. Persze h. titkolóztak róla, konkrétan 0 információt osztottak meg, security-by-obscurity.
Most fogadkoznak, h. lesz majd róla post-mortem. Ezek után képzelem milyen reális leírás lesz (ha bármi is igaz belőle), kb. mint zombory cikke a unixautó ransomware sztori után: cégvezetős ömlengés amiben rádöbben h. az éves sokmilliárd forintos árbevételű autóalkatrész bizniszéhez fel kéne nőnnie az IT részlegének is. 0 technikai részlet 100% marketing bullshit. Google kereső kidobja a sztorit.
Ebben a témában a legrészletesebb talán a maersk wannacry notpetya post-mortem-jei volta, ill. a leghasználhatóbbak.
- A hozzászóláshoz be kell jelentkezni
sokan jelezték nekik hogy segítenének
Ezek szoktak eltűnni mind egy szálig, amikor valóban segíteni kéne.
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Nem mind. Igaz, más a gyakorlati segítség, mint a pénzügyi, de annak idején a téglajegyeiteket is többen megvették. Nyilván kevesebben, mint ahányan ajánlkoztak, de akkor is.
- A hozzászóláshoz be kell jelentkezni
Még akár az is lehet h. de. Ezt nyilván egy cégvezető sem fogja a világba szétkürtölni: CEO lesson 01 - nem ismerünk be semmilyen hibát. Az h. nincs pénzünk, azt még ennyire sem! Különben a kutya se fog minket komolyan venni, szerződést kötni.
IT katasztrófából minden cég ki tud lábalni. Egy év múlva kutya se fog emlékezni a sztorira. Abból h. ország-világ előtt letolt gatyával picsogunk h. csórók vagyunk, az meg örökre megmarad.
- A hozzászóláshoz be kell jelentkezni
Jaja, a felelősségvállalás kérdése egy külön dolog, azon a hídon akkor kellene átmenni amikor dönteni kell valamiről.
Ettől függetlenül ezt az utat is meg lehetett volna nyitni, legalább egy pár órás "konzultáció" erejéig vagy valami. El tudom képzelni azt is, hogy egy egyszerű iránymutatás is sokat segíthetett volna, mert ha ennyi idő alatt nem rakták rendbe az egészet az azt jelentheti, hogy sokszor rossz irányba indultak el a recovery-vel. Ennyi idő alatt akár egy ideiglenes cloud accounton mindent újra fel lehetett volna rántani...
- A hozzászóláshoz be kell jelentkezni
Állítólag hibás v. sérült a backup is. Ha nem max. 1 hetes a legutolsó hibátlan full backup, az inkrementálisok/differenciálisok végiggörgetése fájdalmas lehet. Ha ezt ráadádul bájtonként / szektoronként / DB page-enként kell helyrerakni, kézzel, az hetek...
- A hozzászóláshoz be kell jelentkezni
1 hetes a legutolsó hibátlan full backup, az inkrementálisok/differenciálisok végiggörgetése fájdalmas lehet.
Miért fájdalmas? Értelmes szoftver esetén az kb. egy snapshot lánc, amiből kivenni bármit bármelyik snapshot időpillanatből semmi fájdalmas nincs...
Ha ezt ráadádul bájtonként / szektoronként / DB page-enként kell helyrerakni, kézzel, az hetek...
Konkrétan melyik backup rendszer az, amire ilyenkor gondolsz?
- A hozzászóláshoz be kell jelentkezni
Ha ezt ráadádul bájtonként / szektoronként / DB page-enként kell helyrerakni, kézzel, az hetek...
Ekkora lapcsaládnál minimum komplett virtuális gép(ek)et / konténereket mentek és állítok vissza nem sérült, kompromittált időpillanatra. Ki az, aki nekiállna turkálni hetes melókkal? Ezt még egy ingyenes Proxmox is megugorja ...
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Csak tippelget mindenki (én is), mert hírzárlat van, és ez ideális táptalaj a fantázia meglódulásának.
Ha csendes alattomos DB sérülést okoz valami CPU bug, ami csak egy végső crash után derül ki, akkor a backup-ban sem biztos h. meg lehet bízni. Innentől a restore átváltozik recovery-vé.
- A hozzászóláshoz be kell jelentkezni
GFS mentési stratégia se egy mai találmány. Kb. minden valamirevaló mentési megoldás ismeri és feladjánlja a retention résznél.
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Nekem az a furcsa, hogy a FB posztjuk szerint ők magával a hardverrel is küzdöttek. Az első javaslatom az lett volna, hogy amíg valaki próbálja a vasat életre lehelni, addig párhuzamosan húzzunk fel egy instance-t a cloudban, és akkor egy kis guideolással együtt is 1 órán belül elkezdhetik egy stabil infrára recoverelni a DB-t.
- A hozzászóláshoz be kell jelentkezni
Én sem értem ezt a régi CPU-s dolgot.
Ha tényleg az van, hogy a hardver miatt lett a baj, akkor soha nem tennén vissza arra a gépre az éles rendszert. Javítás után jó lenne valakinek desktop-nak, vagy ha rendes szerver HW, akkor tesztrendszert futtatni, kezdőt betanítani, stb.
100-200 ezerért gyakorlatilag azonnalra van használt szerver több forrásból, ha nincs kéznél egy megbízható gép se.
- A hozzászóláshoz be kell jelentkezni
Ennyire nem értek hozzá, de nálam a var/lib/mysql meg a var/www/html mentése mindig visszaállítható volt. Nem hiszem hogy ezt a két könyvtárat valami gecibonyolult project lenne napi szinten menteni,
- A hozzászóláshoz be kell jelentkezni
Ha egy kriptovírus vitte a mentést is, akkor nem lesz olyan egyszerű ... oda már kell GFS, 3-2-1, offline / WORM adathordozón elrakott / immutable repository-ban elrakott mentés stb.
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
"IT-val foglalkozó, üzletét arra építő cégnél sincs meg a megfelelő tudás egy ilyen egyszerű helyzet elkerülésére, vagy kezelésére."
Lehet, hogy a pénz sincsen meg hozzá. (Mert manapság a reklámbevételeket sem olyan könnyű megszerezni, a yt és más globális marketingcégek árnyékában.)
Az amatőr, IT iránti lelkesedésből futó projektek mára kifulladtak, már nincsen idő, kedv, - és főként hozzá pénz sem, - az újabb dolgokkal való tapasztalatszerzésre. (Az a generáció, amelyik még fizetett is volna azért, hogy üzemeltethessen, - nem hogy ezért neki fizessenek, - lassan kikerül a temetőkbe. - Tapasztalatból beszélek, mert én is oda tartozom.)
- A hozzászóláshoz be kell jelentkezni
Egy IT tartalomgyártóhoz igen sok eszköz érkezik tesztelésre, ennek egy jó részét nem kell visszaadni. Szóval azt kizártnak tartom, hogy ha komoly elkölthető pénz nincs is azonnalra, ne lenne egy rendes PC-nyi alkatrész kéznél, amivel helyre lehet állni, és majd ha megint megy a bolt, elgondolkoznak, hogyan lehetne végleges jó megoldást találni a problémára.
Mondjuk az, hogy ennyi ideig áll, nekem inkább azt mondja, a mentés nincs meg. Merthogy egy sima webes alkalmazást kb. 30 perc életre kelteni egy bármilyen PC-n, aztán mehet vissza bele az adat.
- A hozzászóláshoz be kell jelentkezni
cpu hibát hogyan lehet kivédeni? ramra van ecc
- A hozzászóláshoz be kell jelentkezni
Valami ilyesmivel:
- A hozzászóláshoz be kell jelentkezni
A vmware-nek is van hasonló megoldása FT néven, ahol is két fizikai gép cpu utasitások szintjén is szinkronban futott. Mondjuk kiváncsi lennék egy ilyen cpu hibát megfogott volna-e, hiszen ezek szerint a hibát nem is jelezte az OS szintjére. Mondjuk eleve nagyon korlátozottan használható, annyi megkötése van.
(erősen kétlem, hogy cpu hiba lett volna)
- A hozzászóláshoz be kell jelentkezni
Az FT legfeljebb véletlenül fogja meg, ha az egyik node crashel a szétcsúszás miatt. Nagyon mélyen él azzal a feltételezéssel, hogy a két gépen a processzor ugyanarra az inputra ugyanazt az outputot kell, hogy adja. Nincs igazi lockstep benne, mint a mainframe-eknél, nincs folyamatosan szinkronbantartva vagy komparálva a memóriakép - dedikált hardver nélkül, full szoftveresen ilyet csak használhatatlanul lassúra lehetne megvalósítani. Az FT inkább olyasmi mint az adatbázis clustereknél az elsődleges node-on keletkező journal log folyamatos visszajátszása a tartalék node-on. Csak éppen itt az I/O eseményekre, interruptokra történik, időbélyeghelyesen.
Csak azt fogod látni, hogy valahogy szétesett a szinkron, de az okára semmi hint-ed nem lesz, mint ahogy arra sem, hogy melyik oldal a "helyes" és melyik a "hibás".
(Igen, én is valószínűtlennek tartom, hogy egy valós CPU hiba olyan hibajelenséget tud előidézni, hogy a gép "látszólag stabilan" crash-ek nélkül élesben szolgáltat hónapokon át, de közben csendben korruptálódik az adat.)
Régóta vágyok én, az androidok mezonkincsére már!
- A hozzászóláshoz be kell jelentkezni
Active-active cluster esetén amíg quorum+1 replika üzemszerűen működik, addig a maradék replika lehet hardverhibás, ki fog derülni, hogy garbage, amit gyárt/tárol/visszaad.
- A hozzászóláshoz be kell jelentkezni
Egy 3-as clusternél quorum+1 az pont 3 :)
- A hozzászóláshoz be kell jelentkezni
Most a hardverapron keresgetik az alkatrészeket a szerverhez.
- A hozzászóláshoz be kell jelentkezni
Szóval mindenre megoldás a felhő, mert bár nem ismerjük az oldal méretét, adatforgalmát, az adatbázist, a fórumot, de tudjuk, hogy jobb felhőben.
Ezért szeretek ide járni, a sok szakértőa bemeneti adatok nélkül is tudja a megoldást.
Nálunk az A és a B hw között az volt a különbség, hogy az egyikben 1, a másikban 2 cpu volt, gy ugyanolyan, csak 2 maggal, de az egyik specifikus sw konverziókor a 2 cpuson lassabban futott. Felhőben ezt jó debuggolni, gondolom csak úgy rongyolnak biost állítani, stb, mert a megoldás itt az volt.
- A hozzászóláshoz be kell jelentkezni
Maguk üzemeltették és már a harmadik napja áll. Hát ennél biztos jobb a felhő :D
Színes vászon, színes vászon, fúj!
Kérem a Fiátot..
- A hozzászóláshoz be kell jelentkezni
Nem vagyok benne biztos.
- A hozzászóláshoz be kell jelentkezni
Ha nem állnak fel többé, akkor azért kihirdethetjük a győztest :D (keserű röhögés)
Színes vászon, színes vászon, fúj!
Kérem a Fiátot..
- A hozzászóláshoz be kell jelentkezni
Még akkor sem, de számukra a helyi szerver megbukott
- A hozzászóláshoz be kell jelentkezni
Egy prohardver szintű és méretű oldal üzemeltetése felhőben és onprem is elég jól kivitelezhető.
Az onprem előnye, hogy olcsóbban lehet üzemeltetni, a felhő előnye pedig az, hogy brutális uptimeot tudna biztosítani többszintű redundanciával.
Egyébként nem ugyanarról beszélünk valószínűleg, mert te azt érted felhő alatt, hogy AWS vagy hasonló szolgáltatónál bérelt infrán fut az oldal és pont.
Én pedig azt értem felhő alatt, hogy AWS vagy hasonló szolgáltatónál bérelt infrán cloud native software stacken fut az oldal. A kettő között hatalmas különbség van.
- A hozzászóláshoz be kell jelentkezni
onprem előnye, hogy olcsóbban lehet üzemeltetni
Ebben a méretben ha olcsóbb, akkor biztosan nem azonos minőségű a felhővel.
Nem lesz redundáns, nem lesz mögötte enterprise-szintű backup és DRP, nem lesz 24h support, nem lesz megfelelő dokumentáció, nem fog megfelelni a releváns iparági policyk-nak, nem lesz biztonságilag rendszeresen tesztelve - pont azok fognak hiányozni, ami a felhő legnagyobb hozzáadott értékei.
- A hozzászóláshoz be kell jelentkezni
Igy van, nem is irtam, hogy azonos minosegu lesz :)
- A hozzászóláshoz be kell jelentkezni
Nincs ilyen előny, egzaktul legalábbis nincs.
Van amikor olcsóbb, van amikor drágább.
Van amikor azonnal drágább (mert többet fizetsz érte havi szinten) és van amikor hónapok vagy évek múlva lesz drágább amikor hirtelen annyit kell rákölteni amennyinek a töredékéből kifutott volna addig a felhőben is.
Ez természetesen a szoftvertől és a benne futó dolgoktól függ.
- A hozzászóláshoz be kell jelentkezni
Szóval mindenre megoldás a felhő, mert bár nem ismerjük az oldal méretét, adatforgalmát, az adatbázist, a fórumot, de tudjuk, hogy jobb felhőben.
Te se tudod az oldal méretét, adatforgalmát, az adatbázist, a fórumot, de tudod, hogy nem jobb felhőben... :D
Nekem most van egy projektem épp, 2x6 node, 48 core, 160 GB memória, 2400 GB storage, ~200 USD havonta, felhőben. A rajta lévő rendszer alapján azt mondom, hogy a PH valószínűleg lötyögne benne. Ilyen költségekről beszélünk.
- A hozzászóláshoz be kell jelentkezni
Kételkedem. Nem jó mindenre a felhő.
- A hozzászóláshoz be kell jelentkezni
Kételkedem. Nem jó mindenre a felhő.
PH-féle dolgok kiszolgálására pont jó. Amúgy most épp ott tartunk a topic kapcsán, hogy nem jó az on-prem.
- A hozzászóláshoz be kell jelentkezni
Ez itt nem on-prem hiba, hanem üzemeltetési. On-Prem is lehet üzemeltetni jól. Meg felhőben is szarul.
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Szövegértés. Nem azt írtam, hogy ez on-prem hiba, még csak azt se, hogy az on-prem generálisan rossz, hanem azt írtam, hogy a PH jellegű workload futtatására a felhő sokkal jobb és az on-prem meg nem jó rá, mert on-prem drágábban lehet ilyet üzemeltetni és még drágábban lehet jól üzemeltetni. Felhőben szó szerint fillérekért van minden szükséges szolgáltatás magas rendelkezésre állással, inclusive szakemberekkel, akik ezt csinálják napi 8 órában váltásban évek óta és nem 24-48-72 órája nézik üveges szemekkel a problémát és keresik a pót-pót hardvert. Továbbra is tartom azt, hogy a PH jellegű feladatra nem jó az on-prem, a felhő sokkal jobb.
- A hozzászóláshoz be kell jelentkezni
Attól függ, mert ha amúgy is kell egy saját infrát fenntartani, akkor azon egy ilyen lófasz pont elfér kb. kerekítési hiba a futtatása és üzemeltetése. De, ha nincs, akkor valóban olcsóbb lehet a felhő. Mondjuk a korrektség kedvéért, mentés beállítása nélkül a felhő pont annyit ér, mint az on-prem.
Abban meg szinte biztosak vagyunk, hogy ez nem HW probléma, hanem mentés körüli (pontosabban, annak meg nem léte vagy használhatósága). Ezen a felhő nem segít.
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Attól függ, mert ha amúgy is kell egy saját infrát fenntartani, akkor azon egy ilyen lófasz pont elfér kb. kerekítési hiba a futtatása és üzemeltetése.
Oké, de a PH-nál mi ez az "amúgy is kell egy saját infra" valami olyanra, aminél a PH webes része "ilyen lófasz kerekítési hiba"? Az egész szál arról szól, hogy PH workload-ra jó-e az on-prem vagy mehetnének felhőbe.
- A hozzászóláshoz be kell jelentkezni
Nem ismerem az oldalt, sem a mögötte levő céget, tőlem aztán lehetne kisebb internetszolgáltató is mögötte, mellette. Miért ne lehetne? Valamiért ők üzemeltették, feltételezhető, hogy nem egy bádogdobozt tartanak valahol otthon az előszobában :D
Ha nincs infrájuk, akkor sem biztos, hogy a felhő az egyetlen megoldás. A Rackforest pl. ad fizikai dedikált szervert, 2 órán belüli garantált hibaelhárítással, meghibásodás esetén cserehardverrel (átteszik a diszkeket egy pont ugyanolyan vasba), igény esetén teljes üzemeltetéssel. Nem muszáj azonnal a felhőbe futni.
Mindezt havi 15 ezertől.
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
A Rackforest pl. ad fizikai dedikált szervert, 2 órán belüli garantált hibaelhárítással, meghibásodás esetén cserehardverrel (átteszik a diszkeket egy pont ugyanolyan vasba), igény esetén teljes üzemeltetéssel.
^ ez ugyanúgy felhő.
- A hozzászóláshoz be kell jelentkezni
Ez egy fizikai vas, rendes hosting-ban. Ez már felhő? Mikortól lett ez felhő? Ezek már a felhő előtt léteztek, hosting, colo anyámkínja' néven.
Jó, a felhő kifejezés aztán sok mindent elbír, bármit rá lehet húzni.
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Ez egy fizikai vas, rendes hosting-ban. Ez már felhő? Mikortól lett ez felhő? Ezek már a felhő előtt léteztek, hosting, colo anyámkínja' néven.
Mindig is felhő volt, felhő az az erőforrás az interneten (“somewhere out there”), ami nem a tied és nincs közvetlen kontrollod felette. Megnézel architektúra rajzokat még a "felhő" éra előtti időből ('90 évek vagy a kétezres eleje), azokon is ott volt már a felhő rajz, ami azokat a dolgokat jelentette, amikhez az interneten keresztül kapcsolódik a rendszer és valaki más szervere, szolgáltatása, megoldása, cucca, a felhő konkrétan erről kapta a nevét.
A colocation az nem felhő, mert ott a tiéd a vas, a DC nem a tied. A hosting - a szó eredeti értelmében - már felhő az ügyfél szempontjából, mert ott nem az övé a vas, csak igénybe veszi, mint szolgáltatást.
Jó, a felhő kifejezés aztán sok mindent elbír, bármit rá lehet húzni.
Igazából egészen jó definíciója van, szinte minden cloud, amikor a vas nem on-prem: "The cloud is a network of remote servers on the internet that store, manage, and process data, allowing users to access computing resources on demand without owning or managing the physical infrastructure."
- A hozzászóláshoz be kell jelentkezni
Azért ez is érdekes, hogy a felhő szót hányan hányféleképpen értelmezzük.
Nálam ha felhőszolgáltatóról beszélünk az azért egy teljesen minimális elvárás, hogy valami API-n keresztül tudjak létrehozni VM-et, vagy bármilyen resource-t, skálázódás stb...
- A hozzászóláshoz be kell jelentkezni
Azért ez is érdekes, hogy a felhő szót hányan hányféleképpen értelmezzük.
Ami nem on-prem, az felhő, a "cloud" eredeti definíciója szerint. Aztán üzleti okokból ezt sokan és sokféleképpen kisajátították.
Nálam ha felhőszolgáltatóról beszélünk az azért egy teljesen minimális elvárás, hogy valami API-n keresztül tudjak létrehozni VM-et, vagy bármilyen resource-t, skálázódás stb...
Akkor a Hetzner bare metal szolgáltatása cloud, mert API-n keresztül tudsz kérni és visszaadni fizikai vasat? :)
- A hozzászóláshoz be kell jelentkezni
"Akkor a Hetzner bare metal szolgáltatása cloud, mert API-n keresztül tudsz kérni és visszaadni fizikai vasat? :)"
Igen, én tudok rájuk felhőszolgáltatóként tekinteni. Ezzel együtt egy másik posztban már leírtam, hogy SZERINTEM ahhoz, hogy valamire azt mondjuk, hogy a felhőben fut, ahhoz kell alá egy cloud native software stack is.
"Ami nem on-prem, az felhő, a "cloud" eredeti definíciója szerint."
Ki definiálta eredetileg?
https://en.wikipedia.org/wiki/Cloud_computing
A lényeg, hogy a Rackforestet nem nevezném felhőszolgáltatónak, szerintem saját magukat sem gondolják annak, ebben szerintem megegyezhetünk.
- A hozzászóláshoz be kell jelentkezni
Minden nemOnPrem, ahol 1 külső cég túszul tudja ejteni még a te saját tulajdonú szerveredet is, ha bármi elszámolási vitátok adódik, és nem engedi h. kihozzad a saját vasadat az épületükből.
- A hozzászóláshoz be kell jelentkezni
Egyetértek, de ha már így bedobtad a témát, erre a konkrét feladatra jó a felhő, vagy sem? Ha nem, miért nem?
- A hozzászóláshoz be kell jelentkezni
Bocs, de ha a számok igazak akkor valamilyen infót nem osztottál meg. Milyen felhőszolgáltatónál van ez? Valami reserved instance marketplace? Ennyi erőforrás eladása ezen az áron nem rentábilis normál esetben.
- A hozzászóláshoz be kell jelentkezni
Nekem is gyanusan olcsó levesnek tűnik.
- A hozzászóláshoz be kell jelentkezni
Scaleway + Hetzner; VPS és bare metal vegyesen; tetején van egy K8s, cloud-init + terraform script alapján felhúzva. Ott tartunk, hogy például egy XEON E-2176G, 64 GB ECC memória, 2x1TB NVMe az ~29 USD havonta éves commitment esetén, kisebb vasak olcsóbbak, a kis VPS pedig pláne aprópénz. API-n keresztül turkálva zero-administration, és ha kiesik egy vas, akkor kapsz másikat, többnyire automatikusan.
Az Amazon/Google/Microsoft más pályán focizik, és az ügyfeleiknek is más termékek fontosak, nem is kapsz bare metal szervert tőlük, főleg olcsón nem. Ott is lehet játszani spot instance és egyebekkel, de érdemes inkább felhőként használni, SaaS alapon, nem pedig a darab vasban gondolkodva. Ha gépeket kezdesz számolni tervezéskor a felhőben, akkor már rég rossz az architektúra a felhős üzemre. Ha viszont gépekben akarsz számolni, akkor van sok olcsó lehetőség, azzal nem érdemes az említett trióhoz menni.
- A hozzászóláshoz be kell jelentkezni
Scalewayről nem is hallottam :O
Köszi, megnézem, ez szinte hihetetlennek tűnő ár amit írsz.
AWS/GCP/Azure trió ennyi resourceért akár 10x árat is elkér.
- A hozzászóláshoz be kell jelentkezni
Ajánlott linkek:
- https://www.hetzner.com/sb/
- https://www.scaleway.com/en/dedibox/
AWS/GCP/Azure trió ennyi resourceért akár 10x árat is elkér.
Mert ők nem abból akarnak élni, hogy VPS-t adnak, kivéve, ha találnak olyan balfaszt, aki azt vesz, drágán.
- A hozzászóláshoz be kell jelentkezni
"Mert ők nem abból akarnak élni, hogy VPS-t adnak,"
Ezt hogy érted?
"kivéve, ha találnak olyan balfaszt, aki azt vesz, drágán."
Nem is keveset találnak. A világ összes pénzét hagyják ott a nagy cégek. Látom a számlákat.
- A hozzászóláshoz be kell jelentkezni
Ezt hogy érted?
Ők alapvetően SaaS szolgáltatást adnak el, amiben nem számít, hogy náluk az hány gépen fut, nem a gépek után fizetsz.
Nem is keveset találnak. A világ összes pénzét hagyják ott a nagy cégek. Látom a számlákat.
Mert balfaszok, és gépekben meg szerverekben gondolkodnak, amikor felhőben és szolgáltatásokban kellene. Amikor az email infrastruktúrádat beviszed felhőbe és gépeket veszel, ahogy ugyanazok a szoftverek futnak, mint on-prem, akkor bizony legombolnak rólad sok pénzt, és ugyanannyi emberi erőforrás kell ahhoz, hogy üzemeltesd. Ha veszel email szolgáltatást, akkor olcsó lesz és nem kell hozzá saját ember üzemeltetni.
- A hozzászóláshoz be kell jelentkezni
Ezt szerintem máshogy is lehet nézni. Amikor számítási kapacitást nézel, akkor így is úgyis VCPU-ban számolsz, ha saját szoftvert futtatsz akkor annak RAM kell. Managed kubernetes esetén ezeket ígyis úgyis ki kell fizetned. Ráadásul az a helyzet, hogy minél absztraktabb SaaS service-t veszel igénybe, fajlagosan annál többe fog kerülni egységnyi erőforrás.
Mondjuk amikor a saját szoftvered futtatásához kell 500 VCPU meg 1TiB RAM, akkor az fog kijönni, hogy ezt AWS-en futtatva annál olcsóbb minél kevesebb managed service-t veszel igénybe. És akkor itt jön be az, hogy a cégnél meddig terjed az üzemeltetési kompetencia. Tehát nem fog mondjuk a cég saját K8S-t felhúzni, hanem kér egy EKS-t, de nem fizet ki plusz pénzt az ECS-ért vagy Fargate-ért.
- A hozzászóláshoz be kell jelentkezni
Ezt szerintem máshogy is lehet nézni. Amikor számítási kapacitást nézel, akkor így is úgyis VCPU-ban számolsz, ha saját szoftvert futtatsz akkor annak RAM kell.
Nem, akkor megnézed pricing, hogy mennyibe kerül adott kapacitás, és nem érdekel, hogy a SaaS szolgáltató azt öt vagy száz géppel oldja meg. Amikor veszel például email szolgáltatást, akkor nem érdekel, hogy a Microsoft azt hány géppel szolgálja ki, nem érdekel, hogy milyen szoftvert használ, te kapsz egy UI-t, API-t, egyebet, amivel használod. Ha jön az, hogy "én saját szoftvert futtatok" és vCPU meg RAM és storage a számolás alapja, akkor nem az Amazon/Microsoft/Google a legjobb választás. Adnak ők ilyet is, csak aztán vastag lesz a ceruza a számlán.
Managed kubernetes esetén ezeket ígyis úgyis ki kell fizetned.
Ott is az van, hogy akkor kell felhő, ha nem tervezhető a workload, vagy tervezhető, de az idő nagy részében nincs terhelve. Ha ott fut valami saját szar konstans, n darab node-on, akkor újra ott vagyunk, hogy a cég balfasz, jobban jár on-prem vagy bérelt bare metal szerverrel.
Ráadásul az a helyzet, hogy minél absztraktabb SaaS service-t veszel igénybe, fajlagosan annál többe fog kerülni egységnyi erőforrás.
Nem, ez fordítva szokott lenni. Minél inkább SaaS-t veszel igénybe, annál olcsóbb. Minél inkább n darab vasban gondolkodsz, annál drágább.
Mondjuk amikor a saját szoftvered futtatásához kell 500 VCPU meg 1TiB RAM, akkor az fog kijönni, hogy ezt AWS-en futtatva annál olcsóbb minél kevesebb managed service-t veszel igénybe.
Konstans kell 500 vCPU és 1 TiB RAM? Akkor ez nem felhőbe való. Ha kell max 500 vCPU meg 1 TiB RAM, de mondjuk egy évre átlagolva kell 50 vCPU és 100 GiB RAM, akkor felhőbe való, mert kurva sokat lehet spórolni azon, hogy nem veszed meg a 10x akkor vasat, mint amennyi kell belőle. Nagyon sok cégnél nem értik a felhős dolgot, az Amazon/Microsoft/Google pedig dörzsöli a kezét, ahogy ezeket a balfaszokat megkopasztja.
- A hozzászóláshoz be kell jelentkezni
Ez messze nem ilyen egyszerű. Azért veszek azure-ban vm-et az egyedi szolgáltatásomhoz, mert az belülről éri el, a kifelé nem is publikált milliónyi azure saas szolgáltatást, sokkal gyorsabban, sokkal jobban managelve, mint bárhonnan máshonnan.
Ez nem igy működik, hogy valaki csak vm-et használ, vagy csak saas-t és akkor hülye, ha vm-et használ nagy szolgáltatónál.
Mondjuk abban sem vagyok biztos, hogy a filléres szolgáltatáson vett vm tényleg megbizható-e.
- A hozzászóláshoz be kell jelentkezni
Ez messze nem ilyen egyszerű. Azért veszek azure-ban vm-et az egyedi szolgáltatásomhoz, mert az belülről éri el, a kifelé nem is publikált milliónyi azure saas szolgáltatást, sokkal gyorsabban, sokkal jobban managelve, mint bárhonnan máshonnan.
Melyik Azure SaaS szolgáltatás nem tud private network lehetőséget?
Ez nem igy működik, hogy valaki csak vm-et használ, vagy csak saas-t és akkor hülye, ha vm-et használ nagy szolgáltatónál.
Hát pedig de. Aki kopasz VM-et vesz Amazon/Microsoft/Google felhőben, az gazdag hülye.
Mondjuk abban sem vagyok biztos, hogy a filléres szolgáltatáson vett vm tényleg megbizható-e.
Nem, nem az, soha semmi nem megbízható, ezért kell összefogni őket pool-ba sok node-al, ami elviseli, ha kiesik egy-egy node vagy egy egész DC.
A Microsoft se garantál amúgy semmit a VM-re, 95% az alap SLA, ha prémium VM, akkor 99,9%; és ha megsértik, akkor arányos előfizetési díjat kapsz vissza, oszt ennyi. Ezért vannak AZ-k és régiók; 2x3 VM az (két régió 3-3 zone), amire azt lehet mondani, hogy megbízható.
- A hozzászóláshoz be kell jelentkezni
"Melyik Azure SaaS szolgáltatás nem tud private network lehetőséget?"
Mi az az azure private network? Private link-re gondolsz? Azt kb mindegyik tudja, de attól még nem lesz a vm-ed bent az azure networkjében, sem sebességben, sem biztonságban, sem sehogy. Csak éppen eléred egy gagyi vpn-en (vagy csilliárdba kerülő dedikált vonalon) a belső network-öt.
Tehát, aki igy akarja a játék dc-ben futó vm-ét komoly saas mögé tenni, az nagyon el van tévedve.
Nem érted, hogy mire gondolok megbizhatóságon. A 10 dolláros pistike vm-jében én semmi kritikust nem futtatnék, nem azért, mert rosszabb lesz az sla-ja mint a microsoft-é (pedig rosszabb lesz) hanem mert nem tudod mikor nyomnak rajta egy snapshot-ot és viszik az adataidat a futó gépedből. Vagy az üzemeltető, vagy a ki-be sétáló hackerek. Egy azure-ban pár nagyságrenddel kisebb ennek az esélye, arról nem beszélve, hogy milyen management, automatizáló, felügyeleti eszközkészletet kapsz egy azure vm-ben és mit a pistike bt vm-jében.
- A hozzászóláshoz be kell jelentkezni
Mi az az azure private network? Private link-re gondolsz? Azt kb mindegyik tudja, de attól még nem lesz a vm-ed bent az azure networkjében, sem sebességben, sem biztonságban, sem sehogy. Csak éppen eléred egy gagyi vpn-en (vagy csilliárdba kerülő dedikált vonalon) a belső network-öt.
És ez azért rosszabb, mint ugyanott egy VM, mert ... ?
Tehát, aki igy akarja a játék dc-ben futó vm-ét komoly saas mögé tenni, az nagyon el van tévedve.
Mi a játék DC és mi a komoly SaaS itt ebben a mondatban?
A 10 dolláros pistike vm-jében én semmi kritikust nem futtatnék, nem azért, mert rosszabb lesz az sla-ja mint a microsoft-é (pedig rosszabb lesz) hanem mert nem tudod mikor nyomnak rajta egy snapshot-ot és viszik az adataidat a futó gépedből.
A Pistike VM és az Azure között azért van pár fokozat a skálán, nem ez a két véglet létezik, elég nagy baj lenne, ha ennyire leredukálódna a világ. Persze vitázni könnyű ilyen szalmabábokkal, csak a valósághoz sok köze nem lesz.
Egy azure-ban pár nagyságrenddel kisebb ennek az esélye, arról nem beszélve, hogy milyen management, automatizáló, felügyeleti eszközkészletet kapsz egy azure vm-ben és mit a pistike bt vm-jében.
Tipikusan az szokott lenni, hogy nem a szolgáltatón át jutnak be, hanem azért, mert a VM gazdája hagy nyitva kiskaput. Nézd, fogalmam nincs, hogy mit akarsz vitatni és hova akarsz eljutni. És, mint írtam, nem csak Pisitike Bt és az Azure van a világon, mint két lehetséges opció.
- A hozzászóláshoz be kell jelentkezni
"És ez azért rosszabb, mint ugyanott egy VM, mert ... ?"
Komolyan? A gagyi vpn-ed azért rosszabb, mert tiz vagy százszoros pinggel éred el a saas infrát, töredék sávszélen, nincs managelve ugyanazokkal a toolokkal, amivel minden mást is managelsz, a rendelkezésre állása a töredéke lesz az azure-on bent ülő vm-hez képest, soroljam még?
A dedikált azure link pedig mondjuk 100x-osába fog kerülni havonta, mint a vm, ne hülyéskedjünk már... (ha egyáltalán ki tudod épittetni az akciós vps-edhez)
"Mi a játék DC és mi a komoly SaaS itt ebben a mondatban?"
A játék DC a gagyi szolgáltató vps-e, a komoly saas pedig pl. az azure. És te ezt a kettőt próbálnád meg összekötni, együtt managelni, felügyelni, automatizálni. Nonsense. Főleg komoly vállalati méretben.
Teljesen mindegy, hogy pistike bt felett van-e a szolgáltató, ha egyszerűen az alap problémát sem érted, hogy nem tudod ugyanazokkal a tool-okkal a kettőt kezelni. (és akkor a sávszél, késleltetés, biztonság, rendelkezésre állás problémáján sem tudtál túljutni)
- A hozzászóláshoz be kell jelentkezni
Mint írtam van több fokozat a gagyi VPS és játék DC meg az Azure között, nem csak ez a két fokozat létezik. És továbbra is légből kapott számokkal kitömött szalmabáb, amiről vitázni próbálsz, olyan dolgokra reagálva, amit én nem írtam. Ha abba tudod hagyni a szalmabáb-érvelést, akkor tudjuk folytatni, ha nem tudod abbahagyni, akkor meg abbahagytuk itt, vitázz a szalmabábjaiddal.
- A hozzászóláshoz be kell jelentkezni
Bedobtál egy bődületes butaságot: hülye aki a 3 nagy szolgáltatónál vm-et vesz.
Felsoroltam egy rakás érvet, hogy miért butaság amit mondasz és miért sokkal szarabb bizonyos esetekben más szolgálatónál venni a vm-et, de fel sem fogtad, zéró érvet tudtál hozni a butaságod alátámasztására.
- A hozzászóláshoz be kell jelentkezni
Bedobtál egy bődületes butaságot: hülye aki a 3 nagy szolgáltatónál vm-et vesz.
Innen indultunk: "Minél inkább SaaS-t veszel igénybe, annál olcsóbb. Minél inkább n darab vasban gondolkodsz, annál drágább."
Minden más a te szalmabábod, ami érveket felsoroltál, az mind szalmabáb érv volt, fel se fogtad, hogy honnan indultunk, ráharaptál kontextuson kívüli fél mondatra.
- A hozzászóláshoz be kell jelentkezni
Persze-persze, de azért ideteszek pár örökérvényű bölcsességed a szálból, hogy mindenki hülye, meg balfasz aki vm-et vesz a nagyoktól:
"Mert ők nem abból akarnak élni, hogy VPS-t adnak, kivéve, ha találnak olyan balfaszt, aki azt vesz, drágán."
"Mert balfaszok, és gépekben meg szerverekben gondolkodnak, amikor felhőben és szolgáltatásokban kellene."
Hogy a vpn-ekről miket hadováltál, hogy egyenértékű lenne 3rd party vps-en, egy azure-ban futó vm-el, az is beszédes.
De tényleg zárjuk, mert elég jól ki lett vesézve, alá lett tényekkel támasztva, hogy miért is van létjogosultsága az azureban (vagy bármelyik nagynál) futó vm-ek millióinak. (mindenki hülye csak te vagy helikopter esete)
- A hozzászóláshoz be kell jelentkezni
Mindenkinek van igaza szerintem. Valószínűleg kis és közepes cégeknél meggondolandó, hogy tizedáron vegyenek igénybe cloud szolgáltatásokat, míg az is érthető, hogy egy nagy nemzetközi multi nem akarja egy nála lényegesen kisebb cégre bízni a teljes IT infrastruktúráját meg azt amit az ügyfeleinek tovább értékesít. Ez a jó, hogy úgy látszik manapság mindenki megtalálja a neki ideális szolgáltatást/árazást.
- A hozzászóláshoz be kell jelentkezni
Aki kopasz VM-et vesz Amazon/Microsoft/Google felhőben, az gazdag hülye.
Vagy csak van egy felépített ökoszisztémád, amibe valamiért kell VM is, akkor pár száz dolláros éves kiadás miatt nem baszakszol filléres VPS providerekkel, hanem megcsinálod helyben.
Ha beesel random az utcáról, és aláírsz egy évre, instant elengedik a harmadát. Innen kezdődik egyáltalán az alkudozás. Nem olyan drága az, mint gondolod. Hobbiprojekt alá drága, azt aláírom.
- A hozzászóláshoz be kell jelentkezni
Arrol nem is beszelve, hogy ha szerte vannak VPS-ek, akkor az external traffic is penzbe kerul, ami nem feltetlen elhanyagolhato osszeg. Mig AZ-n belul ingyenes, de a cross-AZ traffic is olcsobb, mint a teljesen external.
Raadasul stretch clusterek eseten figyelni kell, hogy biztos hogy minden node-to-node, pod-to-pod/process-to-process traffic encryptalt-e, mig VPC-n belul ez kevesbe fontos.
- A hozzászóláshoz be kell jelentkezni
Meg ugye attól függ melyik országbéli az a "hülye". Nyugatabbra jobban megéri kifizetni akár egy instance után is évi 1-2 millió forintot, mint ezért fizetni valakit pluszban, venni, üzemeltetni felszerelést hozzá.
Persze, ha úgy állnak hozzá, hogy minimálbéres pistike úgyis ott van és egyel több doboz a raktárban nem számít, akkor lehet jól jön ki a matek. Addig 100% lesz a rendelkezésre állás, amíg el nem romlik valami, aztán meg 0.
Árak: btw, múltkor el kellett égetnem maradék nvidia kreditet aws-en és naivan kiszámoltam, hogy majd 1 ilyen 8xh200-as gpu instance, erre kiderült, hogy csak foglalással lehet és harmad áron a listaárhoz képest. Kellett indítanom 3at :D Jó, ez extrém példa volt. De sokmindennél simán megérheti vm felhőben. A dolog titka az, hogy bevételt termelő munkához kell, ami nem mindig van meg a cégek projektjeinél és akkor megy a varázslás.
- A hozzászóláshoz be kell jelentkezni
Meg ne vicceljünk már, ha van egy saas infrám azure-on, automatizálva, felülgyelve, kezemben minden tool, akkor majd elkezdek egy nyamvadt vm-et egy gagyi, de olcsó szolgáltatónál, szar weboldalakon konfigurálni? Mert mondjuk 50 dollárral olcsóbb havonta?
Ilyenkor elgondolkozik az ember, hogy aki ilyet az az otthoni bohóckodásáról beszél, vagy egy normális vállalat, komolyan vehető infrájáról beszél-e. Mert valaki lehet, hogy tényleg hülye, de nem az, aki azure/aws/gcp-n vm-et futtat.
- A hozzászóláshoz be kell jelentkezni
gpt-ztem róla, nekem is felkeltette az érdeklődésemet. 192GB RAM-os bare metal gép lenne kb 100 ejró amiért VM gép esetén max 32GB-osat kapok.
idézem:
"Miért lehet olcsóbb a bare metal szerver, mint a VPS?
1. Régebbi, de még megbízható hardver
A Xeon E5-2600 széria kb. 8–10 éves (Sandy Bridge – Haswell generáció).
Ezt a gépet már rég amortizálták: a Scaleway számára a hardver bekerülési költsége már „nulla közeli”, csak a villanyt és karbantartást fizetik.
A nagy RAM (192 GB) és 2×8 TB HDD nem SSD/NVMe, így olcsóbb komponensek.
A virtualizált gépeket gyakran újabb, drágább NVMe-s, CPU-intenzívebb hypervisor gépeken futtatják, és drága redundáns storage-rendszert is igényelnek.
2. Alacsonyabb szolgáltatási szint és kényelem
Ez a bare metal szerver csupasz gép, nincs:
Snapshot
Backup
Magas rendelkezésre állás
Tűzfal UI
Hálózati redundancia
A VPS viszont menedzselt, magasabb SLA-val, storage failover-rel, sokkal több kényelmi extrával.
Egy Bare Metal szerver „csináld magad” jellegű, míg a VPS „készen tálalt”, és ezért drágább."
- A hozzászóláshoz be kell jelentkezni
Hja, és ezért érdemes vegyesen VPS és bare metal, egy cluster-ben. :)
- A hozzászóláshoz be kell jelentkezni
Scaleway-t csak ajánlani tudom, remek ár-érték arány.
Ha tartós rendszert építesz és okos csapatot nevelsz, akkor száz kiadásban sem érheti baj; ha csak a gépekre hagyatkozol, akkor egyszer jól jársz, máskor rosszul; de ha sem a rendszer nem bírja a terhet, sem a csapat nem tanul a hibákból, akkor minden egyes kiadás kockázat.
- A hozzászóláshoz be kell jelentkezni
Én egyébként a Scaleway + Hetzner kombót szoktam ajánlani, ha kell bare metal és/vagy VPS alapú cluster ügyfélnek. Stabil, nagy cégek, rendes support van, nem túl olcsó, nem túl drága. Kezdenek SaaS szolgáltatásokat is adni, de az még nem az erősségük.
- A hozzászóláshoz be kell jelentkezni
Puszta kíváncsiságból egy kérdés és lehet ezt egy másik topikba kell majd folytatni :D, de mi az oka annak, hogy bare metal és/vagy VPS-re nem Magyar szolgáltatókat javasolsz? Nyilván itthoni felhasználásra értem, bár nemzetközire is érdekes lehet a kérdés.
Minden tapasztalat, észrevétel jöhet.
Köszi
- A hozzászóláshoz be kell jelentkezni
Puszta kíváncsiságból egy kérdés és lehet ezt egy másik topikba kell majd folytatni :D, de mi az oka annak, hogy bare metal és/vagy VPS-re nem Magyar szolgáltatókat javasolsz? Nyilván itthoni felhasználásra értem, bár nemzetközire is érdekes lehet a kérdés.
Nem hazai az ügyfél. Másrészt, ha hazai lenne, akkor is méretgazdaságosságból ezt a kettőt javaslom.
Mondok példát, Rackforest, bare metal bérlés, 6/12 CPU, 16 GB RAM, storage nélkül nettó 50 ezer forint havonta, vagyis ~120 EUR. Hetzner ad 6/12 CPU, 64 GB RAM, 2x960 SSD ~35 EUR. Scaleway Dedibox 6/12 CPU, 32 GB RAM, 2x500 GB SSD 45 EUR havonta. Másik példa, Rackforest, VPS bérlés, 4 vCPU, 8 GB RAM, 80GB SSD, 6400 forint ~16 EUR. Hetzner ugyanez 8 EUR.
Egyszerűen anyagilag nem éri meg magyar szolgáltató, nettó áron se.
- A hozzászóláshoz be kell jelentkezni
Szeirntem az ár. Mikor utoljára mértük jelentősen drágább volt itthon minden.
- A hozzászóláshoz be kell jelentkezni
Ráadásul, akinek ez ideológiailag fontos, ez európai felhőszolgáltatás.
- A hozzászóláshoz be kell jelentkezni
de érdemes inkább felhőként használni, SaaS alapon, nem pedig a darab vasban gondolkodva
*PaaS, nem? :)
- A hozzászóláshoz be kell jelentkezni
Ez az egész leállás egy nevetséges majomparádé bárkinek akinek van kicsit is komolyabb üzemeltetési tapasztalata.
Rackforest a megkereséstől számítva pár órán belül ad dedikált gépet, 20 Xeon fizikai magos gép hardware raid-del 75 nettó havonta, kell még bele plusz ram meg diszk és kész.
Alap linux meg a csomagok feláll rajta 1 órán belül, környezet bekonfigolva max még 1 óra (elvégre minden confignak a backupban kell lennie), a data backup mire lefut azt nem tudjuk, de hogy nem 2 nap az szinte biztos :)
Ha ennyi pénzt nem termel ki az a lapcsalád akkor meg nincs miről beszélni.
Ha nem volt backup és azért kókánykodnak az eredeti gép helyreállításával akkor meg megint nincs miről beszélni.
Ekkora leállást nem lehet kimagyarázni senkinek aki kicsit is ért ehhez, ez színtiszta garázspistike balfaszkodás.
- A hozzászóláshoz be kell jelentkezni
Szánalmasak, egyetértek.
Ismerek olyan céget, akik biztosítottak számukra - akkoriban - nagyon komoly szervert. Fizetni nem tudtak azaz inkább nem akartak érte… ez mindent elmond a core csapatról ;-)
- A hozzászóláshoz be kell jelentkezni
core csapat :D :D :D :D a helyzetből látszik, hogy itt nagyjából egy emberről van szó. Esetleg van még egy, aki egy-két ötlettel beszáll.
- A hozzászóláshoz be kell jelentkezni
A közleményekből sorok között olvasva nekem az derült ki, hogy már az első nap vége óta valójában nem a géppel van a probléma ("a régi processzort visszaraktuk, azóta először stabil a gép"), hanem az adatokkal.
Valószínűleg most jöttek rá, hogy korruptálódott a backupjuk is és gondolom abból próbálják valahogy manuálisan menteni a menthetőt. Aminek a sikerére sajnos - ne legyen igazam - nem sok esélyt adok...
Régóta vágyok én, az androidok mezonkincsére már!
- A hozzászóláshoz be kell jelentkezni
Arra nem hiszem inkabb arra, hogy korrumpálódott...
- A hozzászóláshoz be kell jelentkezni
Szerintem csak emberre vonatkoztatva használjuk így és kicsit mást is jelent...
De ha jobban tetszik, tekintsd úgy mintha azt írtam volna "korrupt lett a backupjuk is".
Régóta vágyok én, az androidok mezonkincsére már!
- A hozzászóláshoz be kell jelentkezni
Tenyleg semmi backujpjuk nem volt? Mert mar elertek azt a pontot, hogy visszaaljanak egy egy hetes backuprol es par napnyi adat elvesztese kisebb arcvesztes mint a teljes leallas ilyen hosszan.
- A hozzászóláshoz be kell jelentkezni
Tenyleg semmi backujpjuk nem volt?
Lehet, hogy volt, a kérdés az, hogy corrupted-e és/vagy teljes mentés-e, integritása megfelelő-e és a környezet visszaállítható-e, ha az adatokat visszaállították. Az is kérdés, hogy volt-e próbálva a mentésből való visszaállás, időnként érdemes mentésből visszaállni, főleg, ha mondjuk hardvercsere vagy infrastrukturális változás van, abból kiderül, hogy minden benne van-e a mentésben. De ezek mind idő és szakértelem.
Mert mar elertek azt a pontot, hogy visszaaljanak egy egy hetes backuprol es par napnyi adat elvesztese kisebb arcvesztes mint a teljes leallas ilyen hosszan.
A már említett Recovery Point Objective (RPO) és Recovery Time Objective (RTO) koncepció teljesen hiányzik, ahogy nincs BCP se. Az RTO esetén azt mondod, meg, hogy mennyi állásidő után lesz backup alapján visszaállás, mondjuk 8 óra állás után már nem próbálsz üzemszerű állapotot elérni a rendszerrel, hanem radír és korábbi mentésből visszaállsz, vállalva az adatvesztést. Az RPO meg azt mondja meg, hogy mennyi időnként van visszaállási pontod, mennyi ez az adatvesztési idő, amennyit még tolerálsz. Itt nem kell komplex dologra gondolni, csak legyen egy pár tételes plan, hogy mit kellene csinálni, ha...
Adott esetben lehetne read-only visszaállni mentésből, amíg a prod rendszerről próbálják visszanyerni az élő adatokat.
Kíváncsi vagyok a post mortem cikkre, hogy mi történt és hol ment félre az egész.
- A hozzászóláshoz be kell jelentkezni
Jegcsakany kell meg szogbelovo!
Lofaszt! Ne adjatok neki semmit!
Vegyetek el a kabatjat is…
- A hozzászóláshoz be kell jelentkezni
Úgy ütsz, mint egy buzi..
- A hozzászóláshoz be kell jelentkezni
Sztálin '56-ban ledöntött szobrának mutatóujja :)
- A hozzászóláshoz be kell jelentkezni
Cipő, zokni, százmillió dollár, a szokásos cucc.
- A hozzászóláshoz be kell jelentkezni
Na, most kitettek egy újabb, hosszabb FB postot, de az is teljes mellébeszélés, Balatonon voltak, és fontosabb dolguk volt az oldalnál, meg közgazdasági matek, meg 64 magos proci, meg a vas stabiliizálása. Semmivel több konkrétumot nem ír, mint az eddigiek.
Amit a biztonsági mentésről ír, hogy az nem volt teljes, az automata mentések sérültek, a kéziek megvannak, de így se teljesen visszaállítható, magyarán nem teljes mentés. Nekem az jön le, hogy ez nem egy sztenderd SQL adatbázisszerver volt, hanem mappákba osztott, fájlokra tovább szétosztott flat adatbázis borult meg, valami egyedi garázsfejlesztés.
Mondom, én nem kívánom a vesztüket, remélem helyre tudják állítani, még ha részlegesen is, de a nagyját. Amit nem ért a PH-es bagázs, hogy nem az emberek rosszindulatúak, hanem ők arrogánsak a usereikkel, lekezelően kommunikálnak.
“Windows 95/98: 32 bit extension and a graphical shell for a 16 bit patch to an 8 bit operating system originally coded for a 4 bit microprocessor, written by a 2 bit company that can't stand 1 bit of competition.”
- A hozzászóláshoz be kell jelentkezni
Úgy sejtem, eddig is az okozta a problémát, hogy a mentések megsérültek, és most találtak egy olyan példányt, amelyet a többitől függetlenül kezeltek.
Pont benne vagyok egy banki projektbe, ahol egyelőre nincs büdzsé enterprise backup megoldást vásárolni - helyette a public cloud beépített lehetőségeire kell fejleszteni - vagyis majd egy scripthalmazt üzemeltetni.
Másik helyen ugyanez, de ott office backend helyett már core banking rendszeren.
- A hozzászóláshoz be kell jelentkezni
helyette a public cloud beépített lehetőségeire kell fejleszteni - vagyis majd egy scripthalmazt üzemeltetni
(Nyilván függ attól, hogy melyik cloud melyik workloadjét kell védeni, de) Én az elmúlt fél évben elég sokat túrtam a három nagy hyperscaler natív backup megoldását, és annyira azért nem rosszak, sőt.
Tény, hogy van az Igaz Út, ahogy ők a backupot menedzselnék, és ha ez valamiért nem jó (legtöbbször viszont jó), akkor marad a scriptelés, ha erre gondoltál, akkor +1.
- A hozzászóláshoz be kell jelentkezni
Csak az Azure-t ismerem, alapvetően kettő probléma van vele: semmilyen garanciát nem vállal a konzisztenciára az Azure, a backup dependál a resource-ra - ugyanazoknak lesz hozzáférése akiknek a resource-re is, resource-al együtt a backup is megy a levesbe.
- A hozzászóláshoz be kell jelentkezni
a backup dependál a resource-ra - ugyanazoknak lesz hozzáférése akiknek a resource-re is,
Itt most pl. a Recovery Services Vaultról beszélünk, ugye? Nekem gyanús, hogy ez nincs így, akkor ott valami félre van konfigolva IAM-ben.
Plusz ha teszel rá locked immutability-t, akkor senki nem tudja kitörölni, akkor sem, ha ki kellene.
resource-al együtt a backup is megy a levesbe.
Ez milyen resource? Megvan, hogy melyik vault típussal melyik resource-ok kompatibilisek, RSV-vel ilyen gond szerintem nem volt.
- A hozzászóláshoz be kell jelentkezni
wal file-t említettek a bejegyzésben, ez alapján vagy postgres, vagy sqlite :D
azért én az előbbire tippelnék, de az egész story fura és nem csak úgy egy picit, hanem lólábak hada villan ki ezekből a bejegyzésekből
// Happy debugging, suckers
#define true (rand() > 10)
- A hozzászóláshoz be kell jelentkezni
Igazad van, efölött elsiklottam. Akkor még is SQL alapú lesz, de továbbra is morbid, amit írnak, ahogy mondod te is, sok helyen kilóg az a lóláb.
“Windows 95/98: 32 bit extension and a graphical shell for a 16 bit patch to an 8 bit operating system originally coded for a 4 bit microprocessor, written by a 2 bit company that can't stand 1 bit of competition.”
- A hozzászóláshoz be kell jelentkezni
Igazából az egész egy vicc kategória. Engem az érdekelne, melyik az a CPU utasítás, amelyik csak és kizárólag a DB mentésnél van használatban, sehol máshol, ott viszont konzisztensen előjön a szar. Vagy egy olyan esetet ami in-memory DB esetén olyan inkonzisztens állapotot hoz össze, ami csak és kizárólag DB mentésnél jön elő és nem csetlik botlik tőle a DB szerver maga is (de igazából bármi más is a szerveren)
// Happy debugging, suckers
#define true (rand() > 10)
- A hozzászóláshoz be kell jelentkezni
Ez az, ezt nem értem én is, meg vagyunk itt vele néhányan. Mert ha a proci szar, akkor az egész rendszer leseggel, lefagy, be sem bootol. Olyat még nem láttam, hogy látszólag jól fut, de a háttérben sérti az adatokat.
Arra tudok inkább gondolni, hogy a procival semmi baj nem volt. Volt egy régebbi proci, a RAM időzítéseket ahhoz igazították, beállították jó alacsonyra, hogy jól fusson, max. teljesítményen, és ez nem volt gond annak a processzornak. Erre procit cseréltek, valami még több magosra, de annak a memvezérlője nem szerette a túl kicsire szabott időzítéseket, vagy a túltolt RAM frekit, és elkezdett a RAM hibázni, na, az már haza tud vágni tárolt adatokat, de akkor meg nem a proci hibás, hanem ők cseszték el a beállításokat.
“Windows 95/98: 32 bit extension and a graphical shell for a 16 bit patch to an 8 bit operating system originally coded for a 4 bit microprocessor, written by a 2 bit company that can't stand 1 bit of competition.”
- A hozzászóláshoz be kell jelentkezni
nincs az a szelektív memóriaprobléma, ami csak és kizárólag a pgdump-ot érinti, a kernel pedig nem panic-ol 2 percenként, vagy döglenek ki sorra egyéb processzek
// Happy debugging, suckers
#define true (rand() > 10)
- A hozzászóláshoz be kell jelentkezni
Nekem teljesen érthető volt. Van egy szerverük, ahol procit cseréltek. Ez a proci hibás volt, és időnként hibázott. Az inkrementális backup innentől kezdve hibás adatokat tartalmazott. Amikor rájöttek hogy itt gond van mert végre hajlandó volt a proci megdögleni, akkor azt gondolták hogy csak proci csere, és megy minden tovább, de nem számítottak arra hogy közben ment vele az alaplap is, ráadásul most nyári szünet van, és gondolom ez az egész egy pár emberes show. Kis ország, kis foci. A korábbi backup megvan, arra valószínűleg pár óra alatt vissza tudnának állni, csak ugye akkor elvesznének a több hónapnyi fórum hozzászólások, cikkek, stb. No, és akkor innentől legyél okos, mert akkor egy hibás incremetalis backupból hogyan tudod kiszedni a még menthető adatokat, és ha tudod, mennyi időt akarsz erre tölteni miközben áll minden, és ha úgy döntesz hogy inkább csak menjünk, akkor a menet közben visszanyert adatokat vissza lehet-e tolni az adatbázisba úgy, hogy az működjön is helyesen egy komplex tábla struktúra mellett.
És ha belegondolunk, az alapproblémát a cloud se oldja meg, mert ott is lehetett volna hibás processzor. Valami olyat tudnék elképzelni hogy egy párhuzamos rendszer minden nap felhúz egy teljes szervert adatbázissal együtt a backupból és utána végrehajt a teljes adatbázisra egy konzisztencia vizsgálatot, azzal esetleg lehetett volna mitigálni a hibát.
- A hozzászóláshoz be kell jelentkezni
A korábbi backup megvan, arra valószínűleg pár óra alatt vissza tudnának állni, csak ugye akkor elvesznének a több hónapnyi fórum hozzászólások, cikkek, stb. No, és akkor innentől legyél okos, mert akkor egy hibás incremetalis backupból hogyan tudod kiszedni a még menthető adatokat, és ha tudod, mennyi időt akarsz erre tölteni miközben áll minden, és ha úgy döntesz hogy inkább csak menjünk, akkor a menet közben visszanyert adatokat vissza lehet-e tolni az adatbázisba úgy, hogy az működjön is helyesen egy komplex tábla struktúra mellett.
"Balatonon voltak, és fontosabb dolguk volt az oldalnál" - szóval ekkora cégben reálisan az egyetlen ember, akinek volt esélye ezt ennyire érteni, az szabin volt, és közölte a főnökkel, hogy a faszom se jön vissza :D
- A hozzászóláshoz be kell jelentkezni
En is dolgoztam olyan cegnel, ahol evekig pusoltam a vezetoseget hogy legyen rendes backup, DRP, es persze egy kis fejlesztesi ido mindezekre, mert tul sok a single point of failure.
Ha epp nyaraltam volna en is mikor bekovetkezik a baj, es szol a foni hogy akkor asap jojjek:
¯\_(ツ)_/¯
- A hozzászóláshoz be kell jelentkezni
Nyilván :)
Bár elvileg azért ha ekkora gebasz van, akkor egyébként vissza is hívhat akár a szabiról. Aztán persze, hogy jössz-e, vagy pereljen be, miután kirúgott, az már nyilván döntés kérdése :)
- A hozzászóláshoz be kell jelentkezni
Erről ez jutott eszembe:
https://i.kek.sh/7n7tpjybhxu.jpg
{kind=link}
I don't run often, but when I do, I run as administrator.
- A hozzászóláshoz be kell jelentkezni
Szerintem kulon VIP hely van fenntartva a pokolban az ilyen feletteseknek.
- A hozzászóláshoz be kell jelentkezni
A tegnapi hosszú face post alapján nincs másik vasuk a db szerver számára. Az én olvasatomban: A meglévőt pofozták vissza futásképes állapotra, de a hardverrel gondok vannak, többszöri nekifutásra kezdte a stabilitás látszatát kelteni a vas. Ideiglenesen mégis azon fog futni, mert nincs más. Backup csak nagy tervezett leállásokkor, karbantartásokkor készül. Amúgy meg a vason magán vannak talán snapshotok. Néha, talán valami fejlesztői teszthez vagy valamihez az adatbázis egy részét átmásolják saját pécére. Az nem tiszta, hogy a snapshotokat kimentették-e máshová rendszeresen. Ha nem, akkro a fájlrendszer vitte magával őket. Ha kimentették, akkor a legutóbbi karbantartás óta, 3 hónappal ezelőttig végig korrupt fájlok voltak maguk a mentések.
Utólag csak azt lehet tudni, hogy mit kellett volna másképp csinálni. Remélem a kritikákból majd az építő jellegűekből tanulnak és alkalmaznak jobb megoldásokat. Talán kapnak olyan helyről is szakmai tanácsokat, amire nem sértődnek meg, hanem alkalmazzák.
- A hozzászóláshoz be kell jelentkezni
Valaki közölünk látott már olyat hogy egy CPU hiba hónapon keresztül észrevétlen egy kiszolgálón, de végig korrumpálja a DB-ben levő adatokat - anélkül hogy ennek bárhol nyoma lenne?
Ennek a rejtélyes hibának egy sor hibaellenőrzésen (legalább a kernel és a DB szerver) végig kellett csúsznia.
- A hozzászóláshoz be kell jelentkezni
Ezen gondolkozom reggel óta. Olyat láttam már hogy stabilan működött a rendszer és minden olvasás hibátlanul ment, viszont random írások korruptak lettek. De ez elég gyorsan kiderült és ez egy memória hiba miatt volt. CPU hibával sem igazán tudom elképzelni azt az esetet hogy heteken keresztül korrupt adatok kerülnek a DBbe anélkül hogy ennek bármi nyoma lenne, semmilyen hibát nem tapasztalnak. Ennek user szinten is problémát kellett volna okoznia.
- A hozzászóláshoz be kell jelentkezni
Nem heteken keresztül, hanem hónapokon keresztül. (állitólag áprilisi az utolsó jó mentés)
Mondjuk a lottó ötöst is elvitték a héten, hasonló lehet erre is az esély...
- A hozzászóláshoz be kell jelentkezni
Van olyan processzorhiba, ami bizonyos magokat érint csak. Tehát van a processzornak olyan erőforrása, ami tökéletesen működik, akár egészen sok, és olyan is, ami bizonytalankodik.
Lehet, hogy nem olyan gyakori, de létezik ez a jelenség, és ez könnyen megbújhat egy ideig.
Az, hogy milyen ellenőrzéseken csúszott át vagy mi volt még a háttérben, az egy másik dolog, de sokan már azt sem hiszik el, hogy CPU-hiba okozhat hasonló problémát, ill. lehet részlegesen rossz, ami azért furcsa sok "szakértőtől" (PH! Facebook üzenetei alatti hozzászólásokra gondolok).
- A hozzászóláshoz be kell jelentkezni
Nem. Olyat láttam, hogy memóriahiba csinált ilyen titokban halmozódó bit-rohadást a tárolt adatokban, de az egy ECC-nélküli desktop gépen volt. Illetve nagyon régen egy távoli galaxisban IDE-nél enyhén hibás szalagkábel tudott még random bithibákat termelni a diszken tárolt adatokban.
Ha feltétlenül tippelni kell, az a sanda gyanúm, hogy valójában ramhiba volt ez, amit az ECC-nek meg kellett volna fognia. Csak az "új processzorral" valamiért az ECC kikapcsolódott és nem vették észre.
Régóta vágyok én, az androidok mezonkincsére már!
- A hozzászóláshoz be kell jelentkezni
...és manapság a CPU-ban van a RAM-vezérlő is egyébként.
- A hozzászóláshoz be kell jelentkezni
Az inkrementális backup innentől kezdve hibás adatokat tartalmazott.
Ez még akár igaz is lehet, bár vannak kétségeim, hogy milyen CPU bug lehetett az, ami április (ez volt, ha jól rémlik az legutolsó "jó" mentés) óta szétveri a backupot, de csak azt.
Meg amúgy na, pont egy apróhirdetéses, meg fórumos oldalon hónapokig csak inkrementális mentés legyen? Hát legalább hetente pörögjön már le egy teljes, nem?
- A hozzászóláshoz be kell jelentkezni
nem volt normális mentési rendszerük. Ennyi. Lehet a procira meg a vasra fogni dolgokat, de alap tétel, hogy ami elromolhat az el is romlik... - erre kell felkészülni.
- A hozzászóláshoz be kell jelentkezni
Most pont azon gondolkozom hogy ezt az egész helyzetet hogyan is lehet megfogni. Van egy proci amely - véletlenszerűen/esetleg terheléstől függően - hibázik. Ezek a hibák belekerülnek az adatbázisba, amely aztán szépen átcsorog a mentésbe. Észreveszed hogy gond van, ezért egy teljesen új gépre megpróbálsz visszaállni. Oké, de addigra már eltelt egy dT idő, ami alatt hibás adat került a mentésbe. Természetesen vissza tudsz állni egy korábbi időpontra, csak akkor meg elvész a köztes adat. Ebben a helyzetben lényegtelen hogy a mentés hol van: azonos gépen, másik gépen, másik kontinensen, hiszen már az elmentett adat is hibás volt.
Oké, tegyük fel, hogy szerencsénk van és nem az a proci lesz hibás amelyik az éles rendszert futtatja hanem ami a backupot. Ott hogyan és valójában mikor is fogjuk észrevenni hogy hiba történt? Amikor csinálunk egy adatbázis visszatöltést, tesztelési célból? Milyen gyakran is futnak az adatbázis visszatöltő és integritás ellenőrző scriptek? 3 havonta? fél évente?
- A hozzászóláshoz be kell jelentkezni
Ne vegyük készpénznek hogy valóban így történt.
- A hozzászóláshoz be kell jelentkezni
Nálunk prod rendszeren MSSQL-lel minden hétvégére be volt ütemezve a backup visszatöltése egy erre a célra dedikált, nem éles szerverre. Voltak hibák amik így derültek ki, bár nem adatkorrupciós jellegűek voltak (pl a Crowdstrike-osok szokás szerint suttyomban terítettek valami elbaltázott frissítést - ez még a nagy botrány előtt volt -, amitől a falcon agent megőrült az összes szerveren, és elkezdte végtelenciklusban végigolvasni a DB összes fájlját. Úgy 30TB-ról beszélünk. Onnan derült ki, hogy a restore job alertelt, hogy 12 óra alatt nem fejeződött be a backup visszatöltése).
Régóta vágyok én, az androidok mezonkincsére már!
- A hozzászóláshoz be kell jelentkezni
Hozzon már valaki egy múltbeli példát egy ilyen cpu meghibásodásra bárhonnan a világból, ami csak egy db adott táblájánál hibázott.
Ez annyira mese, hogy nem igaz.
Saying a programming language is good because it works on all platforms is like saying anal sex is good because it works on all genders....
- A hozzászóláshoz be kell jelentkezni
ugyan már... biztosan volt erre példa, csak nem volt hírértéke, mert nem dőlt össze a világ
2022 - facebook https://blocksandfiles.com/2022/03/18/facebook-investigates-silent-data…
https://engineering.fb.com/2022/03/17/production-engineering/silent-err…
valami hasonló tanulmány
https://engineering.fb.com/2021/02/23/data-infrastructure/silent-data-c…
pentium D procik bugja https://lists.debian.org/debian-devel/2017/06/msg00365.html?utm_source=…
- A hozzászóláshoz be kell jelentkezni
Szerintem ha valaki felcsapja az intel meg az amd cpu errata-kat, abban családtól függően tucatjával vannak az olyan bugok, amikre nincs fix de még workaround sem mindegyikre. Ezek egy része extrém ritka esetben fordul elő éles környezetben. De egyik sem lehetetlen h. megtörténjen. Innentől meg nagy számok törvénye: összeszorzódik a processzor bug előfordulási vsz. az oprendszer bug vsz-el, szorozva a fordítóprogram által berakott bugokkal, végül az sql szerver szoftver bugok vsz-vel.
- A hozzászóláshoz be kell jelentkezni
igen, valsz a fordítóprogramokban szokták kezelni.. meg újabban a mikrokód frissítésekkel - mivel valójában nem direktben futtatják az utasításokat a mai cpu-k, hanem átcserélik saját implementációra.
Az a kellemetlen, amikor nem determinisztikus a hiba. Mint a memóriáknál a hammering és hasonlók. A modern cpu energiagazdákodés és turbó módjai is tudhatnak furákat.
Meg persze minél nagyobb a cache, minél több a memória, annál esélyesebb, hogy valahol hiba legyen futás közben. Akár tűréshatárok miatt, akár kozmikus részecske átütő ereje miatt. Amikor nagyon fontos a hibátlan működés, akkor szoktak párhuzamosan több példányban futtatni és kiértékelni kódot és adatot.
- A hozzászóláshoz be kell jelentkezni
Üdv a SIL4 világában... Két, párhuzamosan megírt szoftver, azonos proci típuson, de két példányon. Vagy másik lehetőség: manapság létező tricore arm magok...
- A hozzászóláshoz be kell jelentkezni
Az első gondolatom az volt, hogy Prohardver - hardver szakértők és ha igaz, hogy Cpu hiba miatt történik ez, akkor pont ők nem tudtak erről, és nem is készültek fel erre.
Azt lehet tudni, ki a lapcsalád informatikai, üzemeltetési vezetője, akinek a felelőssége ez az egész szituáció?
Tudja valaki, hogy mi a lapcsalád magyarázata arra, hogy miért nem nézték meg, hogy ha volt egyáltalán biztonsági mentés, akkor jó-e az a mentés?
Már csak költői kérdés, hogy mikor próbáltak backupból visszaállni teljesen legutoljára? (Soha.)
- A hozzászóláshoz be kell jelentkezni
Abból az 5-9 főből (amiből 4 tulajdonos) szerinted lesz valaki akinek az informatikai/üzemeltetési vezető a poziciója?
- A hozzászóláshoz be kell jelentkezni
Ha tudnám, nem kérdezném. Ezen a parmalinken a másik hasonló Porhardveres témában írtam egy teóriát! :-)
- A hozzászóláshoz be kell jelentkezni
Most mondanám, hogy meglepett... De sajnos nem.
Nagyon sok ilyen nagynak tűnő weboldalt, szolgáltatást láttam már, amiről azt gondolnád, hogy milyen profi, mert kívülről a csilivili web meg html5 látszik. Aztán hogy alatta mi és hogy van kókányolva... Azt inkább nem akarod tudni. Mert ha tudnád, nulla bizalmad lenne felé, és biztos nem használnád.
"Sose a gép a hülye."
- A hozzászóláshoz be kell jelentkezni
Én (részben) ezért nem megyek bankhoz dolgozni :)
- A hozzászóláshoz be kell jelentkezni
Jepp, hallottam már néhány szuper történetet. :)
"Sose a gép a hülye."
- A hozzászóláshoz be kell jelentkezni
Én megengedőbb vagyok, nem tartok olyan banknál pénzt, amit már láttam belülről :D
- A hozzászóláshoz be kell jelentkezni
Két dolgot tanultam eddig különféle cégeknél:
- banki biztonság: annyira elavult, hogy már nem támadják vagy nem tudják, hogy kell támadni,
- katonai minőség: a legolcsóbb szar, amit egyszer lehet használni, utána széteshet.
- A hozzászóláshoz be kell jelentkezni
Ha szereted a felvágottat/virslit/szafaládét - ne menj el megnézni, hogyan készül... :-) De a régi nóta is idézhető:
Piskóta jó eledel,
sohasem feledem el,
mert láttam a pék mit csinál,
víz helyett bele...
Piskóta jó eledel,
sohasem...
satöbbi :-D
- A hozzászóláshoz be kell jelentkezni
Ezt megerősítem, volt régebben egy szekszárdi, tolnahúsos húsiparban dolgozó ismerősöm, mondta, hogy ha látnánk, hogy a virsli, szafaládé, párizsi hogyan készül, mit tesznek bele, az életben nem ennénk többet belőle. Ugyanezt mondta a szegedi pick-es ismerős is. Pedig ez még a 90-es években volt, mikor még magasabb színvonal volt minden terméknél, és nem voltak rommá olcsósítva, meg felszójázva.
“Windows 95/98: 32 bit extension and a graphical shell for a 16 bit patch to an 8 bit operating system originally coded for a 4 bit microprocessor, written by a 2 bit company that can't stand 1 bit of competition.”
- A hozzászóláshoz be kell jelentkezni
Sokakat nem érdekel ez, aztán csodálkoznak, h milyen betegségeik vannak. Részemről egyre nagyobb arányban veszünk bio kaját, illetve amit magunknak termelünk, az nyilván bio. Meg hát nyilván nem eszünk szemetet.
- A hozzászóláshoz be kell jelentkezni
attól, hogy bio, még lehet ugyanúgy nyesedékből meg mechanikai úton lefejtett húsból készül, az két külön dolog.
- A hozzászóláshoz be kell jelentkezni
Magával az alapanyaggal, ha az jó forrásból jön, nincs baj. Maximum van benne kollagén. Az meg, h egyesek gyomra nem bírja, h bőrke, meg tőgyhús, hát istenem. Régen, míg nem volt bontott csirke, az egész fel volt használva, és az a normális. Az emberi szervezet úgy fejlődött ki, h kb mindent is megevett. Belsőségekben is sok hasznos tápanyag van, nem csak a melle húsa a fontos.
- A hozzászóláshoz be kell jelentkezni
Nézz azért utána, hogy milyen szemetet használ fel az élelmiszeripar manapság hús helyett:
tldr: leginkább csontszilánkokat etetnek veled pépesítve gerincfolyadékkal
kommenteket között: METRO aruház HYZA fasírt: összetevők 99% MSM 1% só. Well done!
- A hozzászóláshoz be kell jelentkezni
A kedvencem a "porított csirkecsőr". :(
A kürtőskalács egy nagy lyuk, tésztával faszán körbetekerve.
- A hozzászóláshoz be kell jelentkezni
"rossz hús nincs, csak rossz hőkezelés" :)))
- A hozzászóláshoz be kell jelentkezni
Hát a 18 éves kutyám orra megmondja melyiket hajlandó megenni.
- A hozzászóláshoz be kell jelentkezni
És ha még elmesélném, hogy egyik távoli ismerősöm nappal a Jó**** Temetkezésnél dolgozott, éjjel meg a **** pékségnél dagasztotta a kenyeret azzal a kezével, amivel nappal hullákat mosott :D
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Semmelweis lájkolja ezt.
- A hozzászóláshoz be kell jelentkezni
Megmosta a kezét munka előtt. Mármint a lisztet lemosta :D
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Cím frissítve, a "tegnap óta" immár félrevezető volt
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
ma lesz a holnap tegnapja
https://www.youtube.com/watch?v=bGKrYri1tpw
- A hozzászóláshoz be kell jelentkezni
Update (on my side :P)
Megneztem ezt az FB posztot amit kiraktak a landing page-ukre hogy hol tartanak:
https://www.facebook.com/PROHARDVER/posts/pfbid02acTU3VVsedDjUnE9n2bMjG…
Ez a poszt gyerekek egyszeruen aranybanya :D
Aztmondja:
"- nem gondoljuk, hogy nevetségesek volnánk, azt sokkal inkább, hogy a mai internet toxikussága egészen biztosan nem tartozik az erényei közé."
A posztban a kovetkezoket lehet megtalalni:
- 1 db adatbazis szerveruk van (de az 64 enterprise magos proci, nagyon meno, wow :)))))
- read replikarol azt se tudjak mi az, perconat meg se emlitsuk
- az adatbazis mentesek magan a db szerveren voltak tarolva
- offline backup egyaltalan nincs
- disaster recovery nincs
- backup validation nincs
- valamilyen furcsa okbol nem kepesek kivenni a diszkeket es attenni egy masik, nem random rebootolgato vasba
Gyakorlatilag egy apr. 30-i mukodo db mentesuk van, az is csak kurva nagy mazlibol, mert egy nagyobb uzleti valtoztatas miatt lehuzta valaki magahoz a sajat gepere a mentest es azota se torolte le.
Rossz hirem van, de nevetsegesek vagytok :D
Egy ilyen setup konkretan mar 20 eve is kurva ciki volt meg egy garazscegnel is.
2025-ben pedig, ahol aws cli-vel 1 parancs felkuldeni glacier S3-ba a mentest egyszeruen vedhetetlen.
Update of update, 3 oraval ezelotti report:
Ahogy az varhato volt az 5 napos kokanyharc semmi eredmenyt nem hozott, a teljesen fuggetlen okokbol valaki gepere letoltott (es azota veletlenul nem letorolt) apr. 30-i mentesbol allnak vissza:
https://www.facebook.com/PROHARDVER/posts/pfbid0zhapbv13PZVttjeHzVXowYL…
- A hozzászóláshoz be kell jelentkezni
Szánalmas úgy, ahogy van.
Ha tartós rendszert építesz és okos csapatot nevelsz, akkor száz kiadásban sem érheti baj; ha csak a gépekre hagyatkozol, akkor egyszer jól jársz, máskor rosszul; de ha sem a rendszer nem bírja a terhet, sem a csapat nem tanul a hibákból, akkor minden egyes kiadás kockázat.
- A hozzászóláshoz be kell jelentkezni
eredeti Toy Story vibe!:)
Saying a programming language is good because it works on all platforms is like saying anal sex is good because it works on all genders....
- A hozzászóláshoz be kell jelentkezni
Bár a Toy Story-t ne tudták volna helyreállítani, nem a PH-t :D
Így leírva még nekem is ciki :( pedig azért volt pár szörnyszülött az én kezem alatt is :D
Színes vászon, színes vászon, fúj!
Kérem a Fiátot..
- A hozzászóláshoz be kell jelentkezni
Amúgy a toy story 2-ről szólt az anekdota, nem az 1-nél volt ez a fuckup.
- A hozzászóláshoz be kell jelentkezni
Ja, nevetségesek, de még ezen túlmenően annyira lejáratták most magukat a szememben, hogy már rá sem fogok nézni az oldalra. Van egy olyan komoly megérzésem, hogy nem fognak a régi formában újraindulni, hiába állítják ők azt, ilyen április mentéses terelésekkel. Már hétfőre ígérték a startot, semmi nem lett belőle, majd most 29-én már valami 8 órája a legutolsó post-juk szerint már csak 2 óra van hátra. Majd éjszaka is csak 2 óra lesz hátra. Hagyjuk, annyira komolytalan, hogy tényleg olyan akármit írni már róluk, mintha a földön fekvőt, vagy egy hullát rugdosnánk. El kell engedni, nem lesz itt már semmilyen újraindulás. Ha akármit is helyre tudtak volna állítani, akár csak részlegesen, már rég újraindultak volna. Nem szabad a tereléseiknek felülni. Szerintem már csak magukat meg a hirdetőket hitegetik, majd belátják egy ponton túl, hogy értelmetlen küzdeni az elkerülhetetlen ellen.
“Windows 95/98: 32 bit extension and a graphical shell for a 16 bit patch to an 8 bit operating system originally coded for a 4 bit microprocessor, written by a 2 bit company that can't stand 1 bit of competition.”
- A hozzászóláshoz be kell jelentkezni
HWaprót és a fórumokat hozzák vissza, a hírportál része felőlem mehet a levesbe az "új" videós vonulattal együtt.
- A hozzászóláshoz be kell jelentkezni
HWapróban mi volt a nóvum? Volt valami garanciarendszer arra ha a vevő nem azt kapja amiért fizetett vagy semmit nem kap?
- A hozzászóláshoz be kell jelentkezni
A hardverapró egyik fő előnye, hogy az átlagos FB Marketplace user nem hallott a létezéséről, ezért relatív nyugalomban lehetett adni-venni a cuccokat.
- A hozzászóláshoz be kell jelentkezni
Garancia nem, de jól működő értékelési rendszer volt benne, ami adott némi biztonságot. Úgy alapvetően a hirdetési rendszer szerintem átgondolt, könnyen használható volt. Ami nem tetszett rajta az a rengeteg kereskedelmi hirdetés :(
- A hozzászóláshoz be kell jelentkezni
Nem, a magyar piacterek semmilyen felelősséget nem vállalnak, hanem olyan életszerűtlen szabályzatokat alkotnak helyette, amiben minden felelősséget a vevőre hárítnak.
Nem véletlen, hogy inkább ebayről, aliexpressről és hasonló helyrőn rendelnek inkább. Ettől persze még működnek a magyar oldalak is, mert kis értéknél, vagy mémi óvatossággal csökkenthető a konckázat. De alapvetően, mivel a fizetési rendszer a közvetítőn kívül történik, így ha a pénz odavan, akkor oda van.
- A hozzászóláshoz be kell jelentkezni
Nagyon szerettem. Elköltöttem vagy 2M HUF-ot ott. Egyetlen egyszer vettem egy kattogó HDD-t. Felhívtam a tagot, esküdött rá hogy működött, fél órán belül hozta vissza az árát, el se vitte a szart. Ez is rendben volt, biztos nem átbaszni akart. Nagyon szerettem, aztán kitaláltak valami azonosítsam magam baromságot a közben megszűnt mail címemről.
- A hozzászóláshoz be kell jelentkezni
Relatíve szakmai bolhapiac. Nekem aki szeret régebbi gépeket életben tartani és javítani egy igazi kincsesbánya amiben ráadásul tök precízen hirdetnek. Pl ha 1600as lpddr3 notebook memória kell kitben hwaprón 3 perc alatt találok, marketplacen sok szerencsét ahhoz hogy felfogják egyáltalán mit keresel.
Ezen felül van egy egyszerű de jól működő visszajelzési rendszer, könnyen ki lehet szűrni a csalókat.
Kora középsulis korom óta használom rendszeresen, most hogy visszajött megint megyek turkálni :D W10 EOL után innen tervezem felújítani a családi gépparkot ha minden jól megy akkor kb gombokért.
- A hozzászóláshoz be kell jelentkezni
Nagyon rá vagy fixálódva ezekre az "elkerülhetetlen" képzeteidre, úgy tűnik, nem csak a kényszeres hardverújravásárlásban és szoftverfrissítgetésben.
Lehet, hogy túl sok Végső Állomást néztél. :P
- A hozzászóláshoz be kell jelentkezni
Mert szerinted mit fog érni az oldal, ha 0-val indulnak újra? Onnantól egy kis oldal lesznek. Most abban a fázisban vannak, mikor ámítják magukat, meg a nagyközönséget, hogy ők helyreállítanak. Nem, nem állítanak helyre, amit eddig nem tudtak, azt már nem fogják helyreállítani. Ez kicsit olyan, mint mikor a nincstelenek azzal hitegetik magukat, hogy ők majd nyernek a lottón, meg bitcoinból gazdagodnak meg.
Természetesen most se megy az oldal, majd beígérik holnapra, és akkor se fog menni, minden órában holnap is még 2 órányira lesznek az indulástól. Ha van magadhoz való eszed, gyorsan belátod, hogy végük van, csak kérdés mikor ismerik be.
Tudom, hogy ezzel az elkerülhetetlenséggel már megsebeztelek lelkileg, mikor írtam neked, hogy ti windowsosok is ilyenek vagytok, állandóan kihúztok, halogattok, hogy na még ennyi hónap XP-n, amannyi év POSReady, de majd a Win7, meg a Win7 ESU, meg a WIN10 LTSC BVSC pálya, még egy kis fogösszeszorítás, mert a Win12 jobb lesz, nem lesz. A semmiben reménykedtek, a semmiért húzzátok az időt.
“Windows 95/98: 32 bit extension and a graphical shell for a 16 bit patch to an 8 bit operating system originally coded for a 4 bit microprocessor, written by a 2 bit company that can't stand 1 bit of competition.”
- A hozzászóláshoz be kell jelentkezni
Mert szerinted mit fog érni az oldal, ha 0-val indulnak újra?
https://a.te.ervelesi.hibad.hu/allito-kerdes
Nem 0-ról fognak újraindulni.
Nem, nem állítanak helyre, amit eddig nem tudtak, azt már nem fogják helyreállítani.
De igen, helyre tudják. Az, hogy te a netbookjaidon mit taknyolsz össze a Linux CLI-dből, teljesen irreleváns.
Természetesen most se megy az oldal, majd beígérik holnapra, és akkor se fog menni, minden órában holnap is még 2 órányira lesznek az indulástól. Ha van magadhoz való eszed, gyorsan belátod, hogy végük van, csak kérdés mikor ismerik be.
Mondom, túl sok Végső Állomást néztél.
Tudom, hogy ezzel az elkerülhetetlenséggel már megsebeztelek lelkileg
Nem sebeztél meg lelkileg, ellenkezőleg. Neked van valamiféle sérülésed ezzel az elkerülhetetlenséggel kapcsolatban. Ezért erőlteted bele mindenbe is. A frissítésbuziskodás csak egy példa volt.
Amellett, hogy az elkerülhetetlenség-kényszerképzetes jóslataid nem jöttek be sem az XP-nél, sem a többi legacy OS-nél.
Túltolod.
LTSC BVSC pálya
Az LTSB/LTSC pálya jó. A feature ág instabil szar. Pont, ahogy a Linuxodnál is és minden szoftvernél. Ami rendszer 10 évig csak bugfixeket kap, az egy egyre stabilabb rendszer. Ami rendszer folyamatosan feature frissítéseket kap, az egy kevésbé stabil rendszer.
kis fogösszeszorítás
Értem, hogy neked össze kell szorítanod a fogaid, ha leültetnek egy Windows elé. Nekünk, Windows-felhasználóknak nem kell ilyet tennünk, mert tudatos felhasználóként tisztában vagyunk a rendszerünk erősségeivel, gyengeségeivel és ennek megfelelően használjuk.
A témára visszatérve, abban egyetértünk, hogy az az üres, konkrétumokat nélkülöző hitegetés inkorrekt a felhasználókkal szemben, amellett, hogy gáz és szakmaiatlan.
- A hozzászóláshoz be kell jelentkezni
Helyreálltak, július elejei privát üzeneteim is megvannak.
Jól megmondtad, de legalább napokig vergődtél, hogy végük.
- A hozzászóláshoz be kell jelentkezni
Szerintem, amikor a hozzászólását írta, vagy röviddel azután, már ment az oldal...
Nekem egy közelmúltbeli privát üzenetem veszett el, de elgondolkoztam rajta, hogy hallucináltam-e, hogy válaszoltam rá. :)
Fórum-hozzászólásokat nem nézegettem, de adott topicban max. néhány veszhetett el, mert - legalábbis hozzászólások száma alapján - nem került "korábbi" oldalra a szál, amt néztem.
- A hozzászóláshoz be kell jelentkezni
Jó, tévedtem, legyetek boldogak. Mint írtam, én nem kívánom az oldal vesztét, de nem én vergődtem, amit levágtak, azt már kínlódás volt nézni. Igen, észrevettem, hogy most már elindultak. Mindegy egyébként, én kb. évek óta nem használom az oldalt, úgy értve, hogy nem csak a fórumot nem, a cikkeiket, tesztjeiket se olvasom. Nagyon kínos volt már ez, amit napokig levágtak. Főleg a vége felé, mindjárt, még 2 óra, mindjárt, már csak cikkeket adunk hozzá, még két óra, még hétfő, még kedd. Végül szerdába csúsztunk majdnem át pár perc híján, mire elindult. Az én szememben megerősödött, hogy komolytalan banda, felesleges is az oldalt használni, jól tettem, hogy évekkel ezelőtt otthagytam őket.
Amit továbbra sem értek, hogy mi tartott ezen ennyi időt. Ha tényleg volt mentésük, akkor az nem tarthat 7 napig. Mindegy, nem is idegesítem magam vele, mert a pentium 2-es, közgazdasági matekos-balatonos, meg a megdöglő CPU, ami csak az adatbázist rongálta meg szelektíven szövegüktől, még mindig herótom van. Lehet nálam is sérült a proci, és csak szelektíven azt okozza, hogy rosszabbul fogadom a hülye szövegeket.
Adalék: ráadásul elég nehéz helyreállásnak nevezni, nálam FF-ban nem megy rendesen az oldal, nem reagál, ha linkekre kattintok, csak ha jobb egérgombbal nyitom meg új ablakban. Valami nem stimmel még. Nem tudom, hogy ez csak FF-bug, de kötve hiszem, mert más oldalakon jó. Tesztképp töröltem a sütiket, engedélyeztem a követést, kikapcsoltam a uBlock Origint, semmi nem javít rajta. Tippre a bezárhatatlan YouTube-csatornás popupjuk okozza, ami elveszi a fókuszt az oldaltól.
“Windows 95/98: 32 bit extension and a graphical shell for a 16 bit patch to an 8 bit operating system originally coded for a 4 bit microprocessor, written by a 2 bit company that can't stand 1 bit of competition.”
- A hozzászóláshoz be kell jelentkezni
Szerintem világosan el lett mondva hogy mi tartott ennyi ideig. Először azt gondolták hogy meg tudják gyorsan oldani, rájöttek hogy nem. Utána rájöttek hogy egy csomó mentésük is rossz. Utána rájöttek hogy van egy régi mentésük, és azzal cseszték el az időt hogy kitalálják hogy akkor a régi mentéshez hogyan lehet hozzáapplikálni a köztes mentésekből kiszedhető adatokat úgy hogy ne legyen nagyobb baj mint egyébként. Aztán még azt is ki kellett találni hogy egyáltalán érdemes-e a meglévő HW-re visszaállni vagy kuka az egész és béreljenek valahol szervert, virtuális gépet, toronyórát lánccal. Igen, ezt nem most kellene kitalálni, de mivel nem foglalkoztak ezzel korábban, igy most kellett, ilyen a popszakma.
És igen, még lehet egy hétig döcögni fog a rendszerük, nagy ügy, majd megoldják. Nem a vizet vagy az áramot zárták el, hanem most egy-két hétig nem tudnak csencselni az emberek, meg fórumozni. Nyári szünet van, majd elmennek a balcsira.
- A hozzászóláshoz be kell jelentkezni
Mindenképpen figyelemreméltó, hogy többnyire azok szakértettek, és mondták el az üzemeltetőket mindennek, akik bevallásuk szerint nem használták, vagy nem rendszeresen. Bár valóban érdekes lehet a pontos ok, de elsősorban azért, hogy tudjuk, mit kell elkerülni. Mivel itt minden hozzáértő már sok mindent leírt, hogy mit hogyan kéne, az se érdekes annyira, itt a tudás, csak meríteni kell belőle.
Én inkább csak örömmel látom, hogy megy az oldal, és bízom benne, hogy az üzemeltetők tanultak a hibákból.
- A hozzászóláshoz be kell jelentkezni
megyen már ; fórumban pár hozzáröffenésem nincs meg, legalább azok alapján nem vádolhatnak meg ukránpártisággal. És hát ősi tudás, hogy a word elszáll, a papír megmarad.
HUP te Zsiga !
- A hozzászóláshoz be kell jelentkezni
A cloud-buziskodást kihagyhattad volna, egyébként azonkívül egyetértek.
- A hozzászóláshoz be kell jelentkezni
Na indulgatnak, bár még döcög, sok a Gateway Timeout.
- A hozzászóláshoz be kell jelentkezni
Félelmetes ez a HUP.
Alapvetően egy informatika közmű három fő pilléren áll:
1. Pénz, azaz anyagi oldal
2. Menedzsment, azaz vezetőség
3. Informatika, azaz üzemeltetők és fejlesztők és miegymás..
Itt, ebben a projektben egy vagy több pillér nem volt a helyzet magaslatán.
Ennyi, minden más szófosás.. a baj megtörtént, okoskodni meg csak tények ismeretében lehet és érdemes.
A kérdés az, és én inkább erre lennék kíváncsi később, hogy milyen tanulság lesz levonva a részükről és mit tesznek a közeljövőben.
- A hozzászóláshoz be kell jelentkezni
Egyetértek.
A szófosásunk pusztán a szakmai kíváncsiságunkból ered. Mivel a közölt dolgok nem kicsit büdösek mindenki számára.
Lehet hogy elég lett volna annyit közölni, hogy elkúrtuk. Nem kicsit, nagyon.
- A hozzászóláshoz be kell jelentkezni
Na erre érdemes lenne fogadásokat kötni ... :P
zászló, zászló, szív
- A hozzászóláshoz be kell jelentkezni
Minden normális vállalkozás ezen a három pilléren áll.
- A hozzászóláshoz be kell jelentkezni
Az eddig napvilágott látott infók alapján máig mindenkiben (akit érdekelt persze) kialakulhatott egy kép hogy kb. mi is történhetett és mit csináltak. Eszembe jutott egy kérdés erről, hátha tanulok ma is valamit: A nyilatkozatok alapján a mentés, amiből visszaálltak egy rendszeres backupon kívüli mentés, amit valaki valamiért megtartott magánál is. Más helyeken meg több terrabájt adatról beszélnek. Ezt próbálom összerakni. Most akkor van egy több terrás db + fájlrendszer dump (mondjuk legyen pl. 2 TB), amit valaki csak rádobott egy pendrive-ra mert ment a busza és otthon még akart rajta dolgozni? Vagy vettek új backup disket a régit meg kisorsolták a kollégák között és aki megnyerte nem foglalkozott még vele, csak felrakta a polcra hogy majd jó lesz a NAS-ba ha ráér? Szegényes fantáziám és tapasztalataim miatt nem tudok olyan esetet valahogy kitalálni, ami ne sántítana, erre lenék kíváncsi, hogy mi történhetett, mi lehet valószínű? Nem MB meg GB szintű adatok elvileg, én a pendrive-ra feldobást - rohanást elvetném. Arról nem is beszélve, hogy ha csak fejlesztés miatt kellett akkor miért nem volt elég egy töredéke az adatoknak, miért nem valami mockolt, kényes adatok nélküli verziót vitt haza stb. Szerintem átlag helyeken nem lehet az egész céges mindent csak úgy hazavinni, lemásolgatni, vagy nem tudom. Egyáltalán minek hazavinni 2025-ben, vpn-en keresztül elérhette volna a dev adatbázist, ha volt olyan. Már ha ez történt persze. Mit gondoltok erről?
- A hozzászóláshoz be kell jelentkezni
Azt h. az 5-9 fős IT cég máshogy működik, mint a mikroszoft vagy a morganstanley.
- A hozzászóláshoz be kell jelentkezni
Ezt nem vitatom, csak fura nekem ez a nyoma veszett az elefántnak, aztán előkerült a Tibi uzsidobozából - sztori. Kis cégeknél, ahol ezen az egy szem adathalmazon múlik a működés, pont nagyobb elővigyázatosságot feltételezek mint egy multinál, ahol a backup policy-k miatt úgyis mindegy.
- A hozzászóláshoz be kell jelentkezni
Nem létszámfüggő, nálam itthon is van DR-képes mentés. Mindegy hányan vagyunk.
Nem annyira fancy mint mondjuk mint egy bankban, kb 1 napos RPO és 1 hetes RTO.
Attól függ hol szocializálódtál. Nem várható el hogy igény legyen arra amit még sose láttál.
zászló, zászló, szív
- A hozzászóláshoz be kell jelentkezni
Ekkora hozzánemértést egy egyszemélyes cégnek sem szabadna megengednie magának.
Early alfa állapotban van a jelenlegi projektem, de automazitált backup and restore már műkodik, és jön az alarm, ha esetleg nem futott volna le a backup ez éjjel. Szabadságom után az első dolgom az automatikus backup validation implementálása lesz. Magamat egy olyan közepes IT jómunkásembernek tartom, de ez tényleg alap.
Ha tartós rendszert építesz és okos csapatot nevelsz, akkor száz kiadásban sem érheti baj; ha csak a gépekre hagyatkozol, akkor egyszer jól jársz, máskor rosszul; de ha sem a rendszer nem bírja a terhet, sem a csapat nem tanul a hibákból, akkor minden egyes kiadás kockázat.
- A hozzászóláshoz be kell jelentkezni
Én pl. sokszor csináltam olyat, hogy egy már régi (vagy kicsi) hdd-t kicseréltem egy újra, a régit pedig eltettem a páncélba, mint egy tökéletes backup.
Akár még ez is történhetett náluk.
- A hozzászóláshoz be kell jelentkezni
Az egy darab snapshot, nem backup megoldás. A backup az rendszeres és automatikus.
zászló, zászló, szív
- A hozzászóláshoz be kell jelentkezni
Köszi, megfogtad a lényeget :)
- A hozzászóláshoz be kell jelentkezni
Szerintem:
- volt valami rendszeres mentésük ugyanarra a gépre
- az arculatváltás előtt a mentést biztos-ami-biztos kirakták egy külső drive-ra is (ami szerencséjükre megmaradt)
Aztán megkotlott a rendszer.
- megpróbálták helyben megmenteni amit lehet
- még azt is el tudom képzelni hogy az eredő pánikban beletöröltek olyanba is amibe nem kellett volna
- realizálták hogy konzisztensen a táblák/adatok egy részét csak a külső backupból tudják visszahozni
- azt visszarakták
- melléfaragták (kézzel, ez tartott kva sokáig és ez az igazi művészet stressz alatt) amit a helyi mentések romjaiból mellé tudtak fakasztani
- melléfaragták ami esetleg a megkotlott rendszerből még adatbázis/tábla szinten menthető volt
Ezzel indultak.
Most meg még bőven folyik a reindex meg a pucolás, azért lassú.
zászló, zászló, szív
- A hozzászóláshoz be kell jelentkezni
meg most tuti az is belépet és nyomkodja, aki amúgy havonta egyszer teszi.
- A hozzászóláshoz be kell jelentkezni
Ennek némileg ellentmond, hogy van olyan fórum, amelyen jó néhány olyan post is megvan, ami közvetlenül a leállás előtt keletkezett, tehát volt valami inkrementális mentés is, ha nem is teljeskörű..
- A hozzászóláshoz be kell jelentkezni
Nem mond ellent:
"
- melléfaragták ami esetleg a megkotlott rendszerből még adatbázis/tábla szinten menthető volt
"
Ott voltak egy féldöglött postgres-sel, lefuttatgatták a pg_dumpot vagy a select (*) ot azon amin még lehetett.
Így aztán maradhattak akár utolsó napi fórumbejegyzések is.
zászló, zászló, szív
- A hozzászóláshoz be kell jelentkezni
olyannyira, hogy az áprilisi teljes backuphoz képest jelent meg "új" kommentszámként a pluszban rátöltött adat. És az azóta nyitot topicoc nem lettek visszatöltve, mert valsz a topicoc nevei/adatai egy olyan táblában voltak, amit nem sikerült kiszedni a töredezett adatokból.
- A hozzászóláshoz be kell jelentkezni
Terra - Föld. Tera - 10 a sokadikon. https://hup.hu/node/27358
- A hozzászóláshoz be kell jelentkezni
ha 1 terabájt adatot beszántanak, akkor egy terrabájt lesz belőle? :D
- A hozzászóláshoz be kell jelentkezni
Ezt lopom :-D
- A hozzászóláshoz be kell jelentkezni
Teljesen igaz, elszabtam.
(mondjuk amit linkeltél 2006-os, azóta már lehet más a tudomány állása :P )
- A hozzászóláshoz be kell jelentkezni
Persze azért a haladásbuzi elavult™ kártyát fel kellett mutatnod, hogy az egód visszaszúrhasson, miközben pontosan tudod, hogy nem más a tudomány™ állása™.
- A hozzászóláshoz be kell jelentkezni
Igen, tudom hogy nem változott.
Szerintem lehet venni olyan egérpadot, amin a legtöbbet használt smiley-k a jelentésükkel rajta vannak, így a zárójeles mondatom végén lévőt is könnyedén beazonosíthattad volna. Elgondolkodnék egy ilyen beszerzésén, talán nem nyugtalankodnál™ ennyit. Csak egy szívkoszorú-erünk van.
- A hozzászóláshoz be kell jelentkezni
Gigggabyte :))
- A hozzászóláshoz be kell jelentkezni
A hüttőbe, meg a netten, stb........, :-)
- A hozzászóláshoz be kell jelentkezni
1 terasz = 1024 gigasz
Régóta vágyok én, az androidok mezonkincsére már!
- A hozzászóláshoz be kell jelentkezni