- A hozzászóláshoz be kell jelentkezni
- 1495 megtekintés
Hozzászólások
Egy virtualizalt kornyezetben hogyan mukodik a hypervisor az ilyen asymmetrikus processzorokkal? Hogy talalja ki, hogy a VM-ek vCPU-it P- vagy E-core-ra utemezze?
- A hozzászóláshoz be kell jelentkezni
Én meg úgy értettem, ebben csak P magok vannak és van ennek E magos változata is.
- A hozzászóláshoz be kell jelentkezni
Ja ok, akkor nem keverik egy tokban.
Mert ugye ezt elkezdtek mar a desktop vonalon, ahol kb. tobb problemat okozott, mint amennyit megoldott.
- A hozzászóláshoz be kell jelentkezni
Attól, hogy ezekben a procikban nem keverik, attól még másik modellekben megteszik. A kernel oldaláról az ütemező fel van erre készítve, a virtualizációs szoftvereknél passz, ott még nem láttam erre opciót, de lehet csak nem jó helyen néztem.
“The world runs on Excel spreadsheets.” (Dylan Beattie)
- A hozzászóláshoz be kell jelentkezni
Csak ez egy olyan problema, amire nem igazan van megoldas.
Egy OS-en belul talan lehet a processzeket megjelolni, majd a scheduler aszerint futtatja. De egy VM-be nem lat bele a hypervisor, fogalma sincs, hogy egy 8 vCPUs VM eseten mely vCPU-k fognak jobban porogni. Raadasul a guest VM kerneljenek is tisztaban kellene lennie arrol, hogy hany P es E core-ral gazdalkodjon, ami nem konstans, mert a hypervisor atvarialhatja.
Mindenesetre ha valtani kell P es E core kozott, akkor nem csak context switch van, hanem az L1+L2 cache tartalma is elveszik, ami fajo lehet performance szempontbol.
- A hozzászóláshoz be kell jelentkezni
Erre (hagyományosan) a "NUMA tuning" és a "VCPU pinning" a megoldás. A VMM / management layer szintjén a VM memóriáját és CPU-it olyan fizikai NUMA node-okhoz és fizikai magokhoz kötjük, amelyek közel vannak egymáshoz, valamint a guest kernel számára ezt a memória és CPU "rész-hierarchiát", beleértve a CPU cache hierarchiát is, leírjuk (SRAT ACPI táblával, emulált CPUID utasítással stb). Tehát a VMM-nek a kezdeti leképezés után nem kell okosnak lennie; a guest kernel számára egy a fizikai hierarchiát pontosan tükröző virtuális rész-hierarchiát kell pontosan leírni, és onanntól a guest kernel ütemezőjének kell okosnak lennie.
- A hozzászóláshoz be kell jelentkezni
De ha nem extremen sebesseg kritikus esetrol van szo, akkor nem CPU pinnelunk, sot CPU overprovisioning is szokas.
- A hozzászóláshoz be kell jelentkezni
pl. k8s/docker -ben siman lehet(ne) olyat, hogy az E core = 0.25cpu, es amikor jonnek az ilyen cpu req=0.1 meg hasonlo container-ek, azokat siman ra lehet dobni ezekre. Logikus lepes, nem tudom, mukodik-e igy a valosagban, de nem latom, miert ne mukodne.
- A hozzászóláshoz be kell jelentkezni
Felteve ha a limit is 0.1 cpu. A problema a hullamzo workloaddal van. Ha egy process/kontener E core-on fut es hirtelen tekerni szeretne, akkor beleutkozik az E core korlataiba. Ha a scheduler atrakja egy ido utan P core-ra, akkor meg lehet hogy idle-be megy es pazarolja a P core idejet, mas szorul E core-ra. Szoval ez mindenhogy szivas.
Desktop vonalon volt aki letiltotta BIOSban az E core-okat, mert ugy jobb overall performance-ot ert el.
- A hozzászóláshoz be kell jelentkezni
Nem biztos, hogy hullámzik a workload. Ha van mondjuk egy sidecar container, annak a terhelése simán lehet, hogy nullaközeli korrelációval viszonyul a valós terheléshez. Vagy mondjuk egy CronJob, ami minden órában fut, annak lehet, hogy tökmindegy, hogy 5 vagy 10 percig tart, mire végez.
- A hozzászóláshoz be kell jelentkezni
Es mindehhez az kell, hogy vki labelekkel/annotationokkal lasson el tobb szaz/ezer containert a Podokon belul (hiszen honnan tudna hogy mi mennyit fog/szeretne futni a jovoben), hogy a custom schedulert segitse, hogy custom cgroupokban futtassa a containereket. Nagyszeru!
- A hozzászóláshoz be kell jelentkezni
vki labelekkel/annotationokkal lasson el tobb szaz/ezer containert
Erre talán ki lehetne találni valami automatizmust 🤔
a custom schedulert segitse, hogy custom cgroupokban futtassa a containereket
Azt gondolom, hogy ha erre elkezd tömeges igény lenni, akkor lesz rá kevésbé custom megoldás is
- A hozzászóláshoz be kell jelentkezni
Felteve ha a limit is 0.1 cpu. A problema a hullamzo workloaddal van.
Nem mindehova kell nagy cpu. Es azert az E se olyan gyenge am; ezert irtam 0.25-ot.
Pl. init container-nek, ami kvazi egy wget + tedd ide/tedd oda, teljesen jo az E. De prometheus-nak is, aztan ott a monitoring, istio, es meg sorolhatnam, ahova igazabol tok felesleges egy P core, mert csak byte-shoveling -et csinal, es nem cpu-limitalt igazabol soha.
Amugy meg igen, be kell allitani a req/limit -et normalisan, es akkor a k8s/docker szepen tudja hasznalni oket, semmi gond.
Desktop vonalon volt aki letiltotta BIOSban az E core-okat, mert ugy jobb overall performance-ot ert el.
Alapvetoen cirka 20 eve vannak multi-core cpu-k minden masinaban. Mar min. 5 eve vannak E core-ok is. Azert elvarom minden fejlesztotol, hogy ha ki akarja tekerni a cpu-t, akkor keszitse fel a szoftveret ezekre. Vagy keszuljon fel ra, hogy inkompetensnek lesz nevezve.
- A hozzászóláshoz be kell jelentkezni
be kell allitani a req/limit -et normalisan, es akkor a k8s/docker szepen tudja hasznalni oket, semmi gond
Dehogynem gond. Jelenleg a K8s eseteben a resource requestet/limitet cpu-ban merik, nem GHz-ben. Tehat ha van egy Pod aminek fixen egy core-t szeretnenk garantalni, akkor requestre es limitre beallitunk 1-et. Es akkor a scheduler random P vagy E core-ra utemezi. Tehat a szerencsen fog mulni, hogy teljesit majd az az app. Nem determinisztikus.
Most hirtelen nem tudom, hogy van-e egyaltalan barmifele megoldas arra, hogy force-oljuk, hogy az a Pod csakis P core-on futhasson. Talan vmi low level CPU pinninggel/cgroup poolozassal lehet hatni ra.
Alapvetoen cirka 20 eve vannak multi-core cpu-k minden masinaban.
De azok egyformak.
Mar min. 5 eve vannak E core-ok is.
Igen, a Windows 10 a mai napig nem tamogatja. Windows 11-be is egy nem tul regi H release-ben adtak ki ra javitast. Elotte siman elofordult, hogy egy jatek E core-on futott, mert eppen olyan kedve volt a schedulernek.
Azert elvarom minden fejlesztotol, hogy ha ki akarja tekerni a cpu-t, akkor keszitse fel a szoftveret ezekre. Vagy keszuljon fel ra, hogy inkompetensnek lesz nevezve.
Miert is? Ez a kernel dolga. Hogyan tud egy applikacio hatni a kernelre? Vagy K8s kontextusban erted? Tudtommal nincsennek olyan annotationok, amivel szabalyozhato a default scheduler ilyen szempontbol.
- A hozzászóláshoz be kell jelentkezni
Az E-core letiltas az AVX512 miatt volt. A 12. generációban (legalábbis a korai gyártású darabokon) a P-core-on vissza lehetett kapcsolni az AVX512 támogatást, ha az E-coreokat (amiből hiányzott és azóta is hiányzik az AVX512) letiltottad. Az Intel azóta "megoldotta", hogy ezt már ne lehessen megcsinálni.
Az ütemezéssel az igazi baj, hogy az E-core-ok nem tudnak hyperthredinget sem, a P-core-ok viszony igen. Így viszont már nem lehet egyértelmű teljesítmény-sorrendezést felállítani a (logikai)magok között. A P-core egy threadje csak addig jobb a teljesen önálló E-core-nál, amíg a P-core másik threadje nincs leterhelve. És még akkor is függ attól, hogy pontosan milyen a terhelés.
Régóta vágyok én, az androidok mezonkincsére már!
- A hozzászóláshoz be kell jelentkezni
Alapvetően két iskola van.
Az AMD egyszerűbb eset. Náluk a "kis" c-s mag egy teljes értékű Zen magnak méretcsökkentett változata. Órajelet és cache méretet veszít, de amúgy mindenben megegyezik a "nagy" magokkal. Itt egyszerű a sztori, az ütemező először a nagy magokat tölti. Minél több van terhelve annál lejjebb megy az órajel. Amikor elfogynak akkor lépnek be kis magok még alacsonyabb órajelen, de közben már a nagy magok is lelassultak. Maximum az L3 cache méret jelent eltérést. Ütemezés szempontból viszonylag zökkenőmentes az átmenet.
Az Intel a problémásabb, mert a kis E-s magok teljesen más architektúrájúak, mint a nagy P-sek. Feature setben sem egyformák (ezt "megoldotta" az Intel a P magok utólagos visszabutításával). A teljesítményprofiljuk is nagyon más. Az tény hogy az Intelék többet nyernek vele méretben, ill órajelben sem vesztenek sokat (az E magok 4.5GHz-ig is felmennek, míg az AMD-nél a c-magok csak 3.3GHz-ig). De optimális ütemezés szempontból az Intel megoldása jóval nehezebb eset.
Régóta vágyok én, az androidok mezonkincsére már!
- A hozzászóláshoz be kell jelentkezni
Jaja, a zen5c sokkal szimpatikusabb, mint az idióta intel féle E-core / P-core. Eleve a Windows ütemező se bírja jól kezelni az intel hibrid szarját, mivel nem is nagyon lehet (meg kellene tudni jósolni a jövőt, az meg ma még nem megoldott a tudomány állása szerint). Ha meg nagyon optimalizálni szükséges, lehet futtatni az intel profiler tool-jait, meg mindenféle intel mágia scheduler kiegészítőket hozzá.
- A hozzászóláshoz be kell jelentkezni
Az Intel eléggé hűbelebalázs módra előreszaladt. Az AMD meg szerintem kicsit túl is óvatoskodja.
Én kb értem hogy az Intel honnan jön, az ARM big.little stratégiát próbálták egy az egyben lemásolni. Csak ott rontották el, hogy fullba tolták, a ULV-s tablet-processzortól rögtön a high-end desktopig bezárólag. És lazán "átsiklottak" olyan részletkérdések felett, hogy a kicsi és a nagy mag nem azonos utasításkészletet támogat, az egyik tud hyperthreading-et, a másik nem, stb.
Telefonokon megvoltak a bedrótozott hackek arra, hogy az appok melyik része melyikfajta magon futhat. Kb CPU pinning és az adott eszközhöz hozzátákolt power management profilok kombinációja. Nem egy kultúrált megoldás ez sem, de működik.
Az Androidos megoldásokat desktopra nem lehet (és nincs is értelme) átültetni. Ezt nézték be nagyon az Intelnél, és - ami rosszabb - utána nem korrigáltak az irányon.
Egyébként ha megnézed pl a fordítási teszteredményeket, nem járnak annyira tévúton:
https://www.phoronix.com/review/intel-core-ultra-9-285k-linux/4
Tehát az AMD-nek is muszáj lesz errefele mennie.
Az Zen5c kb 60%-a nagy Zen5 magnak. Az Intelnél az E-core kb 30%-a P-core-nak.
A Zen5c 3.3GHz-ig megy notebbokban, 3.7GHz-ig EPYC-ben. (ráadásul nem ugyanaz a két mag... ez bonyolult). Az Intel E-core 4.5GHz-ig desktopon.
Fogyasztásban is az E-core a jobb (ezt nyilván elég nehéz izoláltan mérni egy SoC, de erre utalnak az erdemények)
Régóta vágyok én, az androidok mezonkincsére már!
- A hozzászóláshoz be kell jelentkezni
Én úgy látom egy CPUban vagy E vagy P core van.
- A hozzászóláshoz be kell jelentkezni
Valaki lefordítaná Intel bullshit-ből magyarra mit akart ezekkel a hangzatos kijelentésekkel mondani, mint :
" pairing exceptionally well with a GPU as a host node CPU"
" Xeon 6 provides up to 1.5x better performance in AI inference on chip using one-third fewer cores4"
Az AI modell vagy GPU-n fut, ilyenkor túl nagy csodát nem tud hozzáadni a CPU oldal 1.5x teljesítményt biztosan nem.
Ha CPU-ból megy akkor eddig azt láttuk, hogy rendesen le van maradva az Intel AMD mögött. "Erős" magszámban úgy 1.5x ver rá az AMD az Intelre, amit az Xeon nem tud kompenzálni magonként jobb teljesítménnyel. Intel Sierra Forest E-magokkal tud nagyobb magszámot, de ott a magonkénti átlagos teljesítmény eléggé siralmas.
Ami valóban nagyot szólhatna az egy RTX4090 erejű APU, amihez 100GB-számra lehetne rakni a ramot és unified memory miatt a GPU rész is közvetlenül elérné.
- A hozzászóláshoz be kell jelentkezni
Ami valóban nagyot szólhatna az egy RTX4090 erejű APU
Pár hete az NVIDIA kénytelen volt hivatalosan cáfolni, hogy a videokártyái csatlakozója megolvadhat.
És te ezt akarod beköltöztetni a processzor belsejébe.
Sajátos ötlet, de abban föltétlen igazad van, hogy nagyot szólna.
- A hozzászóláshoz be kell jelentkezni
Sokat fogyasztó CPU-k skálázását már több tíz éve gyakoroljuk, így őszintén én is reálisabbnak tartom, mint kártya formában berakni ugyanezt a fogyasztást. Hűtés, tömeg eloszlás, kábelezés értelmes megoldása sokkal nehezebb.
- A hozzászóláshoz be kell jelentkezni
Elképzelhető, hogy nem ugyanarra a felhasználási módra gondolunk. Ha a GPU-t pár másodpercig kell nagy teljesítményen használni, akkor el tudom képzelni, hogy elemek ügyes kapcsolgatásával ezt meg lehet oldani a CPU-n belül is.
Ha viszont ugyanezen valaki órákig akar játszani (uram bocsá szimulálni), akkor vagy adsz neki vezetékolvasztó mennyiségű áramot, vagy nem lesz számítási teljesítményed. Én ezt nem nevezném skálázásnak.
Jensen Huang nemrég azzal a szöveggel promózta az új cuccot, hogy "akkora, mint négy elefánt". Az nyilván nem a processzor, hanem a hűtése.
- A hozzászóláshoz be kell jelentkezni
> És te ezt akarod beköltöztetni a processzor belsejébe.
erdekes, az Applenek sikerult mar az M1-ben is, sot meg a mobilokban is... ott tartunk hogy egyes AI modelek jobban futnak egy iphone-on mint egy xeon procis szerveren.
- A hozzászóláshoz be kell jelentkezni
Annak köze nincs egy 4090-hez teljesítményben.
- A hozzászóláshoz be kell jelentkezni
Most mért mondasz ilyet? Elmegy rajta egy mIRC meg egy szövegszerkesztő nem?!
(Valójában, az Apple-nek a szerver témához nem volt soha semmi köze ... erőtlen próbálkozásait ne nevezzük annak)
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Sőt, energiahatékonyabb is. Láttuk a snapdragonos laptopokon, meg a 45W-os CPU-ikat :D
- A hozzászóláshoz be kell jelentkezni
pairing exceptionally well with a GPU as a host node CPU
Halványan arra tippelnék, hogy itt a(-z integrált?) memóriavezérlő sávszélességét magasztalják. CPU és GPU (vagy bármilyen más PCIe végpont) között MMIO BAR-okon keresztül, ill. bus master DMA-val lehet tömegesen adatot cserélni. (Előbbi esetben a kártyán van a RAM, esetleg a kártya elcsórja a system RAM-ból, utóbbi esetben system RAM-ról van szó -- de lehet, hogy amit erről tudni vélek, az már elavult.) Arra utalhatnak, hogy az új Xeon-nal folyamatosan lehet "etetni" a modern GPU-kat.
- A hozzászóláshoz be kell jelentkezni
> amihez 100GB-számra lehetne rakni a ramot
az a baj, hogy nem lenne eleg gyors... a gpu-knal mar ddr6x es hasonloknal tartanak, szervereken meg meg a 3ghz ddr4 is ritkasag. raadasul a registered modulok eleve lassabb cimzesuek/eleresuek, bar jo cache prefetchel ez kompenzalhato. de mar egy 48 magos szervert sem lehet kihasznalni ai-ra mert folyton a memoriara var...
nezzunk pl egy deepseek-et (ott jott elo leginkabb ez a vegtelen sok memoriaigeny problema), a V3/R1 model 8 biten (Q8) 700GB, ezt minden egyes token generalashoz vegig kell olvasni, 2 t/s-hez 1500GB/s memoria savszel kell! ha csokkented a meretet (bitek szamat) akkor aranyosan gyorsul, pedig pontosan ugyanannyit kell akkor is szamolni, csak kevesebb bitbol tolti be a tensorokat.
- A hozzászóláshoz be kell jelentkezni
Ha hinni lehet a cikknek ami itt is kapott egy külön fórumot, akkor tisztán cpu modellt futtatva 512GB ddr4 ram társaságában (szerintem mégcsak nem is 3ghz) a Deepseek r1 671b elfutott rajta. Valóban várni kell az átlagos válaszokra 10-20 másodpercet de ez a cikk szerint és szerintem is vállalható kompromisszum. Ahogy a 4-bit kvantálás is, mert ennyi ram mellett is csak ezzel fér el a memóriában.
- A hozzászóláshoz be kell jelentkezni
Valaki lefordítaná Intel bullshit-ből magyarra mit akart ezekkel a hangzatos kijelentésekkel mondani,
Azt. hogy 70+% a market share-ünk szerver CPU téren
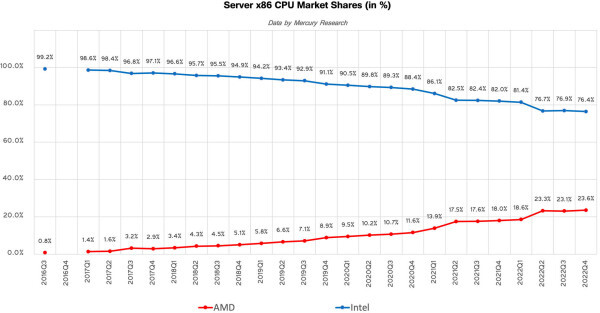{kind=link}
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Idézet a cikkből amit linkeltél:
"While Intel earned $3.0 billion selling 75.9% of data center CPUs (in terms of units), AMD earned $2.8 billion selling 24.1% of server CPUs (in terms of units), which signals that the average selling price of an AMD EPYC is considerably higher than the ASP of an Intel Xeon. "
- A hozzászóláshoz be kell jelentkezni
Egy HBM-mel kapcsolatos mostani cikkről jutott eszembe: Olyan érdekelne, amin 1TB van, de SSD-ből?
- A hozzászóláshoz be kell jelentkezni
Az AI modell vagy GPU-n fut, ilyenkor túl nagy csodát nem tud hozzáadni a CPU oldal 1.5x teljesítményt biztosan nem.
A legujabb AMD/Intel CPU-kban van integralt NPU, es nem is gyenge (30-100+ TOPS -ot olvastam). Pl itt egy sima ryzen 50 TOPS-ot tud, es ez mar 1 eves...
Nomeg ugye a stream processzorok azert alapvetoen nem inference-re lettek kitalalva. Egy integralt celhardver joval olcsobban tudja ugyanazt.
- A hozzászóláshoz be kell jelentkezni
Ez is érdekes. https://www.amd.com/en/products/accelerators/instinct/mi300/mi300a.html
24 Zen4 core, és 228 CNDA3 Compute Units, ez egy APU.
- A hozzászóláshoz be kell jelentkezni
szep szep de ennyiert mar vehetnek 5db A100-at
https://smicro.hu/amd-instinct-mi300a-128gb-hbm3-100-200000001h-4
az X-es meg jobb, ebbol mar csaladi hazat is vehetnek:
https://smicro.hu/amd-instinct-mi300x-192gb-hbm3-100-300000045h-4
- A hozzászóláshoz be kell jelentkezni
Biztos az az 5 darab?
https://smicro.hu/nvidia-a100-80gb-cowos-hbm2-pcie-w-o-cec-900-21001-00…
- A hozzászóláshoz be kell jelentkezni