- A hozzászóláshoz be kell jelentkezni
- 1751 megtekintés
Hozzászólások
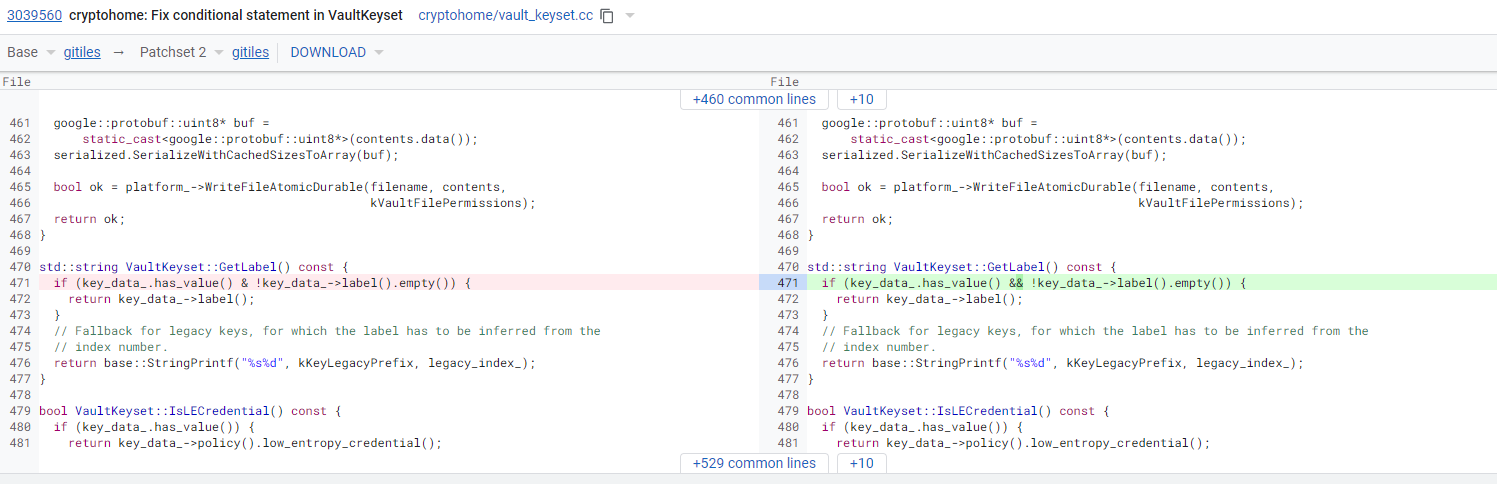
„Chrome OS fiaskó: Amikor egy egy karakteres elgépelés átmenetileg használhatatlanná teszi a gyártó eszközét”
És?
- A hozzászóláshoz be kell jelentkezni
Nem az a baj, hogy valaki ilyen hibat vet. Az a baj, hogy ez kikerult. Tenyleg senki nem probalt meg bejelentkezni az uj verziora (mondjuk elkezdeni a teszteleset) mielott elkezdtek terjeszteni?
- A hozzászóláshoz be kell jelentkezni
Én is ezt akartam kérdezni. Fel sem rakták egy gépre, hogy bebootol-e, mielőtt kiment élesre?
Ha csak a fejlesztő a saját gépére felrakta volna, hogy lefut-e, egyből kiderült volna, hogy nem tud rá belépni. Arról nem is beszélve, hogy van canary, dev meg beta channel is, azokon hogy nem bukott ki?
Nagy Péter
- A hozzászóláshoz be kell jelentkezni
error vs failure :)
- A hozzászóláshoz be kell jelentkezni
Nem tudom hogy a chrome os frissitéseit hogy tolják ki, de a google régebben a nexus eszközöknél graceful rolloutot tolt, azaz első lépésben kiválasztott random 1%nyi usert, akik megkapták a frissitést, majd egy ideig csak ők "élvezték". Igy ha valami nagy gebasz volt, nem ment gajjra egyszerre az összes eszköz.
Ez egy csúnya damage contol eljárás, ami lazit egy kicsit a qa elvárásokon.
- A hozzászóláshoz be kell jelentkezni
Már a 2010-es évektől nem van Q&A. Mikroszoft is kibaszta az összes tesztelőjét még 2014-ben, aztán látjuk mi van w10-el 2015 óta. Guglinál valószínűleg meg soha nem is voltak tesztelők. Ma edzsájl és devopsz van, teszteljen csak a fejlesztő maga, senki más. Ja, meg bevonjuk a végfelhasználókat ingyen bétateszternek. Nem hogy nem fizetünk nekik ezért a munkáért, de még a saját tulajdonú teszt eszközüket is téglásíthatjuk ha vmi rosszul sül el.
- A hozzászóláshoz be kell jelentkezni
C++ kódtól mit várunk?
A legdühítőbb az egészben, hogy ezért lenne a bool típus, de úgy látszik büdös nekik használni.
Ez a legnagyobb baj a C++-al, hogy rengeteg programozási paradigmát támogat, aztán mindenki úgy használja ahogy épp szeretné, a végén meg ebből nehéz összegyúrni egy konzisztens valamit. Ilyen szempontból a C sokkal jobb, ott valahogy mindig adja magát, hogy egy feladatot hogyan érdemes megoldani.
Jó persze ilyen szintű elgépelés bármilyen kódban lehet, de ezt éppen a nyelv megfogta volna, ha normálisan használják. Mostanában úgyis szeretünk a svájci sajt modellre hivatkozni, ez pont egy ilyen szűrő.
- A hozzászóláshoz be kell jelentkezni
Az ilyet a fordítónak is illik megfognia. Most lusta vagyok kipróbálni, de úgy rémlik, a gcc dob rá egy warning-ot. Persze az szart sem ér, ha a warning-okra nem figyelnek oda.
Szerk.: nem fogja meg a g++ sem. Viszont nem értem, miért nem működik az eredeti kód. Ha mindkét érték bool, akkor az & operátornak ugyanúgy jónak kellene lennie, mint az && operátornak.
- A hozzászóláshoz be kell jelentkezni
Lehet, hogy a g++ nem fogja meg, de a statikus kód analízis biztos, ilyen kódnak nem lenne szabad kimennie.
Amúgy azt gyanítom, hogy a különbség az, hogy a && operátornál van short circuiting, a sima &-nél nincs, és a key_data_->label() így elszáll, ami amúgy már önmagában is rossz design (pont emiatt...).
- A hozzászóláshoz be kell jelentkezni
Valóban, a short circuit probléma akkor is, ha bool mindkettő.
De tudjuk hogy bool-e mindkettő? Én nem néztem utána. Ugyanakkor az sem egy jól megdesign-olt rendszer, ha egy metódus hívásra exceptiont, vagy akármit dob, főleg egy empty()-re. Ezt az érték ellenőrzést már abba bele kellett volna építeni.
- A hozzászóláshoz be kell jelentkezni
Ahogy nézem A KeyData protobuf2 által generált cucc, ráadásul optional-eket is használnak. Nem véletlenül került ki az optional a protobuf3-ból.
- A hozzászóláshoz be kell jelentkezni
De ha a fejlesztő becsukott szemmel vagy a warningokat letiltva fordít, akkor is el kéne kapnia egy bejelentkezést megakadályozó hibát az automata teszteknek.
disclaimer: ha valamit beidéztem és alá írtam valamit, akkor a válaszom a beidézett szövegre vonatkozik és nem mindenféle más, random dolgokra.
- A hozzászóláshoz be kell jelentkezni
elnézést, de ez konkrétan nem igaz: a C++ jóval típusbiztosabb, mint a C.
Szoktam a C++ nyelvet ekézni, de a C és C++ között nem is érdemes gondolkozni, hogy melyiket kell választani, ha a platformod megengedi, csakis c++ (ha van normális fordító, elég memória stb).
- A hozzászóláshoz be kell jelentkezni
A C++-t? Mondd meg nekem, hogy mi a pl. az fstream::open első argumentuma? Hát véletlenül sem std::string, hanem const char*.... na így ebből soha nem lesz egy konzisztens nyelv, ahol már a C++ standard library is el van cseszve. Meg ahol ahány lib, annyi adattípus?
Hát bármit, csak a C++-t nem. A nyelv overheadje sokkal több hiba forrása, mint egy faék egyszerű C, ahol van 4 adattípus, oszt jónapot.
Persze van egy freedesktop-plague a C-ben is, ahol rá akarják erőltetni az objektum-orientált szemléletet, de ezektől eltekintve C-ben sokkal könnyebb jó és karbantartható kódot írni, mint C++-ban.
Ahol meg jól jönne a C++ magasabb absztrakciója, ott már általában elég erős a vas, hogy interpretált nyelvet használjak. Eleve a számításigényes lib-ek ki vannak sokszor szervezve valami low-level nyelvbe, fent meg simán jó akár egy python is. Nagyságrendekkel könnyebb debugolni.
A C++ pont egy olyan helyen van, ami ma már nem kell sehova. Nem vitatom tőle, hogy az egyetlen igazán magas szintű nyelv, amit úgy írtak, hogy a teljesítmény számít, de ettől még generic programozásra nagyon nem használnám.
- A hozzászóláshoz be kell jelentkezni
Qt-ben azért egész használhatóvá tették.
C-ben én hülyét kapok a string függvényektől. Pl. ott van a "biztonságos" strncpy, ami vagy tesz \0-t a végére, vagy nem. Vagy strncat, sehol se veszi figyelembe a cél buffer hosszát, pedig nyilván megoldható lenne teljesítménycsökkenés nélkül, mert csak végig kell nyálaznia a célbuffert, hogy hol a vége. És persze \0 itt is vagy lesz, vagy nem.
- A hozzászóláshoz be kell jelentkezni
Jo, de ezek helyett minden tapasztaltabb C programozo snprintf-et hasznalna.
NetBSD - Simplicity is prerequisite for reliability
- A hozzászóláshoz be kell jelentkezni
Oké, de azért nem ugyanaz, az str(n)cat az a meglévő bufferbe dolgozik, az snprintfnek pedig kell egy újat foglalni. Mikrovezérlőn ez is számít. És ettől függetlenül még a biztonságosabb (n)-es függvényeket se sikerült jól megoldani. Ott van még az strlcat, az eggyel jobb (legalább a teljes célbuffer hosszát nézi), de nem sztenderd.
- A hozzászóláshoz be kell jelentkezni
Ne haragudj, de olyan dolgokat írsz, amelyek talán 15 éve sem voltak igazak, nemhogy ma, típusbiztos, szálbiztos, és maximális teljesítményű templatizált standard library mellett.
A C++ magasabb absztrakciója 99.9%ban teljesítmény előnnyel párosul a C-vel szemben, nem hátránnyal.
Itt és most szélmalmokkal hadakozol, nem ismered, amiről írsz.
- A hozzászóláshoz be kell jelentkezni
Napi szinten valóban nem programozok C++-ban, de annyira ismerem, amennyire kell.
Mint írtam nem a nyelv teljesítményével van probléma, az overhead-et nem erre értettem, hanem az absztrakcióra. És nem is csak arra, hogy magasabb szintű, az nem lenne probléma, az a gond, hogy a C++-ba megpróbálták kb. az összes programozási paradigmát beletenni. Mindezt úgy, hogy a C-vel maradjon kompatibilis.
Nyilván más emberek, team-ek más paradigmákban fejlesztenek. Az adattípusok pedig annyira absztraktak, hogy egy csomó glue-t kell közéjük írni, ha az egyik lib adattípusát fel akarnád használni egy másik metódusával.
Linus-nak épp ez volt a baja a C++-al.
Vannak class-ok, de megvannak a C-ből örökölt típusok. Vannak referenciák, de maradtak a pointerek is. Van öröklés és van aggregation is - még ha nem is mindig egy-az-egyben helyettesíthetők, de sokszor ki tudják egymást váltani. Dobálunk exceptiont, de néha return value-t használunk. A templatek valóban jó cucc, csak jó lenne használni is.
Hány olyan std:: függvény van, ami pl. std::vector-t vár? És mennyi, ami xy[]-t? Na erről beszélek, amikor inkonzisztenciákról írok.
A nyelv hibája? Nem feltétlen. A nyelv hibája csak olyan szinten, hogy ennyi félét is megenged.
- A hozzászóláshoz be kell jelentkezni
std::unordered_map<std::string, MyStruct> dict;
Amíg ezt C-ben leimplementálod, lemegy a nap. C++-ban meg garantált viselkedésű, agyontesztelt kódot kapsz 1 sor beírásával.
Dolgoztam beágyazott C-s világban, ahol olyan korú boomerek, mint én, ragaszkodtak hozzá, hogy de bizony maradjunk a C-nél... nem volt jó ötlet, iszonyúan elszállt a C felett az idő.
- A hozzászóláshoz be kell jelentkezni
Akkor miert szolsz bele olyan dolgokba, amihez lathatoan nem ertesz?
NetBSD - Simplicity is prerequisite for reliability
- A hozzászóláshoz be kell jelentkezni
Tesztelni, meg majd én fogok, mi? :)
Amúgy ezt még talán egy linter is kiszúrná, nem? Megjegyzem, nem vagyok fejlesztő.
- A hozzászóláshoz be kell jelentkezni
Mostanában ez a hozzáállás mindenhol, nem csak a Google-nél, de Red Hat-nél, MS-nál is. Óriási kódbázisok vannak, sok millió kódsor, ember nem tudja már átnézni, áttekinteni, rendesen kitesztelni, ezért csak kiadják, bízva benne, hogy jó, ha meg mégse, szívjanak vele a userek, majd legfeljebb később foltozzák. Az összes böngésző is ilyen, még a Linux kernel is.
“Windows 95/98: 32 bit extension and a graphical shell for a 16 bit patch to an 8 bit operating system originally coded for a 4 bit microprocessor, written by a 2 bit company that can't stand 1 bit of competition.”
- A hozzászóláshoz be kell jelentkezni
Azért van egy dogfood kultúra is az ilyenek elkerülésére.
- A hozzászóláshoz be kell jelentkezni
Ebből is látszik, hogy a ChormeOS nem alkalmas produktív munkára. Még a saját alkalmazottaik se használják.
Szokásos Google minőség.
- A hozzászóláshoz be kell jelentkezni
Védelmükre legyen mondva, hogy nem is állították, hogy alkalmas komoly munkára. Lightos, webes felhasználásra van. Ami nekem gondom van az egész ChromeOS-sel, hogy nincs előnye egy normális Linuxszal szemben, csak hátránya. Emiatt én sose használnám, valahogy senki földje. Csak az tartja életben, hogy olcsó Chromebookokkal együtt adják, amik az USÁ-ban elég népszerűek, főleg az oktatásban, meg diákoknál, akik minimális pénzből akarnak tanulógépet venni.
“Windows 95/98: 32 bit extension and a graphical shell for a 16 bit patch to an 8 bit operating system originally coded for a 4 bit microprocessor, written by a 2 bit company that can't stand 1 bit of competition.”
- A hozzászóláshoz be kell jelentkezni
- A hozzászóláshoz be kell jelentkezni
Lehet úgy OS-t frissíteni, hogy nem vagy bejelentkezve?
- A hozzászóláshoz be kell jelentkezni
Igen, vendégként (vagy akár másik fiókkal is) be tudsz lépni, onnan lehet frissíteni.
- A hozzászóláshoz be kell jelentkezni
Ha egyik fiókkal nem lehet belépni egy bug miatt, akkor másikkal miért lehet?
- A hozzászóláshoz be kell jelentkezni
Engem a vendégként frissítés jobban megfogott :)
- A hozzászóláshoz be kell jelentkezni
Akkor is frissít egy idő után, ha senki nem lép be. Vendégként belépve meg tudod gyorsítani ezt a folyamatot.
- A hozzászóláshoz be kell jelentkezni
érteni értem, csak, szóval nahát :)
- A hozzászóláshoz be kell jelentkezni
A leírás szerint "Affected devices can login via guest mode or an account that hasn't signed into the device". Gyors ránézés alapján a hiba abban a kódban volt, ami az eszközön letárolt adatok titkosításának feloldásáért felel, ez valószínűleg nem fut akkor, amikor új fiókkal lépsz be.
- A hozzászóláshoz be kell jelentkezni
Az "and" operátor már ősidők óta része a c++-nak, 2003 óta biztosan, de valahogy ez egy hülye C-s beidegződés, hogy az && formát használja mindemki.
- A hozzászóláshoz be kell jelentkezni
Egyetértek. Ezek a hieroglif tömör operátorjelek mindig is zavartak a C-ben, nehezen szoktam meg őket, ++, &&, &pointer, >>, -> stb.. Egyszerűen and-ként, meg a=a+1 formában sokkal emberibben kiolvasható, főleg azoknak, akik nem C-szerű nyelvben kezdtek el programozni. A másik, meg a könnyű elgépelhetőség, én ugyan ezt az && vs & elgépelést még nem szívtam meg, de a == vs. = elírást már elég sokszor, és fordító nem szól érte, az ember meg nem érti, hogy miért nem értékelődik ki az elágazás, miért nem fut rendesen a ciklus. Még a ; is olyan, hogy évek után is elfelejti kitenni az ember ide-oda, állandó frusztrációforrás. Pont emiatt a gépi, low level szintaxisa miatt nem szeretik sokan a C-t, és preferálják a Pythont meg a többi emberbarátabb szintaxisú nyelvet.
Ezekre be kéne vezetni alternatív operátorokat, hogy ha valaki olvashatóbb formában akarja kiírni, akkor legyen rá lehetősége.
Egyébként ebben még nem is a C-szintaxisú nyelvek a legrosszabbak. Bash-sal, zsh-csel, meg egyéb POSIX-kompatibilis shellekben (pl. dash) állandóan szívok az If-es szerkezeteknél, a nehezen megjegyezhető -n, -z feltételösszehasonlításnál, az egyszeres és kétszeres [ ] vs. [[ ]] jelekkel, hogy kell-e pontosvessző, hova kerüljön a then, stb., állandóan keverem, lehetetlen megjegyezni. Főleg, ha valami összetett feltételt kell vizsgálni, rohadt könnyű félreírni az if-es szerkezeteket. Nagyságrendekkel rosszabb a C, C++-nál.
“Windows 95/98: 32 bit extension and a graphical shell for a 16 bit patch to an 8 bit operating system originally coded for a 4 bit microprocessor, written by a 2 bit company that can't stand 1 bit of competition.”
- A hozzászóláshoz be kell jelentkezni
ott sincs eleg automatizalt teszt....amatorok.
- A hozzászóláshoz be kell jelentkezni
Ezt egy static code analyzer kiszúrta volna nem? Legalább eg warning-al hogy gyanús...
- A hozzászóláshoz be kell jelentkezni