- A hozzászóláshoz be kell jelentkezni
- 4582 megtekintés
Hozzászólások
Tok jo! Mi is ez?
- A hozzászóláshoz be kell jelentkezni
Azt hiszem Solaris kernel van alatta, tehát zfs, de mindjárt utánaolvasok ;)
- A hozzászóláshoz be kell jelentkezni
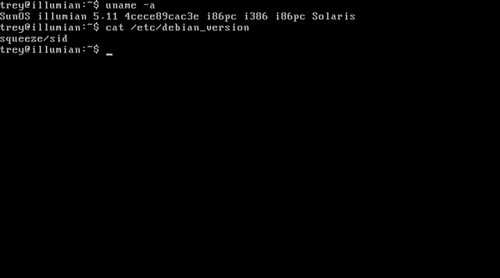
Az a squeeze/sid version nagyon mokas.
--
|8]
- A hozzászóláshoz be kell jelentkezni
Ja. :) Friss a dolog. :)
----
"Mert nincs különbség: mindenki vétkezett, és híjával van az Isten dicsőségének. Ezért Isten ingyen igazítja meg őket kegyelméből, miután megváltotta őket a Krisztus Jézus által." (Róma 3.22-24)
- A hozzászóláshoz be kell jelentkezni
Remélem sikeres lesz és nem fog elveszni, mert egy választási lehetőséget biztosít azoknak a vállalkozásoknak, akkor a Debin/Ubuntu-val már elkezdtek barátkozni, de egy nagyvállalati környezethez közelebb álló rendszerre vágynak.
Ha jól olvastam, akkor mindent tud amit a Solaris szerver szolgáltatásként nyújtott csak a csomagkezelőt cserélték le.
Ha jól láttam a telepítés egy átlag PC-n történt?
- A hozzászóláshoz be kell jelentkezni
"Ha jól láttam a telepítés egy átlag PC-n történt?"
Igen. VMware-en.
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Vajon többen fogják használni, mint a Debian GNU/kFreeBSD-t? Értelme is több van?
-----
"Egy jó kapcsolatban a társunkat az ő dolgában kell támogatni, nem a miénkben."
rand() a lelke mindennek! :)
- A hozzászóláshoz be kell jelentkezni
Én mint Debiant több mint egy évtizede használó ember, nem értem mi értelme ennek a projektnek. Ha Solaris kell, akkor ott az OpenIndiana. Ha linux kell, akkor meg ott a Debian. Nem rosszabb annyival az IPS, pontosabban, mivel az is teszi rendben, csendben a dolgát a háttérben, ahogy kell, nem érdekeltek a részletei...
Repót tud kezelni. Függőségeket tud kezelni. Repó hitelesítés megoldott.
Még arra tippelek, hogy Debianhoz értő fejlesztőket próbálnak toborozni, hátha így a saját fejlesztői bázisuk nagyobb lesz. Talán.
- A hozzászóláshoz be kell jelentkezni
Számomra a zfs egy olyan dolog, ami miatt látok benne fantáziát.
- A hozzászóláshoz be kell jelentkezni
Van olyan dolog, amit a zfs-el meg lehet csinalni es standard linuxos toolokkal (akar tobbet hasznalva) pedig nem?
Sosem hasznaltam zfs-t (nem is valoszinu, hogy fogok a kovetkezo evekben), de mar sokat hallottam rola es egyszeruen erdekel, hogy miert jobb.
- A hozzászóláshoz be kell jelentkezni
Ja majd egyszer talán a btrfs-sel :D. Bár az se fog tudni annyira beleintegrálódni az oprendszerbe, mint a zfs, illetve nem lesz valszeg annyira stabil. No meg fsck???
Amúgy nézd meg mit tud a zfs jelenleg stabilan, és mi az amikre még sajnos fényévre van bármilyen hasonló filerendszer linux alá.
- A hozzászóláshoz be kell jelentkezni
Felreertettel.
Tehat, amit kerdezni akartam: van-e olyan dolog, amit nem lehet megcsinalni linux alatt standard tool-ok segitsegevel de zfs-el meg lehet ( ertsd pl. LVM+mdadm+whatever, engem igazabol nem erdekel, hogy nem egy layer-be van implementalva, az eredmeny szamit ).
A btrfs igeretesnek tunik, meg is neztem mit fog tudni, de maradok ezen a szinten es nem foglalkozom vele, amig nem lesz stabil.
- A hozzászóláshoz be kell jelentkezni
Melyik részét szeretnéd tudni?
Azt a részét amit meg lehet 60 tool-lal meg mindenfélével oldani, de nem fog úgy működni ahogy zfs alatt működik. Pl. snapshot ilyen. Meg lehet csinálni mondjuk lvm + ext3-mal is, de több okból is trágya. Pl. kell neki külön snapshot volume-t csinálni, aztán ha valami gebasz van, lehet görcsölni, hogy feléleszd. Pl. ha betelik, azt nem szereti :). Aztán meg lehet csinálni a titkosítást is luks-szal de az sem az igazi (nem kényelmes).
Deduplikációval rendelkező fs-t mondjuk nem tudnék mondani most hirtelen.
De ez csak egy kis része amit a zfs tud. Egy nagyon gyors, nagyon stabil, nagyon sok ficsőrrel rendelkező filerendszer.
Iszonyat kényelmes. Pl. lvm-nél csinálsz vg-k alatt lv-ket. Elb.szod a méretezést. Az egyik lv-n csak kb 5% a kihasználtsága a filerendszernek. Egy másik tele van, de a vg-n már nincs szabad hely. Csökkenteni nem tudod azt amin van még hely, csak körülményesen (adat lement, lv töröl, új lv, adat másol, másik lv növel, filerendszer növelés stb). Na most zfs-en ez nem kicsit könnyebb feladat. Aztán ott van, hogy egyszerre stabil, és gyors a filerendszer, ezt szintén nem tudod linux alatt elérni. Egyik gyors, másik stabilabb, harmadik mindenben szar. De még a stabilon is eltudnak veszni a file-jaid pl.
Aztán zfs-n menet közben be-, és kitudod kapcsolni a valós idejű filerendszer tömörítést.
És még van jó pár ilyen dolog. Tegyél fel egy solaris-t, vagy freebsd-t, vagy akár ezt az Illumiant, és nézd meg.
- A hozzászóláshoz be kell jelentkezni
+ ha jól tudom, linuxon ha elkezdesz snapshotolgatni, az ront és ront az adott FS hatékonyságán.
ZFS meg okosabb: feljegyzi a blokkreferenciákat snapshotolás, vagy a PE-k előre kiosztogatása helyett. Sok, nagyon sok előny jön abból, hogy egy réteg kezeli az fs(opcionálisan), az lv, és a raid rétegeket!
Még úgy is rengeteg hasznát veszem, hogy iscsi-n osztok ki lun-okat szerverek alá!
Egy jó SSD-vel, amit l2arc-nak és zil-nek odaadtam a pool-hoz, olyan szinten gyors& jó, hogy a kolléga inkább iSCSI-ről kért a SSD+SATA diszkek kombós OpenIndiana-s szerverről diszket, mint a szerverben fizikailag levő SAS-ról egy LV-t. Mindezt úgy, hogy előtte méricskélt, tesztelte, nyúzta mindkettőt!
- A hozzászóláshoz be kell jelentkezni
Pl. lvm-nél csinálsz vg-k alatt lv-ket. Elb.szod a méretezést. Az egyik lv-n csak kb 5% a kihasználtsága a filerendszernek. Egy másik tele van, de a vg-n már nincs szabad hely. Csökkenteni nem tudod azt amin van még hely, csak körülményesen (adat lement, lv töröl, új lv, adat másol, másik lv növel, filerendszer növelés stb).
Ez így tudtommal nem igaz.
Ext3/Ext4-nél tudod csökkenteni a fájlrendszer méretét (nem online).
Utána csökkentheted az LV-t, növelheted a másik LV-t és hozzá méretezheted a fájlrendszert.
(Fixme)
Azt nem vitatom, hogy ilyen fájlrendszer méretezgetést nyugodtabban csinál az ember ha van backup.
Csak azért írtam, hogy félre azért ne vezessünk senkit, ha félreértettem valamit, akkor elnézést.
- A hozzászóláshoz be kell jelentkezni
Es ne felejtsuk h tenyleges checksumolas van az adatokra es a metaadatokra ZFS-es raid-1ben ami a Linuxos SW Raid-1 -ben nincs (md alrendszer), es igy azt kicsit nevetseges teljes erteku mirrornak hivni.
- A hozzászóláshoz be kell jelentkezni
Csak egy kérdés, no offense.
A hardware-es RAID vezérlőkben mindben van ilyen checksumolas az adatokra RAID1 esetén (mondjuk blokk szinten, mert ugye fájl és metaadat szinten ez nem megoldható ott)?
Ha nincs, akkor jól értem, hogy azokat is mind kicsit nevetseges teljes erteku mirrornak hivni?
- A hozzászóláshoz be kell jelentkezni
"A hardware-es RAID vezérlőkben mindben van ilyen checksumolas az adatokra RAID1 esetén"
Leginkább egyikben sincs. Ha lenne, akkor raid1-ben kevesebb nettó kapacitásod lenne, mint a diszkek fele, mert a checksumot is tárolni kéne valahol.
A raid nem erről szól, hanem leginkább a teljes drive kiesésének kivédéséről.
A normális raid implementációk szokták ugyan üres idejükben a diszkeket ellenőrizni (scrubbing), de a hibás blokkok újramappelése leginkább a diszkek feladata.
- A hozzászóláshoz be kell jelentkezni
Köszi, én is így tudtam.
A normális raid implementációk szokták ugyan üres idejükben a diszkeket ellenőrizni (scrubbing)
md raid is csinál hasonlót, általában itt található a cron bejegyzés hozzá: /etc/cron.d/mdadm
# cron.d/mdadm -- schedules periodic redundancy checks of MD devices
...
- A hozzászóláshoz be kell jelentkezni
Hat amivel nekem dolgom (adaptec, 3ware) volt az mindig elkulonitett nemi adminisztrativ teruletet (3ware-en DCB - drive configuration block), es ott tartott nemi checksumot (az hogy milyen szintut az mas kerdes, tehat hogy ha 2 blokk meghibasodik akkor tudna-e h az egyik az egyiken masik a masikon korrekt). persze lehet hogy nem az adatok cheksumolasara szolgalt, de akkor miert evett volna vagy 50 megat 200 gigas vinyonal?
De megkockaztatom h a huzosabb NAS-ok durvabb checksumokat is csinalnak. Mondjuk ott valszeg mar nem sima mirrorok, hanem tobb paritasvinyo, etc van.
Javitsatok ha tevednek.
- A hozzászóláshoz be kell jelentkezni
raid1 (tükrözés) esetén nincs semmi checksum, vagy paritás.
Egyes raid vezérlők elvileg leszedhetnek valamennyit a diszkekből valamilyen adminisztatív célra (raid állapotok statisztikák, vagy dirty region tárolására, stb.), de azt te is beláthatod, hogy 200GB adatdiszkhez nem nagyon lehet semmit 50MB területtel checksumolni.
"De megkockaztatom h a huzosabb NAS-ok durvabb checksumokat is csinalnak. Mondjuk ott valszeg mar nem sima mirrorok, hanem tobb paritasvinyo, etc van."
Ez nem a hardver függvénye, hanem a használt raid implementációé.
A 200 millió forintba kerülő storage sem fog adatot checksumolni, raid1 esetén.
Raid5, Raid6, stb. esetén van paritás, de ez konkrétan ezekhez a raid algoritmusokhoz köthetők, és nem az azokat implementáló eszközhöz.
- A hozzászóláshoz be kell jelentkezni
A mappeles az a drive feladata de h a mappeles soran kiosztutt uj tarteruletre mit irjon, na az mar a raid1 layer feladata, nem?
Amugy sajnos nem csak az a hiba, h bad block van, van h csak kulonbozik a 2 vinyo tartalma. A raid1-nek akkor dontenie kell h mi a teendo, melyik a jo.
Bad block eseten nyilvanvalo h melyik rossz.
- A hozzászóláshoz be kell jelentkezni
A raid1-nek akkor dontenie kell h mi a teendo, melyik a jo.
A raid1-ek olvasásnál jellemzően NEM olvassák el mindkét diszket, és NEM próbálnak azon gondolkozni, hogy melyik lehet a jó. Vagy csak az egyikről olvasnak (a butábbak), vagy egyik kérés ide megy, a másik meg a másik.
- A hozzászóláshoz be kell jelentkezni
Asszem allithato szokott lenni, hogy mindkettot olvassa-e vagy a leggyorsabb modon megossza az olvasasokat a diszkek kozott. Mondjuk egy diszket is eleg olvasni ha van rajta checksum, h konzisztens-e.
- A hozzászóláshoz be kell jelentkezni
Aztán ott van még a copy és a compress funkció is.
Az fsck mentes világról már nem is érdemes szót ejteni.
(btrfs fsck.never rulez!!)
- A hozzászóláshoz be kell jelentkezni
"btrfs fsck.never rulez"
Az megvan - a listán írta valaki, majd megkeresem -, hogy nem is biztos, hogy lesz (egyelőre) olyan fsck a btrfs-hez, ami probléma esetén rendbe teszi, hanem helyette egy olyan utility lesz, ami menti az összeborult fs-ről ami menthető?
Szerk:
Getting a repair tool right is a hard problem; without a lot of care, a well-intentioned attempt to repair a filesystem can easily make it worse. Data that may have been recoverable before the repair attempt may no longer be so afterward. Even if a proper btrfsck were available today, it would probably be some years before it reflected enough experience to inspire confidence in users who are concerned about their data.
So it seems that something else is required. That "something else" turns out to be a data recovery tool written by Josef Bacik. This tool has a simple (to explain) job: dig through a corrupted filesystem in read-only mode and extract as much of the data as possible. Since it makes no changes, it cannot make things worse; it seems like a worthwhile tool to have around even if a full repair tool existed.
That tool, along with all the requisite filesystem support, is expected to be available in the 3.2 kernel time frame. Meanwhile, there is a new btrfs-progs repository that will include the recovery tool in the near future. All told, it may not be quite the btrfsck that some users were hoping for, but it should be enough to make those users feel a bit more confident about entrusting their data to a new filesystem.
Forrás: https://lwn.net/Articles/465160/
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Ez jó:
"it may not be quite the btrfsck that some users were hoping for, but it should be enough to make those users feel a bit more confident about entrusting their data..."
Nem olyan lesz, amilyenre számítanátok, de ahhoz elég lesz, hogy azt higgyétek, rábízhatjátok az adataitokat - tehát nem az a lényeg, hogy mit fog tudni, hanem hogy elhitesse magáról, hogy megbízható :)
- A hozzászóláshoz be kell jelentkezni
Hahh! Nahát. Mikoris? Enterspájz FS osz't hullanak a bitek hűvös halomba.
- A hozzászóláshoz be kell jelentkezni
Kezd az az érzésem támadni, hogy eddig is azért nem készült el az fsck, mert amikor "megálmodták", hogy milyen legyen a fs, akkor erre pont nem gondoltak, hogy fsck is kellhet, és végül sikerült olyanra tervezni, hogy gyakorlatilag nem lehet hozzá épeszű javítást is csináló fsck-t írni, és most már lassan évek óta azon törik a fejüket, hogy hogyan oldják meg ezt a helyzetet... :D
- A hozzászóláshoz be kell jelentkezni
Ezzel csak az a gáz, hogyha borul a bili, akkor kell egy rakat hely, ahova visszarángathatod a vissznyerhető adataidat. Optimális esetben még egyszer akkora terület, mint a beborult fájlrendszer.
Mit mondjak, fasza.
- A hozzászóláshoz be kell jelentkezni
Van olyan dolog, amit a zfs-el meg lehet csinalni es standard linuxos toolokkal (akar tobbet hasznalva) pedig nem?
Könyvtárhierarchia, amely egy közös tárolóterületen osztozkodik, és könyvtáranként, akár könyvtárszintenként is tudsz quotát mondani, ill. snapshotokat csinálni.
Pl. van egy közös nagy home tárterület, rajta sok kar/tanszék/kollégium felhasználói, esetleg cégcsoportnál cég/főosztály/osztály bontásban ugyanez. Minden szinten tudsz mondani quotát, minden szinten tudsz csinálni snapshotokat.
Más: emlékeim szerint az LVM snapshot jelenleg nem tud az LVM tükrözéssel együttélni (nem tudod tükrözni a snapshot területét). Ergó vagy HW RAID, vagy MD felett LVM-ezel (így elveszted a rugalmasságot - nem tudsz temp fs-eket RAID védelem nélkül csinálni, plusz minden resync az egész diszket érinti), vagy az LVM snapshotjaidat nem védi semmi. Ez azért enterprise környezetben gáz.
- A hozzászóláshoz be kell jelentkezni
Ebben nem vagyok biztos és most nem is állok neki kipróbálni, de szerintem a snapshot volume-al kapcsolatban annyi megkötés van, hogy ugyanazon a VG-n kell lennie.
Tehát lehet egy adott VG-ben tükrözött device és sima redundancia nélküli is. Azt, hogy melyik LV (akár a snapshot is) hova kerüljön azt ha minden igaz te mondod meg.
- A hozzászóláshoz be kell jelentkezni
Tehát lehet egy adott VG-ben tükrözött device és sima redundancia nélküli is. Azt, hogy melyik LV (akár a snapshot is) hova kerüljön azt ha minden igaz te mondod meg.
Az van, hogy per LV tudod megmondani, hogy hány mirrort kérsz hozzá (alapból ugye -m 0, tehát nincs tükör, de mondhatsz -m 1-et, és akkor lesz tükör). Namost a snapshot, az olyan, mint az LV, de nem tudsz neki -m-et mondani, ergó sehogyse tudod megmondani, hogy a snapshot alá tükrözött terület kerüljön az LVM-en belül. Sem a base LV tükrözési paraméterét nem örökli, sem pedig mondani nem tudsz neki semmi ilyesmit. Az eredmény az egy nem tükrözött snapshot lesz.
- A hozzászóláshoz be kell jelentkezni
Amit most leírtál azt értettem már az előbb is, valószínűleg én fogalmaztam pontatlanul.
Tehát egy VG-ben több device (PV ebben az esetben) is lehet, tehát lehet benne tükrözött és nem tükrözött device is.
Az LV-t meg arra rakod amelyikre akarod. A tükrözésről nem az LVM gondoskodik ebben az esetben, hanem akármi (hardware raid, md).
Tehát megmondhatod, hogy a snapshot-ot xy device-ra akarod létrehozni, ami adott esetben tükrözött.
Ha minden igaz ez így van, de most nem akarom ezt kipróbálni, szal fixme.
- A hozzászóláshoz be kell jelentkezni
Igazad van, ezt írtam az első két opcióban (HW RAID vagy MD), aminek a rugalmatlansága a buktája (nem tudom eldönteni full dinamikusan, hogy mi legyen tükrözve, és mi ne, plusz a resync diszk/partíció szintű, nem pedig LV/adat szintű).
- A hozzászóláshoz be kell jelentkezni
Tippre nem. Meglepo mondon, Debian GNU/kFreeBSD-t hasznalnak a fejlesztokon kivul masok is (fokent ZFS miatt).
--
|8]
- A hozzászóláshoz be kell jelentkezni