Ugyanabból a stringből mindig ugyanazt, de mégis legyen userenként egyedi. Aztán dobja vissza vágólapra, azonnali beillesztésre. Ez így alkalmazásoktól függetlenül, rendszerszinten használható. Sőt igazából géptől is független, hiszen nincs tárolás. Csak a scriptet kell letölteni a gépekre.
Az "ugyanarra mindig ugyanazt, de mégis mindenkinél mást" koncepcióra pont jó egy "sózott" hash. Viszont a hash-ekben csak számok és kisbetűk vannak. Tehát base64-be vele. Ezzel meg is van az alap:
PASS="$STR""::""`cat /path/to/salt 2>/dev/null`"
printf "%s" "`printf \"%s\" \"$PASS\" | sha1deep | base64`"(Azért az sha1-re esett a választás, mert az 40 karakter hosszú, azaz base64-be csomagolva 55 karakter lenne, amit a base64 ki fog paddingelni egy darab egyenlőségjellel, így tehát tuti lesz írásjel is a jelszóban. Lehetett volna sha256 is, úgy is paddingelődik, de mi a francnak olyan hosszú jelszó...de ha valakinek az kell, átírhatja.)
Akkor jöhet a többi, kezdjük a vágólappal.
Parancssorból vágólapot az xsel-lel, vagy az xclip-pel lehet kezelni. (Én legalábbis ezeket ismerem.) Előbbiben a vágólapra írás az
printf "%s" "$STR" | xsel -b -iaz onnan olvasás pedig
STR=`xsel -b -o`míg utóbbiban ezek
printf "%s" "$STR" | xclip -selection clipboard -iés
STR=`xclip -selection clipboard -o`.
Ha szeretnénk, hogy bármelyiket használni tudja a script, akkor először is el kell dönteni, hogy melyik van (ha egyik sem, akkor report és kiszállás),
if [ "`command -v xsel`" != "" ];
then
USE_XSEL=1
else
if [ "`command -v xclip`" != "" ];
then
USE_XSEL=0
else
echo 'Please install "xsel" or "xclip".' >&2
exit 1
fi
fiaztán pedig kell két wrapper az írásra és az olvasásra.
toclipb()
{
if [ "$USE_XSEL" = "1" ];
then
printf "%s" "$1" | xsel -b -i
else
printf "%s" "$1" | xclip -selection clipboard -i
fi
}
fromclipb()
{
if [ "$USE_XSEL" = "1" ];
then
xsel -b -o
else
xclip -selection clipboard -o
fi
}És akkor a fenti alappélda erre módosul:
PASS="$STR""::""`cat /path/to/salt 2>/dev/null`"
toclipb "`printf \"%s\" \"$PASS\" | sha1deep | base64`"És a$STR tartalma pedig így áll elő:
STR="`fromclipb`"Így az ember csak kicopyzza a domainnevet, lenyomja a hotkey-t és a vágólapra visszakerül a jelszó. Baj csak akkor van, ha több accountja is van ugyanarra a domainre. Ilyenkor van az, hogy be kell kérni a stringet, azaz fel kell dobni egy ablakot, ahol a user az account nevét és a domaint tudja gyorsan begépelni (user@domain) pl.: "trécéhá@apech.hu" (Ez persze nem szükséges, hogy ilyen formátumban történjen, ez csak egyértelműsítés; aki meg tudja jegyezni, hogy a "sugárhajtású dízelmozdony" string jelenti Gipsz Jakabot a twitteren, a "lánctalpas jegesmedve" meg Ó Lajost a tecsőn, az nyugodtan firkáljon be amit akar...)
CLI-ből felugratni egy ablakot és bekérni egy stringet én kétféleképpen tudok. Egyfelől a Zenity nevű parancssori dialóguskezelővel (utolsó GTK2-es verzió itt, elméletileg BSD-k és Solaris alatt is megy), másfelől meg egy terminálablakot felugratva és egy read parancsot végrehajtatva, az eredményt pedig fájlba kiíratva.
A Zenity kb. egy sor:
STR="`zenity --entry --text=\"Enter user@domain:\"`"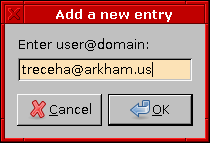
A terminálos már kissé kavarósabb:
TMP_REPLY="`mktemp`"
TMP_CMD="`mktemp`"
echo "#!/bin/sh" > "$TMP_CMD"
echo "printf \"%s\" \"Enter user@domain: \" && read REPLY && printf \"%s\" \"\$REPLY\" >""$TMP_REPLY" >> "$TMP_CMD"
chmod +x "$TMP_CMD"
CMD="$TERM"" -e ""$TMP_CMD"
eval $CMD
STR="`cat \"$TMP_REPLY\"`"
rm "$TMP_REPLY"
rm "$TMP_CMD"Amint lehet látni a terminált a $TERM változóból szedi és -e opcióval adja át neki a parancsot. Legjobb tudomásom szerint ez hurcolható (legalábbis az xterm, a dtterm, az Eterm, a konsole, az lxterminal és a gnome-terminal is ismeri...több terminált meg most lusta voltam megnézni), úgyhogy elvileg mindegy, milyen terminált használ az ember.
(Ezt a részt egyébként a Solaris 10 miatt kellett ennyire megtekerni, FreeBSD és Linux alatt ez feleennyi sorból megvolt és nem kellett külön futtatandó állomány sem, de Solaris alatt bereklamált, hogy Can't execvp akármi, így viszont ment...persze lehet, hogy csak én vagyok béna.)

Tesztelni teszteltem Linux/Trinity alatt xterm-mel, Eterm-mel és konsole-lal, FreeBSD/LXDE alatt lxterminal-lal és xterm-mel, valamint Solaris 10 alatt mind JDS, mind CDE alatt xterm-mel, dtterm-mel és a tököm tudja minek hívják a JDS alap terminálját, de azzal is. (Ja, most nézem, az a gnome-terminal...na, akkor megvan az egész banda.) Működött mindenütt.
Mivel nem biztos, hogy Zenity meg GTK2 mindenütt van, jó ha ez a terminálos felállás az alap, a Zenity-t tegyük markerfüggővé. (Meg persze attól is függővé, hogy van-e.) Végül, ha szeretnénk, hogy lehessen vágólapról is, meg bekérve is megadni a stringet, akkor legyen mondjuk az, hogy ha átadunk a scriptnek valamilyen paramétert (akármit), akkor vágólap, különben meg bekéri:
if [ "$1" != "" ];
then
STR="`fromclipb`"
else
if [ -f "/path/to/zenity-marker" ] && [ "`command -v zenity`" != "" ];
then
STR="`zenity --entry --text=\"Enter user@domain:\"`"
else
TMP_REPLY="`mktemp`"
TMP_CMD="`mktemp`"
echo "#!/bin/sh" > "$TMP_CMD"
echo "printf \"%s\" \"Enter user@domain: \" && read REPLY && printf \"%s\" \"\$REPLY\" >""$TMP_REPLY" >> "$TMP_CMD"
chmod +x "$TMP_CMD"
CMD="$TERM"" -e ""$TMP_CMD"
eval $CMD
STR="`cat \"$TMP_REPLY\"`"
rm "$TMP_REPLY"
rm "$TMP_CMD"
fi
fiA komplett script itt érhető el: http://oscomp.hu/?details/MakePass_(CP)_1559
Használata mint kiveséztük: mindenki a kedvenc hotkey kezelőjében belőheti a megfelelő hotkeyre, hogy
makepass, ha bekéretni akar, vagy
makepass akármi, ha a vágólapra másolt szövegből akarja a jelszót csinálni és utána visszakapja a jelszót a vágólapra.
A salt-ot belőni így lehet:
printf "%s" "ezittenasalt" > ~/.makepass.saltHa pedig van Zenity és használni is akarjuk, akkor
touch ~/.makepass.use_zenityNem tudom, hogy ilyesfajta megoldás volt-e már a "piacon" (mármint így 100%-ig script-ben írt, hotkeyre illesztve előcsalható), mert nem néztem utána, de ha igen, akkor most van még egy. Mindegy, poénnak jó volt. (Meg hátha jó lesz valakinek.)
- TCH blogja
- A hozzászóláshoz be kell jelentkezni
- 1589 megtekintés
Hozzászólások
Kicsit off, de az ami a correct horse battery staple linken van az azért eléggé fél igazság.
So 4 common dictionary words used as a password, such as correcthorsebatterystaple, offers around 5,000 to the power of 4 combinations , or around 6×10^14. EDIT: We’re not sure how XKCD got to 2^44, as a brute force of that would take a maximum of around 2 x 10^35 attempts, which we think was the point he was trying to make.
Ugye 2048^4 = (2^11)^4 = 2^(11*4) = 2^44, nem olyan bonyolult az.
Given the fastest GPU crackers are now working at around 7 Tera hashes per second, that hash will take around 1.5 minutes to crack.
Én nem tudom hogy milyen hashre gondol, de az itteni 8x 1080 benchmark szerint ha MD4-el(!) hashelt passwordöt próbálsz feltörni akkor 8 GTX 1080-al 350GH/s sebességgel megy, a 7TH/s-hez 160 GPU kell.
Egyébként password hashelésre direkt lassú hasht, mondjuk PBKDF2-t illik használni, amiből a benchmarkon a leggyorsabb is 80 MH/s-el működik, ami kb 4000-szer lassabb. A PBKDF2-t meg lehet paraméterezni ennél sokkal lassabbra is.
Az egész correct horse battery staple lényege hogy erősebb mint egy 11 karakteres random jelszó, de azzal ellentétben könnyű megjegyezni. Ami a te esetedben mondjuk tökmindegy, merthogy copypastelve lesz úgyis.
- A hozzászóláshoz be kell jelentkezni
Én azt hiszem kicsit félreértetted a dolgot, hogy mi a baj a correct horse battery staple felállással: ezek szavak, azaz egy szótáralapú támadásnál matematikailag tkp. karakterekké (pontosabban egységekké) degradálódnak. Van egy szótárad, ami tartalmazza a szavakat aardvark-tól zyzzyva-ig és ezeken iterál végig és gyártja a hash-eket, mint ha betűkkel csinálná ugyanezt. Mivel ez négy szó, ezért tkp. négy karakternek felel meg, mert szavanként pakolja össze a dolgot, ezért egy 4 szavas password, ha 5000 szóval számolunk, az 50004, azaz 6.25×1014 lehetőség. Ehhez képest egy pl. 11 karakteres jelszó, amiben van kisbetű, nagybetű, szám és írásjel is (azaz kb. 32-től 126-ig minden), az 9511, azaz kb. 5.688×1021 lehetőség. Ergo a 4 szavas "correcthorsebatterystaple" egyáltalán nem erősebb, mint a 11 karakteres "Tr0ub4dor&3".
Az én esetemben egyébként nem csak a copypaste miatt tök mindegy, hanem azért is, mert ez 56 karakter hosszú. :) Igaz, ebből az egyenlőség lejön, mert az mindig a végén van, vagyis egy
makepassáltal előállított jelszó az 6455, azaz alaphangon ~2.2×1099 lehetőség. Én aszondom, fair enough. (De ha valaki kevesli, lehet sha256-ot, meg még hosszabb hash-eket csinálni; pl. Whirlpool-lal már 172 karakteres lesz a kimenet => 64172=4.6×10310) És mivel tárolás nincs, lopásra sincs lehetőség, nem csak az elfelejtésére. (Kivéve, ha elfelejted, hogy mi volt a userneved. Dehát tökéletes megoldás nincs...)
- A hozzászóláshoz be kell jelentkezni
Az hogy a random 11 szavas jobb mint a 4 szavas jelszó az abszolút igaz, nem randomot kellett volna írnom.
De nem random jelszóról van szó a comicban, hanem hogy egy létező szóból gyakori módosításokkal kitalált jelszóról.
A random jobb, csak nehéz megjegyezni.
A "Tr0ub4dor&3" nem random (ott van a comicban hogy hogy generálódótt) ezért jobb nála a correcthorsebatterystaple.
Amúgy 5000 szavas szótárnál 6 szó kell hogy erősebb legyen mint a 11 karakteres random, és szerintem könnyebb megjegyezni, billentyűzeten begépelni mondjuk már nem biztos.
- A hozzászóláshoz be kell jelentkezni
> A "Tr0ub4dor&3" nem random (ott van a comicban hogy hogy generálódótt) ezért jobb nála a correcthorsebatterystaple.
Annyira garbage, hogy nem sok különbözteti meg a véletlentől.
> Amúgy 5000 szavas szótárnál 6 szó kell hogy erősebb legyen mint a 11 karakteres random, és szerintem könnyebb megjegyezni, billentyűzeten begépelni mondjuk már nem biztos.
Igen és akkor a 11 karaktereshez hozzácsapunk még egy karaktert és máris megint erősebb. Egy idő után eljut az ember oda, hogy hiába nehezebb megjegyezni a karakterest, ha a másikat fél óra beírni. Mert ugye arról beszélünk, hogy a jelszavakat fejben tároljuk; ha jelszókezelőnk lenne, akkor tök mindegy, hogy milyen hosszú, vagy bonyolult a jelszó.
- A hozzászóláshoz be kell jelentkezni
Hogy ne kelljen manuálisan kopizgatni az aktuális url-t: firefoxra.
Választás: ha korlátozott listából lehet (kell) választani, akkor esetleg a dmenu vagy a rofi (vagy hasonló) nem rossz ötlet.
- A hozzászóláshoz be kell jelentkezni
- A hozzászóláshoz be kell jelentkezni
Viszont a suckless team sem mentes a suckage-től
Van azért itt-ott elborulás :)
- A hozzászóláshoz be kell jelentkezni
Mondjuk az itt felsoroltak azért elsöprő többségükben megállják a helyüket.
- A hozzászóláshoz be kell jelentkezni
Ezt nem is vitattam, inkább arra gondolok, hogy
- sokszor egy egyszerű Makefile nem elegendő, szükség lehet különböző feltételekre, ciklusra, stb. A szabvány szerint ilyenek a make-ben nincsenek. Persze meg lehet oldani különböző szkriptekkel, meg kétszeri make-hívással, stb., de praktikus, ha a build-rendszer ad erre közvetlenül lehetőséget. Természetesen ez nem azt jelenti, hogy egy egyszerű projekt (néhány C-fájl lefordítása, mindenféle trükkök nélkül) esetén helyesnek tartom mindenféle hype-build-rendszer használatát (akár egy ötször annyi ideig futó "autohell"-es
./configure-t is ideértek) - a subversion-os rész tárgyi tévedést tartalmaz (cow hiánya), ezért "sucks", a többi része szerintem szubjektív mintsem objektív vélemény
- egy konkrét ablakkezelőhöz írt szoftver (pl. "trash icon programs") miért lesz "sucks", ha a konkrét ablakkezelő által nyújtott plusz funkciókat kihasználja
- nem tudom (értsd: nemigen értek hozzá), hogy ha valami C++-ban íródott, mennyire "sucks" (nekem úgy jön le, hogy ez már egy rossz pont)
- A hozzászóláshoz be kell jelentkezni
> sokszor egy egyszerű Makefile nem elegendő, szükség lehet különböző feltételekre, ciklusra, stb. A szabvány szerint ilyenek a make-ben nincsenek. Persze meg lehet oldani különböző szkriptekkel, meg kétszeri make-hívással, stb., de praktikus, ha a build-rendszer ad erre közvetlenül lehetőséget. Természetesen ez nem azt jelenti, hogy egy egyszerű projekt (néhány C-fájl lefordítása, mindenféle trükkök nélkül) esetén helyesnek tartom mindenféle hype-build-rendszer használatát (akár egy ötször annyi ideig futó "autohell"-es ./configure-t is ideértek)
Részben egyetértek (
./configure), részben meg nagyon nem (build system).
IMHO a generalizált build system alapvetően egy rossz megközelítés, mert abból - kis rosszindulattal - kb. kétféle kategóriájú van. Az egyikbe tartoznak a fapadosak, mint a
make, meg az
mk, amik ugyan mentesek az agyhalál kategóriás függőségektől és megoldásoktól, mert tényleg csak annyit csinálnak, amennyit kell, viszont ahogy mondtad is, a bonyolultabb összefüggéseket nemigen lehet velük megoldani, jöhet a
./configure, ami vagy jól van összerakva, vagy nem, de leginkább nem (a pkg-configgal és hasonló retardált függőségkezelésekkel, stb.). A másikba pedig ezek az "univerzális" szörnyetegek, amik jellemzően több problémát kreálnak, mint amennyit megoldanak. Lassúak, bugosak, iszonyatosan bloatedek, hozzák magukkal a saját agyhalott függőségkezelésüket és az eredeti célt, hogy egyszerűbben buildeljünk, végül nem sikerül elérni, mert csak sokkal bonyolultabb lesz az egész és a végén már messze többet szopsz a rohadt buildsystemmel, mint nélküle. Ezek a rendszerek mindent meg akarnak oldani, mindent tudni akarnak, mindent is, ami lehetetlen és ennek megfelelően a saját dugájába dől a végén az egész koncepció. A
cmakeegyébként még hagyján, mert az csak simán szar, de ott a
waf,
scons, vagy a "kedvencem", a
meson, na azokat tényleg emberiségellenes bűncselekménynek kellene minősíteni. (Ahogy a Pythont is.) Csak önmagában a Python egy külön "kis" dependency hell-t jelent: egyrészt az egyik program buildeléséhez x.y verziójú Python kell (még mindig C/C++ források buildeléséről beszélünk), a másiknak x.y-2, a harmadiknak x.y+3; aztán ott vannak a különféle "subsystemeik", mint pl. a
meson-nál az az átokverte
ninja, amik a másik felét jelentik ennek a bizonyos Pythonos dephellnek, amiknek egy raklapnyi Pythonos "keretrendszer" kell, hogy futni tudjanak. Komolyan, gyorsabban elkészül az ember, ha fejben ártírja a C kódot assemblyre és nekiereszt egy assemblert, mint mire összereszeli ezt az óriáskígyókból összehányt spagettihalmot...
Na, ennek megfelelően az a megoldás, ami ténylegesen univerzálisan alkalmazható, az az, hogy írsz egy buildscriptet, ez ugyanis nem egy generalizált fos lesz, ami vagy jó a programodhoz, vagy leginkább nem, de azért ráerőlteted, hanem pontosan a programodhoz lesz szabva. Nem kellenek buildsystemek, de még makefile-ok sem; a scripted pontosan azt fogja csinálni, amit kell, azt, amit akartál, azt amit mondtál neki. És a buildscript az egyetlen, ami ténylegesen dependencyless, legalábbis az épeszűség keretein belül, hiszen shellnek és fordítónak mindenképpen lennie kell, különben amúgy sem fordítasz. (Oké, a
make, vagy az
mknem egy olyan kategóriájú függőség, amibe bele kell halni, de nem biztos, hogy az alaprendszer tartalmazza.) Igen, ez azzal jár, hogy akkor kell egy
shscript UNIX-ok alá, meg batchfile wincrap alá, meg mindenhova olyan, amilyen shell van, dehát a jó munkához idő kell. De egyébként meg, ha konzekvensen gondolkodik az ember, akkor előbb-utóbb amúgyis kialakítja magának a saját kis scriptalapú buildkörnyezetét, viszont nincs dephell, mert a buildscriptek ott vannak a forrásban, tehát a buildsystem - ha úgy tetszik - teljesen bundled. Nem függesz semmilyen külső szartól.
(És itt jegyezném meg zárójelben, hogy a sokak által lesajnált, állítólag elavult Pascal ökoszisztémát ezek a problémák marginálisan, vagy sehogy sem érintik; a komplex programok fordítási sebessége a sokszorosa a C/C++-nál tapasztaltnak, nincsen szükség hatvannyócezerféle függőségkezelésre, meg build systemre, ami mind máshogy szar, hanem elég a fordító, meg a különféle include directory-k. Persze igazság szerint ez C/C++ alatt is mehetne így (sőt, régen így is ment), de az ottani kúltúra egy sok másféle ökoszisztémát épített ki.)
> a subversion-os rész tárgyi tévedést tartalmaz (cow hiánya), ezért "sucks", a többi része szerintem szubjektív mintsem objektív vélemény
SVN-be nem másztam bele annyira, így ezt a részt - hozzáértés híján - inkább nem kommentálnám. Viszont azt furcsállom, hogy a Gitet ajánlják helyette alternatívának, amikor azért annak is van egy vagon marhasága... (#1, #2)
> egy konkrét ablakkezelőhöz írt szoftver (pl. "trash icon programs") miért lesz "sucks", ha a konkrét ablakkezelő által nyújtott plusz funkciókat kihasználja
Bocsánat, ők nem ezt írták. Azt írták, hogy az a "sucks", ami csak akkor működik rendesen, ha ezek a plusz funkciók elérhetőek. Senki nem mondta, hogy nem lehet opcionálisan használni őket, ha elérhetőek.
> nem tudom (értsd: nemigen értek hozzá), hogy ha valami C++-ban íródott, mennyire "sucks" (nekem úgy jön le, hogy ez már egy rossz pont)
A C++-t a szintaxisa miatt szeretik utálni, illetve manapság még a C++ ökoszisztémához társuló elbaszott függőségek és heavy-weighted framework-ök miatt is. (Pl. Qt5.) A szintaxis szeretete/utálata ízlés kérdése (én sem szeretem, de nem kapok tőle sikítófrászt, mint a Pythontól), a többi meg ugyan jogos, de nem konkrétan a nyelv hibája, hanem a körészerveződött közösség kúltúrájáé. Ami a CLang-ot illeti, kell hozzá
cmakeés Python is, hogy lebuildeljük. Ez azért bőven elég ahhoz, hogy a CLang buildelhetőségét a "sucks" jelzővel illessük. A GCC-nek meg Perl kell, az is rated WTF.
Viszont, hogy azért nézzük meg az érem másik oldalát is: a suckless brigád által javasolt TCC ugyan impozáns fordítási sebességgel bír, de egy fordítónál nem csak az számít, hogy ő maga milyen gyors a forgatásban, hanem az is, hogy milyen gyors lesz az, amit forgat és ez azért árnyalja kicsit a képet. Aztán ott van még a támogatott CPU-k kérdése is: a TCC x86 (és talán ARM) only, míg a CLang és a GCC egy tonna CPU-t támogat. OS-ek tózse, a TCC a saját doksija szerint Linux és windows only, míg a másik két fordító szinte minden platformon elérhető (főleg a GCC).
Egyszóval hiába van jól megírva a TCC és hiába nincsenek agyfasz függőségei, ha a felhasználhatósága erősen korlátozva van pár specifikus területre. Ezen adott feladatokra (ld. pár példát a linkelt wiki cikkben) céleszköznek pont jó, de drop-in replacementnek a GCC vagy a CLang helyére nem alkalmas, legyen bármekkora trágyahalom is az utóbbi kettő. (Egyébként tapasztalataim szerint usage és result szempontból a CLang egészen tűrhető, csak leforgatnod ne kelljen, mert jaj.)
- A hozzászóláshoz be kell jelentkezni
Részben egyetértek (./configure), részben meg nagyon nem (build system).
Szerintem kicsit félreértesz, nem egészen erre gondoltam, hogy jó lenne.
Inkább arra, hogy a Makefile (vagy valami olyasmi) nem "csak" annyiból állna, amit a szabvány leír, hanem lennének plusz "nyelvi" lehetőségei - mint ahogy a GNU is megcsinálta a maga make-jét (ami elvileg minden szabványos Makefile-t szabvány szerint értelmez, és ezt egészítette ki néhány okossággal), meg pl. a BSD (FreeBSD) make is megeszi a szabványt, viszont abban is van for-ciklus, if-else-lehetőség, string-manipuláció, stb. Azaz nem mindenféle plusz teszteket hívogasson (pl. ./configure), hanem több nyelvi lehetőség lehetne benne. Pl. a saját statikus honlapgenerátoromban is igen jól jött, hogy van lehetőség for-ciklusra.
Viszont azt furcsállom, hogy a Gitet ajánlják helyette alternatívának
Igen, ezt én is, miközben úgy tapasztalom, hogy a "(hangadóbb) konzervatívabbak" nemigen vannak a git-tel kibékülve (az svn-es tévedést épp a linkelt honlap 2. állítása cáfolja).
Azt írták, hogy az a "sucks", ami csak akkor működik rendesen, ha ezek a plusz funkciók elérhetőek.
Én is így értettem. Értem, hogy szívás, de ettől szerintem még a szoftver lehet korrekt és jól megírt, csak a felhasználási környezete (dokumentáltan) megszabott (mint ahogy lentebb írtad a TCC-t).
- A hozzászóláshoz be kell jelentkezni
> Inkább arra, hogy a Makefile (vagy valami olyasmi) nem "csak" annyiból állna, amit a szabvány leír, hanem lennének plusz "nyelvi" lehetőségei - mint ahogy a GNU is megcsinálta a maga make-jét (ami elvileg minden szabványos Makefile-t szabvány szerint értelmez, és ezt egészítette ki néhány okossággal), meg pl. a BSD (FreeBSD) make is megeszi a szabványt, viszont abban is van for-ciklus, if-else-lehetőség, string-manipuláció, stb. Azaz nem mindenféle plusz teszteket hívogasson (pl.
./configure), hanem több nyelvi lehetőség lehetne benne.
Nem értek egyet. Két okból is.
Egyfelől ez akár egy bloatbuild system történetének kezdete is lehetne: a
makenem tud eleget, ezért ki "kell" bővíteni; apróságokkal indul a dolog, mint alap programozási dolgok, elágazások, ciklusok és alapvetően ezzel talán még nem is lenne akkora baj, csak úgyis lesz, akinek ez kevés lesz, aztán mindig minden kevés lesz, mert XY problémát még nem lehet benne megoldani és ez oda vezet, hogy egyre több minden lesz belezsúfolva, minek következtében egyre nehezebb lesz az alap környezettel megoldani és akkor jön az, hogy akkor írjuk át C++-ra, vagy rosszabb esetben Pythonra az egészet... Hát nem, a
makeés társai pont azért jók, mert csak arra jók, amire kitalálták őket: az egyszerű buildre. Nem arra, hogy programozz benne. Ha a programod olyan bonyolult, hogy a fordítása maga is elég komplex ahhoz, hogy csak programozottan lehessen megoldani, akkor programozd le az aktuális rendszer shelljében a build folyamatot. Nincs univerzális build system, nem is lehet. Tudod, ami jó mindenre, az nem jó semmire.
A másik ami miatt nem értek egyet, az pont a GNUMake. Rettenetesen tudok "örülni", amikor kiderül egy
Makefile-ról, hogy ez nem is Makefile, hanem GNUMakefile. Ez persze Linux alatt nem gond, mert ott alapból az van
makehelyett, de pl. Solaris alatt már külön kell telepíteni (
gmakenéven és akkor kezdődik a symlinkekkel való rettenetes gányolás) és akkor még nem is beszéltünk azokról az egyéb platformokról, ahol esetleg egyáltalán nincs ilyen. Nem arról van szó, hogy a GNUMake extra feature-jei ne lennének hasznosak, vagy arról, hogy attól a pár szerencsétlen
if-től, meg
for-tól már bloated lenne, hanem arról, hogy ez minden csak nem hordozható; látszólag csak egy
Makefilevan, de aztán kiderül, hogy ez rohadtul GNU-dependens, azaz a portabilitást sikerült vele jól seggberakni, ez már nem crossplatform. A Make az Make, az mindenütt ugyanaz, mert nem lehet más: a POSIX leírja, hogy mit kell tudnia. Ez a lényege. Ettől lesz hordozható. Ha ettől eltérsz, lábonlövöd vele a forrásod hordozhatóságát. Megint csak azt tudom mondani, hogy ha egyéni igényeid vannak, akkor azt programozd le a rendszer shelljében. Az is hordozható. Shell mindenütt van, még AmigaDOS, vagy MS-DOS alatt is. Ha valami nagyon kell: csináld magad és ne függj mindenféle Linux és/vagy GNU-dependens vacaktól. (A Python-dependens kulatengerekről meg inkább ne is beszéljünk...)
> Pl. a saját statikus honlapgenerátoromban is igen jól jött, hogy van lehetőség for-ciklusra.
A honlapod egyébként kurwa jó, nekem nagyon bejön. :) Főleg az, hogy nincs JS. (De a saját programok még mindig 404, az két év óta még mindig WIP? :) )
Viszont azért ne keverjük össze egy személyes honlap makróalapú felépítését, komplex C/C++ projektek buildelésével, mert nem ugyanaz a kategória.
> Én is így értettem. Értem, hogy szívás, de ettől szerintem még a szoftver lehet korrekt és jól megírt, csak a felhasználási környezete (dokumentáltan) megszabott (mint ahogy lentebb írtad a TCC-t).
Hát azért van egy kis különbség a C fordítóktól elvárt minimumot simán teljesítő TCC és egy az ICCCM szabványt leszaró, WM-dependens program között. :) Az utóbbi egészen pontosan hogyan is lehetne korrekt és jól megírt, ha egyfelől szembemegy a direkt az egységesség kedvéért lefektetett protokollal, mert ő jobban tudja, másfelől meg csak egy WM alatt megy? Nem, akkor lehetne korrekt és jól megírt, ha ICCCM compliant lenne, ahogy az elvárható és minden WM alatt menne, ahogyan az elvárható, de ez mellett ki tudná használni a "szívügy" WM cuccait. A "megyek mindenütt, de XY alatt jobban/gyorsabban", az oké, a "csak XY alatt megyek", az nem oké. Ez a különbség. A TCC-nél nem elvárás, hogy mindenben jobb legyen, mint a GCC, vagy a CLang. Az az elvárás, hogy C-t tudjon fordítani és ezt tudja is.
- A hozzászóláshoz be kell jelentkezni
Egyfelől ez akár egy bloatbuild system történetének kezdete is lehetne
Igen, a nyújtott kisujj és a kar esete, gondolom, ezek vezettek mindenféle build-framework fejlesztésekhez. Viszont ahogy írod is, egy kis if meg for-támogatás (na, meg egy kis sztring-manipuláció) a Makefile-ba talán nem annyira "bloat".
gmake néven és akkor kezdődik a symlinkekkel való rettenetes gányolás
Miért kell szimlinkelni? Ha a GNUMakefile jól van megírva, akkor a $(MAKE) parancsot használja a következő szintű make-hez, azaz a gmake parancsra le kellene rendesen fordulnia.
ha egyéni igényeid vannak, akkor azt programozd le a rendszer shelljében
Viszont ha van egy olyan keret, ami ezeket támogatja, miért ne használhatnád? Mint ahogy én sem ragaszkodtam a szabványhoz, hanem kihasználtam a plusz lehetőségeket, ezáltal kisebb az én kódom, másrészt nagyobb része (a BSD-make bővített készlete) széles körben tesztelt, azaz kevesebb a hiba lehetősége. Ennyi erővel a make is bloat, mert azért nem olyan nehéz egy szkriptet összedobni, ami legenerálja a dolgokat :)
Azaz: azt gondolom, hogy attól, hogy a POSIX-nál valami többet tud, nem feltétlen bloat.
A honlapod egyébként kurwa jó, nekem nagyon bejön.
Köszi :)
Saját programok még mindig 404
Semmi se hibamentes :(
ne keverjük össze egy személyes honlap makróalapú felépítését, komplex C/C++ projektek buildelésével, mert nem ugyanaz a kategória
Valóban nem. Viszont úgy gondolom, hogy a make arra lett kitalálva, hogy néhány fájlból meghatározott szabályok szerint új fájlt generáljon, amennyiben a kiindulási fájlok közül legalább egy újabb, mint a cél - azaz nem feltétlen csak C/C++ projektekre lehet használni.
minden WM alatt menne, ahogyan az elvárható, de ez mellett ki tudná használni a "szívügy" WM cuccait
Elismerem, így valóban korrektebb lenne.
- A hozzászóláshoz be kell jelentkezni
> Igen, a nyújtott kisujj és a kar esete, gondolom, ezek vezettek mindenféle build-framework fejlesztésekhez.
Pontosan.
> Viszont ahogy írod is, egy kis if meg for-támogatás (na, meg egy kis sztring-manipuláció) a Makefile-ba talán nem annyira "bloat".
Egyáltalán nem bloat, én nem is ezt írtam. A különféle Make derivánsokkal más baj van: a hordozhatóság lábonlövése.
> Miért kell szimlinkelni? Ha a GNUMakefile jól van megírva, akkor a
$(MAKE)parancsot használja a következő szintű
make-hez, azaz a
gmakeparancsra le kellene rendesen fordulnia.
Hát igen. Ha jól van megírva. Ha jól van megírva. De mi van, ha nincs? Mi van, ha csak be van írva, hogy
make, mert egy Linux-only gyökér a felelős érte és vagy nem tudja, vagy nem érdekli, hogy amit csinál, az nem hordozható?
> Viszont ha van egy olyan keret, ami ezeket támogatja, miért ne használhatnád? Mint ahogy én sem ragaszkodtam a szabványhoz, hanem kihasználtam a plusz lehetőségeket, ezáltal kisebb az én kódom, másrészt nagyobb része (a BSD-make bővített készlete) széles körben tesztelt, azaz kevesebb a hiba lehetősége.
Ez alap: ha neked jó, akkor nyugodtan használhatod. Mint mondtam, egy
makemég nem akkora agyhalál dependency; alapvetően a BSD/GNUMake sem az. Viszont akkor ez azzal jár, hogy a cuccod csak ott fog működni, ahol ez rendelkezésre áll.
> Ennyi erővel a make is bloat, mert azért nem olyan nehéz egy szkriptet összedobni, ami legenerálja a dolgokat :)
Ez már szókiforgatás. Én kerek perec leírtam, hogy a
make, de még a különféle kiterjesztett Make derivánsok sem bloatedek.
> Azaz: azt gondolom, hogy attól, hogy a POSIX-nál valami többet tud, nem feltétlen bloat.
De én nem is mondtam. Olvasd el még egyszer az odavágó kettes bekezdést, mert asszem nem ment át: a POSIX kiterjesztése nem ekvivalens ab ovo a bloattal; csak amennyiben a kiterjesztés függőségként jelenik meg valahol, akkor onnantól kezdve lőttek a hordozhatóságnak. Leegyszerűsítem: Ha egy adott projekt a "natúr" POSIX
makeparanccsal mondjuk öt percig fordul, a
bmakeparanccsal meg háromig, akkor itt a POSIX kiterjesztések kezelése jól van megvalósítva, mert működik a normál felállás mellett is, csak kihasználja az opcionális pluszokat. Viszont, ha a
makeparanccsal egyáltalán nem fordul, akkor ez nem kihasználja az opcionális pluszokat, hanem nem tud nélkülük élni. És ez a nem mindegy.
> Valóban nem. Viszont úgy gondolom, hogy a
makearra lett kitalálva, hogy néhány fájlból meghatározott szabályok szerint új fájlt generáljon, amennyiben a kiindulási fájlok közül legalább egy újabb, mint a cél - azaz nem feltétlen csak C/C++ projektekre lehet használni.
Nem hát, de én - megint csak - nem ezt mondtam. Én pontosan arról beszéltem, hogy ez a felállás nagyon faszán működhet egy makróalapú website-nál, de nem biztos, hogy egy hiperkomplex forráshalmaz buildelésére is jó lesz. Neked jó, mert erre a célra jó volt, de mindenre nem jó és nem is lesz. Nincs, ami mindenre jó. Csak megpróbálnak csinálni, de ez szükségszerűen mindig szar lesz. Neked most elég volt, valaki másnak már nem lesz és akkor
GOTO 10. (Aztán meg
GOTO 666, amikor jön a dependency-hell.)
- A hozzászóláshoz be kell jelentkezni
Mi van, ha csak be van írva, hogy make, mert egy Linux-only gyökér a felelős érte és vagy nem tudja, vagy nem érdekli, hogy amit csinál, az nem hordozható?
Egy kis sed-del kicserélni a Makefile-ban előforduló make parancsokat $(MAKE)-re? :)
Ez már szókiforgatás. Én kerek perec leírtam, hogy a make, de még a különféle kiterjesztett Make derivánsok sem bloatedek.
Akkor máshogy kérdem: minek kell a make, ha egyszerű shell-szkripttel is kiváltható a funkcionalitása? :)
Csak arra akarok kilyukadni, hogy egyszer az összetettebb build-framework-okre azt mondod, hogy írja meg szkriptben. De a te build-framework-ödet (make) miért ne kellene megírni inkább néhány sornyi szkripttel? Azaz elég szubjektív (és elmosódott) a határ.
Viszont, ha a make paranccsal egyáltalán nem fordul, akkor ez nem kihasználja az opcionális pluszokat, hanem nem tud nélkülük élni. És ez a nem mindegy.
Viszont mennyire lesz karbantartható a szoftver? Gondolkodtam én is a saját kis statikus CMS-emen, hogy esetleg valahogy lecsupaszítani, hogy tényleg csak az alap make-et használja, de nem tudom, hogy hogyan tudnám értelmesen. Volt olyan ötletem, hogy egy make legenerálja, hogy mik a targetek (és persze minden szabállyal, minden egyéb kellékkel), a következő make pedig ezt beolvassa, és felhasználja. Szóval inkább elvetettem, és a bmake függőség lett (ami FreeBSD-n alapból adott).
Nincs, ami mindenre jó.
Kivéve a kalmopyrin, mert az tényleg mindenre jó :D
- A hozzászóláshoz be kell jelentkezni
> Egy kis
sed-del kicserélni a
Makefile-ban előforduló
makeparancsokat
$(MAKE)-re? :)
Nem azt mondtam, hogy nem megoldható, hanem azt, hogy gányolni kell és ebből a szempontból mindegy, hogy symlink-spagettit csinálsz, vagy a
Makefile-ba túrsz bele. :P
> Akkor máshogy kérdem: minek kell a make, ha egyszerű shell-szkripttel is kiváltható a funkcionalitása? :)
Csak arra akarok kilyukadni, hogy egyszer az összetettebb build-framework-okre azt mondod, hogy írja meg szkriptben. De a te build-framework-ödet (make) miért ne kellene megírni inkább néhány sornyi szkripttel? Azaz elég szubjektív (és elmosódott) a határ.
Ja, értem már mire gondolsz. Nos, a válasz egyszerű: én nem is használom a
make-et sem a saját programjaimhoz, hanem megírom azt a pársoros (néha egysoros) buildscriptet, ami kell.
> Viszont mennyire lesz karbantartható a szoftver?
Az attól függ, hogy milyen megoldással csinálod.
> Gondolkodtam én is a saját kis statikus CMS-emen, hogy esetleg valahogy lecsupaszítani, hogy tényleg csak az alap make-et használja, de nem tudom, hogy hogyan tudnám értelmesen.
Scriptelve. :) Ez úgyis
make-> deploy megoldás, akkor meg ennyi erővel lehet scriptelni is amit szeretnél, nem?
> Volt olyan ötletem, hogy egy make legenerálja, hogy mik a targetek (és persze minden szabállyal, minden egyéb kellékkel), a következő make pedig ezt beolvassa, és felhasználja. Szóval inkább elvetettem, és a bmake függőség lett (ami FreeBSD-n alapból adott).
Ha nem is cél, hogy másutt is lehessen használni, mint BSD-ken, akkor ezzel nincs is baj. Viszont, ha pl. szeretnéd átvinni Solarisra, vagy Linuxra, akkor nem árt, ha van GNUMakefile is, nem csak BSDMakefile, ugyanis
bmakeLinuxon alapból, Solarison meg - tudtommal - egyáltalán nincs. Ha meg valami perverzió miatt windózra is kell, akkor
nmaketámogatást is kell csinálni.
- A hozzászóláshoz be kell jelentkezni
Scriptelve. :) Ez úgyis make -> deploy megoldás, akkor meg ennyi erővel lehet scriptelni is amit szeretnél, nem?
De minek, ha eleve adott egy jól működő eszköz, a make, amit ráadásul nem is kell telepíteni (az alaprendszer része). De egyébként igen, lehetne csak szkriptekkel is, meg persze lehetne az is, hogy mindent sed-del cserélgetek, és akkor még m4 se kellene :)
Viszont, ha pl. szeretnéd átvinni Solarisra, vagy Linuxra
Linuxra biztos nem, több, mint 10 évig Linux-használó voltam, hatodik éve FreeBSD, és nem is tervezem, hogy visszaváltsak Linuxra. Solarist meg életemben nem használtam, sőt, VPS-ekre látom, hogy Solaris telepíthető lenne.
Leginkább saját felhasználásra készült, viszont mivel publikus, más is használhatja, a függőségek rendesen dokumentálva vannak, úgy érzem.
Egyébként egy kicsit gondolkodtam, hogy mit nevezhetünk bloat-nak: úgy gondolom, hogy azt mindenféleképpen, ami több problémát okoz, mint amennyit megold (a problémák súlyozhatók, illetve a fejlesztési-telepítési-karabantartási időt illetve igényelt tárhelyet is a problémákhoz sorolva).
- A hozzászóláshoz be kell jelentkezni
> De minek, ha eleve adott egy jól működő eszköz, a
make, amit ráadásul nem is kell telepíteni (az alaprendszer része).
Erm...az megvan, hogy te kérdezted - illetve mondtad, hogy nem tudod - hogy hogyan kéne ezt megoldani GNU/BSDMake nélkül? Én csak arra válaszoltam. :P
> De egyébként igen, lehetne csak szkriptekkel is, meg persze lehetne az is, hogy mindent
sed-del cserélgetek, és akkor még
m4se kellene :)
Mondom: én a te kérdésedre válaszoltam, ha neked jó így, akkor jó. Célfeladatra céleszköz, tehát jó. Én egy szóval nem mondtam, hogy dobd ki a
make/
m4duót. Te kérdeztél rá pár dologra, én csak válaszoltam. Nem muszáj az én példámat követni és minden programhoz buildscriptet írni. (Hozzáteszem, hogy egyszerű programoknál ez egyébként kimerül kb. a compile/strip kétsorosban.)
> Linuxra biztos nem, több, mint 10 évig Linux-használó voltam, hatodik éve FreeBSD, és nem is tervezem, hogy visszaváltsak Linuxra. Solarist meg életemben nem használtam, sőt, VPS-ekre látom, hogy Solaris telepíthető lenne.
Leginkább saját felhasználásra készült, viszont mivel publikus, más is használhatja, a függőségek rendesen dokumentálva vannak, úgy érzem.
Nem arra gondoltam, hogy te akarnád használni Linux alatt, hanem arra, hogy pont azért, mivel publikus és más is használhatja, így előfordulhat, hogy valaki speciel pont egy Solarisos szerverre akarja feltenni és akkor bajban lesz.
> Egyébként egy kicsit gondolkodtam, hogy mit nevezhetünk bloat-nak: úgy gondolom, hogy azt mindenféleképpen, ami több problémát okoz, mint amennyit megold (a problémák súlyozhatók, illetve a fejlesztési-telepítési-karabantartási időt illetve igényelt tárhelyet is a problémákhoz sorolva).
Az elég jól le van írva, hogy mit nevezünk bloatnak: Bloat az, ha egy program verzióról-verzióra több erőforrást igényel, miközben semmivel, vagy csak szükségtelen dolgokkal tud többet az előzőeknél. Ez az, amit hajbazer szokott fejtegetni, csak nem szokták megérteni, vagy fennakadnak azon, hogy mi is számít hasznos újításnak, ami ugye azért eléggé szubjektív dolog bír lenni.
Amiről te beszélsz (meg amiről én is beszéltem kicsit fentebb), hogy több problémát kreál, mint amennyit megold, azt szolúcionizmusnak csúfolják, bár ez így elég pontatlan, mert ezt konkrétan arra szokták használni, amikor valakinek az a rögeszméje, hogy minden probléma megoldható valamelyik új technológiával, csak pont ezek az új technológiák csinálnak néha több szart, mint amit felszámolnak. (Pl.: shitsteamd)
- A hozzászóláshoz be kell jelentkezni
valaki speciel pont egy Solarisos szerverre akarja feltenni és akkor bajban lesz
Akkor nyit egy hibajegyet (az elsőt :) ), és majd valamit próbálok ártani neki :D
Bloat az, ha egy program verzióról-verzióra több erőforrást igényel, miközben semmivel, vagy csak szükségtelen dolgokkal tud többet az előzőeknél
Hm, érdekes. Tehát egy adott program első verziója nem lehet bloat? :)
- A hozzászóláshoz be kell jelentkezni
> Akkor nyit egy hibajegyet (az elsőt :) ), és majd valamit próbálok ártani neki :D
Asserossz. Bár a Linuxon/Solarison való használat problémája speciel huszárvágással orvosolható, ha a BSDMake mellett biztosítasz GNUMake-hez való
Makefile-t is, ha már ragaszkodsz ahhoz, hogy nem az alap
make. Nem tudom mennyire üt el a GNUMake és a BSDMake egymástól, de gondolom nem akkora meló. De ahogy gondolod.
> Hm, érdekes. Tehát egy adott program első verziója nem lehet bloat? :)
A "bloat" (felfúvódás) nem maga a szoftver, hanem a folyamat, amikor a szoftver felfúvódik. A szoftver maga az "bloated" (felfúvódott), vagy bloatware.
Ettől még a meglátás jogos, nyilván egy 1.0 is lehet bloatware, bár mondjuk én is bele bírnék kötni a kérdésedbe, hogy mit is értesz pontosan első verzió alatt: első kiadott verziót, vagy első commitot/mentést? Csak mert egy programnak - ha tényleg igazán szigorúan nézzük - az első verziója kb. onnan indul, hogy van egy db. üres
main()-ed és a következő internal verziók alatt pakolják bele a cuccokat. :P
Ilyen megközelítéssel simán áll, hogy mire eljutnak a kiadásig, belepakolhatnak egy csomó felesleges - a célokhoz semmi közzel nem bíró - szart, vagy a
printf("Hello bloated world!\n");szintű programot egy húsz rétegű keretrendszeren keresztül oldják meg; ez ugyanúgy menet közbeni felfúvódás, csak még kiadás előtt. :]
- A hozzászóláshoz be kell jelentkezni
Nem tudom mennyire üt el a GNUMake és a BSDMake egymástól
Viszonylag lényegesen. BSDMake esetében a for-loop targeten kívül van, így könnyen használható targetek dinamikus létrehozására, GNUMake esetében a targeten belül vagy értékadáskor lehet használni, targetek létrehozására kicsit nehézkes.
Sztring-manipulációk is mások, bár vannak átfedések.
A "bloat" (felfúvódás) nem maga a szoftver, hanem a folyamat
Belegondolva valóban lehet benne valami.
- A hozzászóláshoz be kell jelentkezni
A jelszókezelőt azért nem tudja kiváltani, mert abban nem csak a jelszó információ, de a username is. Például van ahol a usernevet nem választom hanem kapom: céges email, privát email, név kezdőbetűi (de hány karakter?), stb.
- A hozzászóláshoz be kell jelentkezni
Ez egyáltalán nem igaz. Ez egyetlen esetben nem tudja kiváltani a jelszókezelőt: ha a jelszót nem te határozod meg. De az usernév, vagy akármi, az teljesen irreleváns: azt írsz be a felugróba, amit akarsz; mint leírtam, ha tudod, hogy a "nejlonszatyorfejű rakétás kenguru" azt jelenti, hogy ez a céges jelszavad, akkor azt is beírhatod. Ez nem szükségszerűen domain/user => jelszó felállás: ez mnemonik => jelszó felállás.
- A hozzászóláshoz be kell jelentkezni
Szerintem asch arra gondolt, hogy sokszor a mnemonikot is nehez fejben tartani, ha sok van belole mondjuk, es ritkan kell oket hasznalni.
- A hozzászóláshoz be kell jelentkezni
Hát találjon ki olyat, amit könnyű megjegyezni; ezért volt a példa a
user@domain. Azt kellene megérteni, hogy irreleváns, hogy mik a valós hozzáférési adatok, mert azzal helyettesíted be, amivel akarod. Ha Jóska Pista, aki a Ronda Multi-Cégnél dolgozik, olyan hozzáférést kap, hogy "joska.pista_1977$28472827$@RondaMultiCeg.4p", akkor nem muszáj ezt a fasságot megjegyezni, beírhatja, hogy "a céges szarom" és ugyanúgy mindig ugyanazt a jelszót fogja kapni. Vagy ha vállalkozó és több céges hozzáférése is van, akkor "cegesfos@rmc", "cegesfos@mrmc", "cegesfos@emtnrmc", "cegesfos@vrmc", "cegesfos@ms". A lehetőségek végtelenek. Mnemonikot generálni is lehet fejben, nem csak tartani.
- A hozzászóláshoz be kell jelentkezni
> nem muszáj ezt a fasságot megjegyezni
De muszaj, szerintem itt pont az a felreertes, hogy a jelszokezelobe fel tudod irni a usernevet, ebbe meg nem. Ami a legtobb embernek nem feltetlenul problema, de engem pl. tobb esetben erint az asch altal leirt pelda.
_Valahova_ fel kell irnom, hogy "joska.pista_1977$28472827$@RondaMultiCeg.4p", ha nem a jelszokezelobe, akkor mashova.
szerk: konkret pelda, nekem van olyan helyre access, ahol a "usernev" egy szabvanyos UUID, max havi egyszer kell hasznalni, ugyhogy kb. eselytelen fejben tartani - a jelszokezelo viszont megoldja
- A hozzászóláshoz be kell jelentkezni
Ja, értem már, hogy mi a problémátok. Nos, ez nem is arra van kitalálva, hogy userneveket tároljon, hogy be tudjátok írni a loginformba. Viszont ott az uzsolt által javasolt
dmenu, lehet finomítani a dolgot.
- A hozzászóláshoz be kell jelentkezni
Tetszik az ötlet :)
--
arch,ubuntu,windows,android
zbook/elitebook/rpi3/motog4_athene
- A hozzászóláshoz be kell jelentkezni
Annak örülök.
- A hozzászóláshoz be kell jelentkezni
Nem lett volna egyszerűbb a LessPass-t hozzáigazítani a rendszeredhez? Van belőle cli kliens.
- A hozzászóláshoz be kell jelentkezni
Leírtam a cikkben: "Nem tudom, hogy ilyesfajta megoldás volt-e már a "piacon" (mármint így 100%-ig script-ben írt, hotkeyre illesztve előcsalható), mert nem néztem utána, de ha igen, akkor most van még egy. Mindegy, poénnak jó volt. (Meg hátha jó lesz valakinek.)"
- A hozzászóláshoz be kell jelentkezni
Hogyan változtatsz jelszót?
- A hozzászóláshoz be kell jelentkezni
Megváltoztatod a bemenetet.
- A hozzászóláshoz be kell jelentkezni
200 jelszónál egyszerre? Valami mappinget tudnék elképzelni.
--
HUP Firefox extension | Hupper hibajelentés
- A hozzászóláshoz be kell jelentkezni
200 jelszónál? Van egyáltalán olyan elképzelhető usercase, hogy egy embernek egyszerre kelljen megváltoztatnia 200 jelszavát?
- A hozzászóláshoz be kell jelentkezni
Nem hinném, de ha egy saltot használsz mindenre, akkor egyszerre 200 jelszót kellene megváltoztatni, ha az megváltozik.
--
HUP Firefox extension | Hupper hibajelentés
- A hozzászóláshoz be kell jelentkezni
De nem a saltot kell megváltoztatni, hanem a bemenetet, amit lekéréskor beadsz neki.
- A hozzászóláshoz be kell jelentkezni
Az nem a domain mondjuk?
Akkor talán így tudnám elképzelni:
case $STR in
hup.hu)
STR="$STR v1"
;;
esac
Így akkor lehet verziózni.
- A hozzászóláshoz be kell jelentkezni
Lehet az is, de nem szükségszerűen. Azt írsz be, amit akarsz. Pl. eredetileg volt
ajnasz@hupés utána lesz belőle
ajnasz@hup /new. Vagy bármi. Ez (tetszőleges) bemenetből csinál jelszót.
- A hozzászóláshoz be kell jelentkezni
Igen, de azt azert nehez eszben tartani minden sitenal jelszonal, hogy mi az extra salt. :)
- A hozzászóláshoz be kell jelentkezni
A salt globális. :P
~/.makepass.salt- A hozzászóláshoz be kell jelentkezni
Debian OpenSSL fiaskóra még emlékszel? Igaz akkor nem jelszavakat hanem certificate-eket kellett tömegesen lecserélni, de hasonlót el tudok képzelni hash algoritmussal is.
- A hozzászóláshoz be kell jelentkezni
Ha megszakadok se értem az összefüggést.
- A hozzászóláshoz be kell jelentkezni