Két hónapja ismerkedem az AI-val, tanfolyamon voltam (online), példa kódokat végigvettem, kipróbáltam. Közel 20 éve fejlesztek, de a mai napig érdekelnek az új dolgok, nodejs is megvan, HA proxy-t is láttam, nem ragadtam le a Delphi7-nél. Ezért is fogott meg ez az AI kérdés...
Szépen meg tudtam taníttatni a neurális hálózatnak a XOR kapu működését, ügyesen tudta alkalmazni a szabályt. Továbbmentem, a 4 féle XOR bemenetet nem csak 1x adtam meg neki, így nagyobb valószínűséggel adott jó(bb) választ (98% vs 90%), félre is tudtam vezetni. Megtaníttattam neki, hogy mely RGB bemenetekhez - amik háttérszínek - fekete vagy fehér betűvel kell rajzolni. Ügyesen választ FEK/FEH közül. Tanítottam neki szövegeket (SalesForce WikiText DB, 103millió sor), itt már izzadt rendesen (VT100 kártya kell neki, de minmum 2080i, akkor pár nap/hét alatt megtanulja), amelyekkel elvileg be tud fejezni egy 3 szóból álló kifejezést. Na puff!
A problémám több szintű:
- A fenti példák mindegyike algoritmizálható (RGB->gray, szöveg befejezés tokenizálható, FullText search-csel megoldható, sőt van rá céleszköz is)
- Normál algoritmusokkal azonnal látom, hogy jól működik-e, nem kell visszatesztelni és determinisztikus a kimenet.
- Minden bizonnyal az én látásmódom algoritmikus, nem látok ezen túl. De sem én nem tudok kitalálni, sem ügyfél oldalról nem jött olyan igény, amelyhez gépi tanulás kellene.
- Példaként hozták a Wizzair foglalási rendszerét, amit tanítottak és nem programoztak. De ott is hamar kiderült, hogy sok emberi tényezőt be kell építeni, felismerés helyett human-rules-ok kerültek alkalmazásra. És összességében 6 havonta tanítják a gépet, az is jó pár hétig tart. Ez egy többéves projekt: építése is, haszna is. És komoly önmarketing kell, hogy el tudd adni. Nem azonnali a siker.
- Vannak gépi tanulásra épített lib-ek, amelyek képeket ismernek fel vagy víruskeresőt/spam szűrőt okosítanak fel. De ezek kész dolgok.
- Beugrott a webáruházak ajánló rendszere (3 termék a kosárban, upsell-ben ad +2-t), de itt is a pattern alapján való becslés/folytatás (preceding AI-ban) megvalósítható rendelések alapján sql-lel is. Jó eredményt ad, sőt mivel nincs napi 10k rendelés, nincs valós "tanulni való".
Ti találkoztatok gépi tanulási feladattal, amely kis hazánkban értelmezhető és kísérletezhetnék rajta/vele/általa?
- 1358 megtekintés
Hozzászólások
Szia! Ezt az oldalt ismered? PyImageSearch - You can master Computer Vision, Deep Learning, and OpenCV.
- A hozzászóláshoz be kell jelentkezni
- Szerintem rosszul van feltéve a kérdés. Akinek csak kalapácsa van, az mindent szegnek néz.Nem, hiszem, hogy erőltetni kellene a gépi tanulás használatát, gyakran más eszközök is célhoz visznek, akár kisebb erőfeszítéssel is. Érdemesebb lenne azt nézni, hogy a napi feladatoknál valahol alkalmazható az MI, vagy sem; és erre elindulni.
- Legyek azért konstruktív is: pár napos a youtube videó, melyen már meglévő MI csomagok segítségével pillanatok alatt elkészül egy Alexa klón: https://github.com/ProgrammingHero1/romantic-alexa
Ha már úgyis nagy divatja van az otthon automatizálásának (a HUP-on is), meg lehetne próbálkozni azzal, hogy ugyanezt házon belül tartsa az ember, azaz ne építsen ezekre a külső könyvtárakra, hanem oldja meg saját maga beszédfelismerést. Kezdetben persze érdemes a szótárat eléggé lekorlátozni (pl. "konyha redőny fel"), és csak a családtagok hangjára betanítani.
AL
- A hozzászóláshoz be kell jelentkezni
2. Nincs új a nap alatt, a lib legfontosabb része hogy állandóan figyel és ezt használja: listener.recognize_google
- A hozzászóláshoz be kell jelentkezni
Ezért javasoltam kiváltani egy saját fejlesztéssel, hogy nem lépjen ki a rendszer a lakáson kívülre.
AL
- A hozzászóláshoz be kell jelentkezni
1. Az innováció lényege hogy nem csak kérdésre ad választ, hanem a kérdést is felteszi. Mert olyat ad amit nem mernél kérni. De valahogy mindig csak kalapácsot veszek kézbe. Mire való a fluxuskondenzator, amjt a kezemben tartok?
- A hozzászóláshoz be kell jelentkezni
Lehet kicsit összetettebb, mint a fentiek, de fizikai modellezéshez gondolkoztam, hogy hogyan lehetne ML-t használni.
Konkrétabban force directed gráf rajzolásához lenne jó egy jól betanított modell, mert sajnos a rendes szimuláció futásideje nagyon durván függ a node-ok számától. Jó lenne, ha az erők és hatások iteratív számolása helyett a ML modell tudna egy viszonylag helyes közelítést adni, így viszonylag egyszerűen lehetne nagy gráfokat is ábrázolni, akár realtime.
- A hozzászóláshoz be kell jelentkezni
nVidia bemutató? https://www.nvidia.com/en-us/about-nvidia/ai-computing/
- gépjárműipar
- önvezető autók
- drónok
- beszédfelismerés
- útvonaltervezés (dugók, balesetek kerülése)
- városirányítás
- "energiahálózatok"
- xy gyártás (robotok vezérlése, összehangolása)
régi filmek, képek (vagy kamerafelvételek) felújításánál pl a betűk/számok felismerés (rajzolása), arcfelismerés, arcrestaurálás, fantom kép rajzolás, bűnügyi kamera felvétel (3D) készítése
Lehet ezek vitatottak és vagy már léteznek is (ezeket mind folyamatosan tanulni kellene):
- Magyar turizmus app, turisták szórakozgatása, naprakész információ és ajánló (semmi meglepetés) + foglalás ha kell, akár csak az érdeklődők jelzése a szolgáltatók felé, kapcsolatfelvétel a szolgáltatóval,
- fekete-fehér fotók (filmek) színezése, adatbázis támogatással pl a wikipedia (példa alapú: Pécs, török templom tere, 1970, tél, galamb - magyar háborús film 1944 magyar, orosz, katonai ruha, Kecskemét, Pannónia motor kerékpár) tereptárgy felismerés, növényzet felismerés, évszakoknak/éghajlatnak megfelelő növényzet és öltözködés felismerése
- mezőgazdasági app (gazdák vetése, termék minőség, mennyiség, éves becslés, ellenőrzés, kiértékelés, támogatás mértéke, jövőre levonás ha penészes a friss kenyér) összekötve a gazdák vegyszerfelhasználásával:) jövő évi becslése a szükségesség és minőség alapján
- TV app, csatorna automatikus sorba rendező nézettség, kategóriák és minőség (SD/HD) alapján, hangolás figyelő (értesítő) és auto hangoló, havonta lehetne 2x-3x hangolgatni, kedvenc műsor figyelő, értesítő, figyelmeztető
- dinamikus város lámpairányító rendszer (sebességmérés, dugók, tömegközlekedés)
- kressz betartatás, gyorshajtók figyelmeztetése, blokkolása, büntetése Live:)
- menet figyelő, korrigáló, ütközés gátló, kisállat/vadállat figyelő és tároló előjelző rendszer
- ....
100 éve még boszorkányt is égettek
- A hozzászóláshoz be kell jelentkezni
- dinamikus város lámpairányító rendszer (sebességmérés, dugók, tömegközlekedés)
- kressz betartatás, gyorshajtók figyelmeztetése, blokkolása, büntetése Live:)
- menet figyelő, korrigáló, ütközés gátló, kisállat/vadállat figyelő és tároló előjelző rendszer
Nagyon köszönöm a tartalmas hozzászólást, egész kocsiút alatt ezen gondolkoztam. Elsőre az ember azt gondolná, hogy "betáplálom" a mindent, és megadja a választ mindenre is (=42). De konkretizálva a dolgokat, egy olyan felügyelt tanulásom elmélkedtem, amely:
- Output vektorában azt tartalmazza, hogy volt-e baleset. Továbbfejlesztve 0.1=integetés, 0.2=kiabálás...0.5=nagy fékezés, 0.6=dudálás, 0.8=kis baleset, 1=nagy baleset, azaz a "zavar"-nak a szintje.
- Input vektor pedig lehetne ez: életkor, vezetett km, aznapi távolság, kocsi típusa, benne ülők száma, sebesség, időpont, évszak, forgalom telítettsége %-ban, eső, black-friday-ig hátralévő napok száma...
- Közte 3 hidden layer, mert az input 3 tényezője együttesen már jelent valamit.
Ezek alapján nekiállnék tanítani, majd a teszteken már előre lehetne látni, hogy: mennyit számít az életkor, hogy bmw-ben ül-e az illető és hogy megéri-e terhelni a BF-ig hátralévő napok számával a rendszert, azaz ez menyire számít.
Ezzel a fenti modellel már csak az a baj (azon túl hogy annyira izgat, hogy csak ezen jár az agyam):
- Egy betáplált algoritmus azonnal használatba vehető, ML esetén először össze kell gyűjteni az adatokat és 1napig-3hónapig tanítani, néha újratanítani. Cserébe ha szerintem fontos az aznap vezetett távolság, akkor ezt nem írja felül az ML.
- Nem biztos, hogy ezek az adatok állnak rendelkezésre, jó előre meg kell mondani, hogy most ezeket gyűjtsük egy évig (ha kellően sűrűn van baleset), majd megpróbáljuk. Ha nem jött be, akkor majd kérek újabb adatokat. Ez egy hosszabb folyamat.
Szóval gondoltatban megint szintet léptem, valahol ott tudom elképzelni, ahol vannak már adatok, amelyeket erősen deformáltak a beépített human algoritmusok, de ML-lel "tudással" vértezhetőek fel a dolgok.
- A hozzászóláshoz be kell jelentkezni
ezt ugye pedig a Tesla már elég mesterien müveli, azt hiszem 12 kamera van beépítve a jármüveikbe, láttam már egy vaddisznó kikerülös videót, illetve amikor egy oriási ráfutásos balesetet elözött meg vészfékezéssel (többször újra néztem a videót, nem tudtam megmondani, mi alapján döntött a fékezés mellett...lehet, van Radar/LiDAR szenzor is a kocsiban). Persze hoz rossz döntéseket is, a baj az, hogy a 2-es szintü önvezetést sokan már 5-nek gondolják...
- A hozzászóláshoz be kell jelentkezni
támogatás mértéke, jövőre levonás ha penészes a friss kenyér
Vajon hogy fogadnák el a gépi tanulást egy olyan perben, ahol a gép van 50 év tapasztalattal szemben és egy olyan diszkriminatív hátrány születik, amely egy pillanatnyi hiba apró következménye? Aka. egy kis penész miatt kidobja-e a pékséget a Spar? Szerintem ki fogja. De ha egy gép mondja meg, hogy ez lehet hogy penészes lesz, azt kevesen fogadnák el mint beszállító.
- A hozzászóláshoz be kell jelentkezni
Nem ilyen egyszerű, nem mai dolog, de pár éve még állítólag előfordul a következő. (nem megfelelő vegyszerezés, és vagy tárolás miatt). A termelt gabona 99%-a takarmány minőségű lett, nem is volt gond egy déli ország megvette, majd átcsomagolta és visszavettük mint "kenyér" gabona:) az összeset.
Szerintem a gépi tanulás ahhoz kell, hogy elégséges, megfelelő minőségű gabona legyen termelve. (ki hová, mit ültessen, milyen és mennyi vegyszert használjon, illetve mikor legyen az aratás) - amit az időjárás, ?mm eső és a mikor, illetve a napos órák száma befolyásolja. De lehet ez műkődík is már papíron.
100 éve még boszorkányt is égettek
- A hozzászóláshoz be kell jelentkezni
kár, hogy még nincs kész a blogom, ide jól passzolna...
betanítottam az Azure felhöben az ML-t anomáliák felismerésére. egy nyaralónak a gázellátását kell figyelnie, hogy ha gázkimaradás van vagy hibát jelez a cirkó, jelezze azt. Lehet hümmögni, hogy igen ezt procedurálisan is le lehet programozni. Csak elég sok IF vagy SWITCH/CASE kell hozzá, és biztos lehetsz, hogy valamilyen állapotra nem fogsz gondolni. Nekem nem volt más dolgom, mint egy évnyi hömérséklet és kazán adatot feltölteni mint "Training-set" : amiben persze nem volt hibaeset (felügyelet nélküli tanítás), vagy lehetett volna hibaesettel is, csak akkor fel kellett volna cimkézni (felügyelt tanítás).
A legnagyobb poén az volt, hogy 3 másik anomáliát is jelez a rendszer, amivel nem is számoltam: ha az inteligens termosztáttal valamiért megszakad a TCP kapcsolat, ha tüz van (nem akarom kipróbálni) illetve volt egy programozási hibám a rendszerrel való kommunikációban és azt is kiszúrta (Modbus-on keresztül kérem le a hömérséklet adatokat, és a külsö hömérsékletnél elöjel nélküli egész számokat adatam meg típusként, és amikor elöször 0 alá ment a hömérséklet, abból útlcsordulás lett, valami 6553,4 és erre is jelzett... :))
ezt egyébként arra használtam, hogy én is ismerkedjek az ML-el
Másik példa: a lakásban van egy hömennyiség mérö, illetve tudom a szobák beállított hömérsékletét illetve a külsö hömérsékletet. Ezekkel az adatokkal a jövöbeni felhasznált hömennyiséget akarom kiszámolni, az idöjárás elörejelzés figyelembe vételével
harmadik példa: kollégáknak tartottam elöadást ezekröl a dolgokról, és poénból megnéztem, sikerül-e valami gyors példát össze hozni képfelismeréssel is. a customvision.ai-on (az is az Azure ML Studio része) elegendö osztályonként 6-7 képet felrakni egy 2 osztályos klasszifikáció megvalósításához. Fogtam egy autópálya közlekedési kamera stream-et és onnan leszedtem olyan képeket, amikor dugó illetve normális forgalom volt azon az autópálya szegmensen. a vicc az, hogy ebböl a 6-7 felcimkézett képböl bármely napszakban 99%-os pontossággal megmondja, van-e dugó.
igen, igen, tudom, ez mind megy pythonban is. Csak azt sajnos még nem vágom, majd karácsonyi szabi alatt arra fogok rágyúrni. Ötletem még sok van, egyik sem világmegváltó, de engem érdekelnek.
- A hozzászóláshoz be kell jelentkezni
Pont úgy, ahogy gondolkodsz, csak fordítva. Azaz keress olyan problémát, amire nincs, vagy csak irreálisan nagy lépésszámú algoritmus van.
Tipikus: válaszd ki a macskás képeket
De saját példa is van, pedig az még a gépi tanulás őskorában volt 2000 előtt. Az alakemlékező fém szál mozgásegyenlete alapból is marha bonyolult, és van benne pár "konstans", ami minden mozgás után kicsit elmászik. Ezzel mozgattunk egy robot ujjat. Normál szabályzástechnikai módszerekkel a belehülyülsz kategória. Kapott egy mai szemmel vicces méretű neurofuzzy vezérlést és meglepően pontosan működött.
- A hozzászóláshoz be kell jelentkezni
Tipikus: válaszd ki a macskás képeket
https://cdn140.picsart.com/326945118089201.jpg?type=webp&to=min&r=640, …, ...
{kind=link}
- A hozzászóláshoz be kell jelentkezni
Nagyon jó példa, köszönöm, soha nem jutott volna eszembe.
- A hozzászóláshoz be kell jelentkezni
következő lépésként csak a saját macskád és a saját kutyád engedje be az ajtón :). Meg a családtagjaid :P. Kinyomtatott arcképekkel azért teszteld előtte :P
- A hozzászóláshoz be kell jelentkezni
Van már hasonló, elég ötletes. Ha a macska viszi haza a prédát, ki lesz tiltva pár percre a házból.
https://www.youtube.com/watch?v=1A-Nf3QIJjM
Jó példa arra, hogy SBC + AI párossal olyan dolgokat is meg lehet oldani, ami a hagyományos programozási szemlélettől távol áll.
- A hozzászóláshoz be kell jelentkezni
Egyik kollégámmal nemrég beszélgettünk erről a képfelismerésről, és mondta, hogy valami bankhoz kellett azonosító okmányt feltölteni, ill. egy saját fotót.
Megpróbálta azt, hogy nem a mobil fotójával készít képet, hanem lefényképez egyet (azt hiszem appon keresztül kell elkészíteni a fotót), és a rendszer felismerte, hogy ez egy fotó, nem pedig élőkép...
- A hozzászóláshoz be kell jelentkezni
Pár megjegyzés, a probléma ott van, ami nem biztos, hogy átjött az online tanfolyamon. Amit most mesterséges intelligenciának hívunk, az nem mesterséges intelligencia. A gépi tanulás sokkal közelebb áll a valósághoz. Amit te próbálgatsz az a része ennek a témakörnek, amit Deep Learning-nek neveznek. Pl az ajánló egy nearest neigh. algoritmus, ami metrikák alapján számol hasnlóságot és sorrendbe állítja, ez egy teljesen másik kávézáz. A Deep Learning amit feszegetsz, meg Kolmogorov tétele alapján megy, ami arról szól, hogyan kell egy MIMO problémából sok SISO-t csinálni. Ennek azekben van sok paraméter amit ki lehet számolni. Az ötlet itt annyi, hogy ezt a számolást kiváltjuk valami paraméter hangolással. Az iparban arra használják, hogy sok különlegesen képzett embert váltanak ki valamivel kevesebb másképpen jól képzett szakemberrel, mert csak a matekot kell tudni és a megvalósítani kívánt probléma szakembereiből jóval kevesebb kell. Az is igaz, hogy a poén és a profit ott van, amikor olyat csinál az ember ami a tudományos cikkekben benne van, de a lib-ekben még nincs.
A nehézségi szint itt nem a matekban van, azokat viszonylag gyorsan meg lehet tanúlni. A nehéz része a megfelelő tanítási adatok előállításában van. Ez nem csak nehéz feladat, hogy ne "tanítsd" túl a rendszert, ami azt jelenti, hogy a tesztadatokon jól működik a rendszered, de a valóságban hamar elhasal.
Van az a vicc, hogy az a technológia amiben nincs AI és blockchain, abban a technológiában már nem is hiszünk.
Igazából azon projekteknél kell ezt elővenni, ahol MIMO a probléma (informatikában ilyen rengeteg van), valamint nagyon bonyolúlt a logika mögötte (ilyen is sok van), valamint nem baj, ha téved (nah ilyenből kevés van), ezt csak akkor szokták megengedni, ha más módon sokkal drágább, vagy megvalósíthatatlan a feladat. A legtöbb cég ezt nem szokta szeretni. Tipikus eset lehet, ha van nagy mennyiségű adatod, és azokon kellene valami nehezen meghatározható szabályrendszer alapján működni. Az igazság az, hogy ezen problémák még így is nagyon számításigényes dolog, és időigényes. Ez nem lesz egy csodaszer, ami tegnapra megoldja a problémákat.
- A hozzászóláshoz be kell jelentkezni
Köszönöm, jó volt olvasni a hsz-odat.
Ez nem csak nehéz feladat, hogy ne "tanítsd" túl a rendszert, ami azt jelenti, hogy a tesztadatokon jól működik a rendszered, de a valóságban hamar elhasal.
Erre nem is gondoltam. Ez csak időben tolja ki a tanulást vagy valóban rossz lesz az eredmény? A tesztek jól lefutnak, ígéretesek, de a valóságban nem ad semmit? Hol csúszik félre egy ilyen ML?
...van nagy mennyiségű adatod, és azokon kellene valami nehezen meghatározható szabályrendszer alapján működni.
Ez egy nagyon jó kapaszkodó, hogy mire is jó ez az egész. Köszönöm!
- A hozzászóláshoz be kell jelentkezni
itt találsz még egy rakat példát, kedvencem a bicikli kölcsönzés elörejelzése: https://gallery.azure.ai/browse?s=bike%20rental
Az Azure ML Studio példákban az a jó, hogy van hozzá már teszt adat és megnézheted, hogyan oldották meg (nem kell a kalapácsot is kifejlesztened, hogy elérj az eredményhez).
Amiben a nagy pénz van benne, és ezért gyüjt mindenki eszeveszett adatot, hogy ha sok különféle adatot tudsz kombinálni egymással, akkor sokkal, sokkal jobb lesz egy regressziód (elörejelzés). Ha vesszük a bringa kölcsönzöt, az idöjárás elörejelzés mellett jól jöhet, hogy munkanapról vagy hétvégéröl van szó, milyen rendezvények lesznek aznap a közelben (Facebook mint forrás?), mi az átalgos keresete az embereknek akik kölcsönöznek, hány gyerekük van, stb (anyagi háttér!). Ez alapján nem csak a várható kölcsönzési számot lehet elöre jelezni, de hogy milyen áron lehet bérbe adni a bringákat.
Na és akkor a bringakölcsönzöt helyettesítsd be valami sokkal nagyobb céggel/termékkel....a profilod meg már úgy is megvan valamiylen adatbankban a netes szokásaid alapján, ha neten regisztrálsz a szolgáltatásra valamilyen ismert email címröl vagy gépröl ahol sok az elmentett süti, akkor pedig pontosan be tudják löni az árat és hogy igénybe veszed-e a szolgáltatást... :)
Na erre (is) jó az ML... :)
- A hozzászóláshoz be kell jelentkezni
Ahogy nézem itt lineáris regressziót használnak. Ez sem Deep learning, hanem a Machine learning egy másik ága. Ez a feladat tipikus, másik klasszikus példa a fagyizó esete, amikor mérik, hogy hány fok van és mennyi fagyit adnak el. Az a módszer, hogy felveszik x tengelyre a hőmérsékletet, y-ra az eladott fagyik számát. Erre illesztenek egy egyenest ami a legjobban megközelíti ezt az adathalmazt. Mikor ez megvan, akkor le tudják olvasni, hogy mondjuk holnapra 30 fokot mond az előrejelzés, tehát várhatóan mennyi fagyi megy el. Jobbak azt is megcsinálják, hogy a nap végén az új adatokat is beviszik, és azzal újrakalkuláltatják. Ez tulajdonképpen szokták a Machine Learning probléma Hello World-jének is hívni. A képlet amivel csinálod úgy kezdődik, hogy parciális derivált. Szóval ebből is látszik, hogy ez egy eléggé matematika orientált terület.
- A hozzászóláshoz be kell jelentkezni
A túltanítás rossz eredményt ad, akkor ki kell dobni az addigi modelt és újrakezdeni, elméletileg meg lehet javítani, de az sok nagyságrendel több munka, szóval sokkal olcsóbb eldobni és újat kezdeni.
Ennek több okai is lehet. Először az alakalmazott aktivációs függvények is lehetnek erre érzékenyebbek és kevésbé érzékeny. A népszerű ReLU függvény példáúl érzékeny, ez hívta életre a ReLU+-t ami annyiban különbözik, hogy a negatív részen nem konstans 0, hanem egy nagyon pici szögű egyenes. De ez önmagában még kevés. A problémát a nem megfelelően előkészített és kiválasztott tanuló adatok adják. Tulajdonképpen túl specifikusak. Mintha kb azt tanítanád, hogy a ferrari az a piros autó, minden képen piros a ferrari, a töbi nem, símán kijön a 100%-os pontosság. Viszont a valóságban a piros Ignis-t is betolja ferrarinak és nem ismeri fel a sárga ferrarit. Persze ez egy nagyon sarkított példa, ennél a valóságban sokkal finomabb dolgok vannak és ezért szokott meglepetéseket is okozni.
Ajánlok egy podcast-et amit érdemes hallgatni, több jó külföldi is van, azokat is meg tudod találni, de itthon is tudok egy nem rosszat. Ha érdekel a téma ez egy kellemes hallgatni való.
- A hozzászóláshoz be kell jelentkezni
tultanitas = overfitting
https://en.wikipedia.org/wiki/Overfitting
a cel az, hogy a neuralis halod kifejlesszen egy olyan modelt amivel eleg jo pontossaggal barmilyen input adatbol az altalad vagyott outputot eloallitja. ez a pontossag nem szokott 100% lenni, olyan 90 es 99.99 kozotti a feladat bonyolultsagtaol es a zinput minosegetol fuggoen.
ha tultanitod, akkor a tanitashoz hasznalt inputra 100% fog adni, de ezzel nagyon specifikus modelt hoz letre, ami viszont mas inputra nem nagyon fog mukodni.
itt a kepen a fekete gorbet szeretnenk megkapni, nem pedig a zoldet, hiaba ad a zold az adott esteben pontosabb eredmenyt:
https://upload.wikimedia.org/wikipedia/commons/thumb/1/19/Overfitting.s…
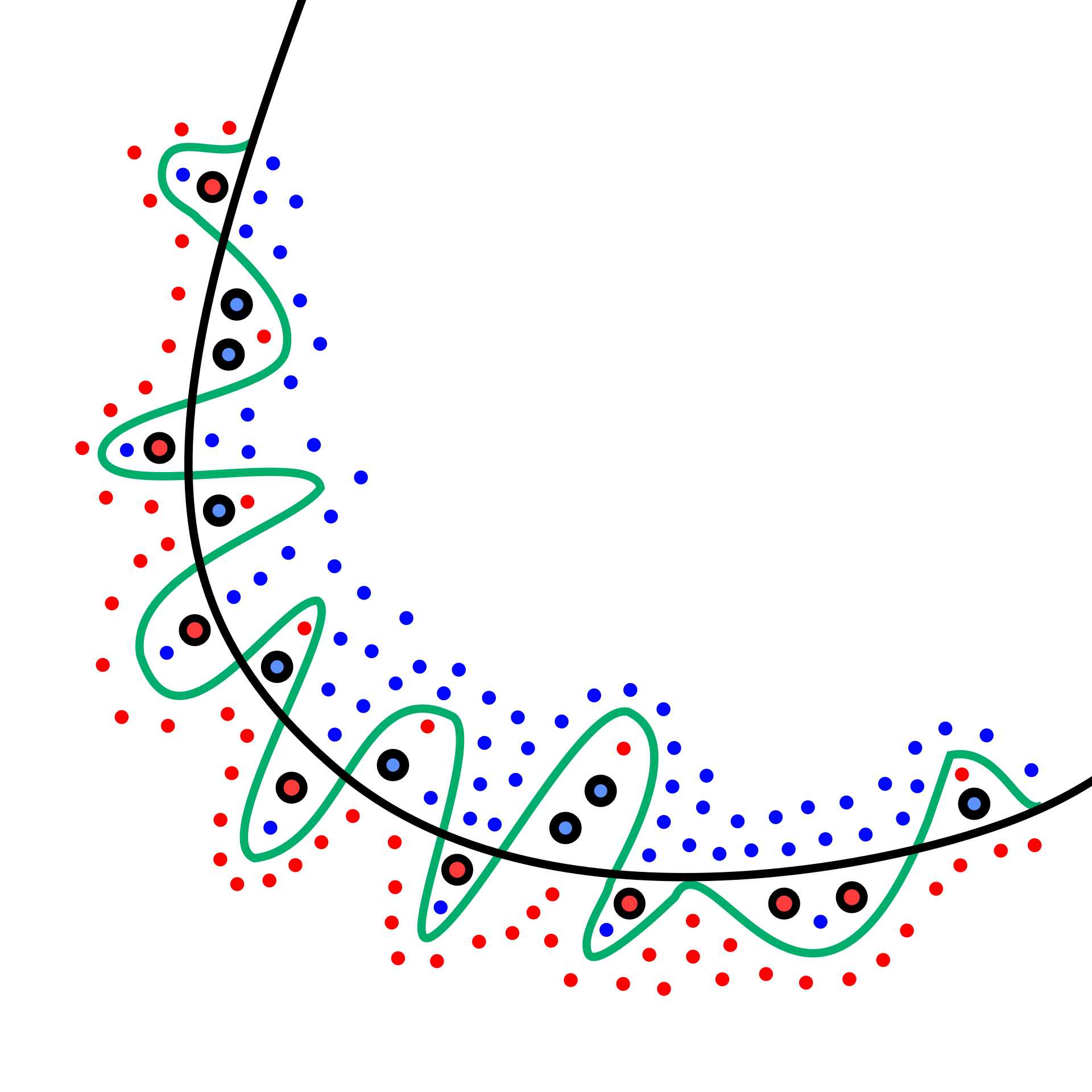{kind=link}
- A hozzászóláshoz be kell jelentkezni
bookmark
- A hozzászóláshoz be kell jelentkezni
+1 :D
- A hozzászóláshoz be kell jelentkezni
na a jesszuska hozott magamnak egy nvidia Jetson nano-t mert jó voltam... :)
- A hozzászóláshoz be kell jelentkezni
Huh, izgi kis gép. Melyik időzónaban van már szenteste?
- A hozzászóláshoz be kell jelentkezni
:D még nincs, de mivel magamnak vettem, ki is bontottam. még meg kell csinálni a tápot hozzá és akkor kezdem is nézegetni a dolgot
- A hozzászóláshoz be kell jelentkezni
Egyik rádióamatőr társunk gyenge távíróhangok vételére tanítgatja a mesterséges intelligenciát.
A cél, hogy az emberhez hasonlóan képes legyen a nehezen vehető távírójelből is az információt kinyerni.
- A hozzászóláshoz be kell jelentkezni
ha mar HUP, erdekes projekt lenne (bar lefogadom hogy paran mar megcsinaltak):
Munin grafikonok figyelese, es anomaliak jelzese, riasztasa.
Ugye eleg sok mindent lehet ott nezni, pl. homersekletek, tarhely (disk, ram, db stb), cpu terheles, mail forgalom, adatforgalom...
Uzemeltetokent megfigyeltem mar hogy vannak periodikus valtozasok a legtobb ertekben, nyilvan a kornyezettel es a munkaidovel osszefuggesben, van ami naponta ismetlodo hullam, van ami hetente stb.
Az lenne az erdekes, hogy a korabbi adatokkal megtanitva egy MI-t (nem feltetlen neuralis halo, regebben fourier transzformacioval alltam volna neki ennek) az elorejelzesre, es azt ossze kene vetni a valos mert adatokkal.
- A hozzászóláshoz be kell jelentkezni
szerintem az, hogy gépileg olvasható adatokat képpé konvertálsz és utána akarsz ML algoritmusokat alkalmazni, túlkomplikálja a dolgot. Én úgy futnék neki, hogy pl. Node-Red-ben feltennék egy vagy több SNMP node-ot amik olvassák a megfigyelt értékeket és ezeket egy adatbankba vagy cvs fájlba gyüjtik (cimkével/cimke nélkül) egy hét/hónap után pedig megcsinálnám vele az elsö modellemet. utána ebbe a modellbe tölteném be az aktuális értékeket, figyelve/tesztelve a modell eredményét, hogy helyes-e.
Én is ilyensmire gondoltam, csak mondjuk Apache logfájlok monitorozására és ott anomáliák felderítésére (script kiddies, etc.)
ha szánsz rá idöt, szivesen segítek, érdekes projektnek hangzik
- A hozzászóláshoz be kell jelentkezni
nyilvan nem a munin altal generalt grafikon kepekre tolnek en se AI-t :)
ott vannak a munin szerveren rrd adatbazisban a mert adatok, nagyreszt float/int, azokkal kene dolgozni. ki lehet egyszeruen konvertalni csv-be is.
- A hozzászóláshoz be kell jelentkezni
Munin grafikonok figyelese
bocsi ebböl az jött le...ránéztem felületesen, de nem találtam db engine-t mögötte...így viszont nem annyira nehéz
- A hozzászóláshoz be kell jelentkezni
mire használd az AI-dat? pettingre (csak viccelek)
de viccet félretéve olvastam valami érdekeset a deep learning-ről:
"A Deep Learning reprezentációs tanulás: hasznos ábrázolások automatizált létrehozása adatokból. Az, hogy miként képviseljük a világot, egyszerűvé teheti a komplexumot nekünk embereknek és az általunk létrehozott gépi tanulási modelleknek is. Kedvenc példám az előbbire, hogy Kopernikusz 1543-ban publikálta a heliocentrikus modellt, amelyben a nap áll az "univerzum" középpontjában, szemben a korábbi geocentrikus modellel, amelynek középpontjában a Föld állt. A legjobb esetben a Deep Learning lehetővé teszi számunkra, hogy automatizáljuk ezt a lépést, és eltávolítsuk a Copernicust (azaz tapasztalt embereket) a "funkciómérnöki" folyamatból.
A heliocentrizmus (1543) szemben a geocentrizmussal (Kr. E. 6. század).?
A pálya forrása. Magas szinten az ideghálózatok kódolók, dekóderek vagy mindkettő kombinációi: A kódolók mintákat találnak a nyers adatokból, hogy kompakt, hasznos ábrázolásokat alkossanak.
A dekóderek nagy felbontású adatokat generálnak ezekből az ábrázolásokból.
A létrehozott adatok vagy új példák, vagy leíró ismeretek. A többi okos módszer, amellyel hatékonyan kezelhetjük a vizuális információkat, a beszédet, a hangot (# 1–6), sőt ezen információkon és alkalmi jutalmakon alapuló világban is működhetünk (# 7). Itt van az átfogó nézet.
A következő szakaszokban röviden ismertetem mind a 7 építészeti paradigmát,
1. Feed Forward Neural Networks (FFNN)
Az 1940-es évekre visszanyúló történelmű FFNN-ek egyszerűen hálózatok, amelyeknek nincs ciklusa. Az adatokat a bemenetről a kimenetre egyetlen menetben továbbítják, anélkül, hogy korábban rendelkezésre állt volna „állapotmemória”. Technikailag a mély tanulás során a legtöbb hálózatot FFNN-ként lehet felfogni, de általában az „FFNN” a legegyszerűbb változatára utal: egy szorosan összekapcsolt többrétegű perceptronra (MLP).
A sűrűségkódolók segítségével a bemeneten már kompakt számkészletet egy jóslathoz lehet feltérképezni: vagy osztályozás (diszkrét), vagy regresszió (folyamatos).
2. Konvolúciós ideghálózatok (CNN)
A CNN-ek (más néven convNets) előremutató ideghálózatok, amelyek térbeli invariancia-trükkel hatékonyan megtanulják a helyi mintákat, leggyakrabban képeken. A térbeli változatlanság azt jelenti, hogy a kép bal felső sarkában lévő macska fülnek ugyanazok a jellemzői vannak, mint a kép jobb alsó sarkában lévő macska fülnek. A CNN-ek megosztják a súlyokat a helyiségben, hogy hatékonyabbá tegyék a macskafülek és más minták felismerését. Ahelyett, hogy szorosan összekapcsolt rétegeket használnának, konvolúciós rétegeket (konvolúciós kódolókat) használnak. Ezeket a hálózatokat képosztályozásra, objektumfelismerésre, videoműveletek felismerésére és minden olyan adatra használják, amelyek felépítése bizonyos térbeli változatlanságot mutat (pl. Hanghang).
3. Ismétlődő ideghálózatok (RNN)
Az RNN-ek olyan hálózatok, amelyek ciklusokkal rendelkeznek, ezért "állapotmemóriával" rendelkeznek. Időzíthetők, hogy előremenő hálózattá váljanak, ahol a súlyok meg vannak osztva. Ahogy a CNN-ek az űrön keresztül osztják meg a súlyokat, az RNN-ek az időn keresztül osztják meg a súlyokat. Ez lehetővé teszi számukra a szekvenciális adatok mintáinak feldolgozását és hatékony megjelenítését. Az RNN-modulok számos változatát fejlesztették ki, köztük az LSTM-eket és a GRU-kat, hogy megkönnyítsék a minták elsajátítását hosszabb szekvenciákban. Az alkalmazások magukban foglalják a természetes nyelv modellezését, a beszédfelismerést, a beszédgenerálást stb. Az ismétlődő neurális hálózatok nehezen képezhetők, de lehetővé teszik a szekvenciális adatok szórakoztató és hatékony modellezését is.
4. Kódoló-dekóder architektúrák
Az első három szakaszban bemutatott FFNN-k, CNN-ek és RNN-ek egyszerűen olyan hálózatok, amelyek előrejelzést adnak akár egy sűrű, egy konvolúciós kódoló, akár egy ismétlődő kódoló segítségével. Ezek a kódolók kombinálhatók vagy kapcsolhatók a nyers adatok típusától függően, amelyekhez hasznos ábrázolást szeretnénk létrehozni. A "kódoló-dekóder" architektúra egy alárendelt koncepció, amely a kódolási lépésre épít annak érdekében, hogy egy dekódolási lépésen keresztül nagy dimenziós kimenetet generáljon a becsomagolt ábrázolás mintavételezésével előrejelzés helyett.
Vegye figyelembe, hogy a kódoló és a dekóder nagyon eltérő lehet. Például egy felirathálózat tartalmazhat konvolúciós kódolót (képbevitelhez) és ismétlődő dekódert (természetes nyelvű kimenethez). Az alkalmazások magukban foglalják a szemantikus szegmentálást, a gépi fordítást stb.
Vezetési jelenetek szegmentálási bemutatója bemutatja a korszerű szegmentációs hálózatot az autonóm járműészlelés problémájához
5. Autoencoder
Az automatikus kódolók a „felügyelet nélküli tanulás” egyik egyszerűbb formája, amely a kódoló-dekóder architektúrát használja a bemeneti adatok pontos másolatának előállításához. Mivel a kódolt ábrázolás sokkal kisebb, mint a bemeneti adatok, a hálózatnak meg kell tanulnia a legértelmesebb ábrázolás felépítését. Mivel az alapvető igazságadatok a bemeneti adatokból származnak, nincs szükség emberi erőfeszítésekre. Más szavakkal, önellenőrzés. Az alkalmazások magukban foglalják a felügyelet nélküli beágyazást, a kép elnyomását stb. Ami a legfontosabb, hogy a "reprezentációs tanulás" alapgondolata központi szerepet játszik a következő szakasz generatív modelljeiben és az összes mélyreható tanulásban.
6. Generatív kontradiktórius hálózatok (GAN)
A GAN képzési hálózatok kerete, amelyek optimalizáltak új reális minták előállításához egy adott reprezentációból. A legegyszerűbb formájában a képzési folyamat két hálózatot foglal magában. Az egyik hálózat, amelyet generátornak hívnak, új adatpéldányokat generál, és megpróbálja becsapni a másik hálózatot, a diszkriminátort, amely a képeket valósnak vagy hamisnak minősíti. Az utóbbi években számos variációt és fejlesztést javasoltak a GAN-ok számára, többek között az a képesség, hogy képeket generál egy adott osztályból, a képesség az egyik domainről a másikra történő leképezésre, valamint a generált képek realizmusának hihetetlen növekedése. Olvassa el a Deep Learning State of the Art című előadást, amely a GAN-ok gyors fejlődését érinti és kontextusba helyezi.
7. Deep Reinforcement Learning (Deep RL) A megerősítő tanulás
A megerősítő tanulás (RL) egy keretrendszer, amely megtanítja az agenteket arra, hogyan kell a világban úgy cselekedni, hogy a jutalom maximális legyen. Amikor a tanulást ideghálózat végzi, akkor mély megerősítő tanulásnak (Deep RL) nevezik. Három típusú RL keretrendszer létezik: házirend-alapú, értékalapú és modellalapú. A különbség az, hogy mit terhel az ideghálózat a tanulással.
A Deep RL segítségével neurális hálózatokat alkalmazhatunk szimulált vagy valós környezetekben, amikor döntési szekvenciákat kell meghozni. Ez magában foglalja a játékot, a robotikát, a neurális architektúra megtalálását és még sok minden mást."
- A hozzászóláshoz be kell jelentkezni