Ha valaki azt hiszi, hogy a NEPOMUK és a szemantikus desktop valamiféle zugprojekt, az téved. A projekt mögött olyan nevek sorakoznak fel, mint az IBM, SAP, HP és még sokan mások.
A NEPOMUK-KDE akcióban:




A dologról bővebben az InternetNews cikkében.
Kapcsolódó linkek:
semanticdesktop.org
nepomuk.semanticdesktop.org
Semantic Desktop and KDE 4 - State and Plans of Nepomuk-KDE [Update]
- A hozzászóláshoz be kell jelentkezni
- 5855 megtekintés
Hozzászólások
mint tudomány érdekes, támogatom. viszont egyelőre nem értem a desktophoz kötődését. a demo videóban mutatott "adjunk csillagokat, és kommenteket" dolog pl. mire jó?
- A hozzászóláshoz be kell jelentkezni
Több terabyte-nyi adat közt már most sem tudsz hatékonyan keresni, rendszerezni (és ez egyre több lesz). Itt a HUP-on is gyorsabban találsz meg egy cikket, ha az kategóriákba rendezve (taggelve) van. Ha nem lennének kategóriák, hanem minden egybe lenne ömlesztve (és a Google sem indexelné), akkor baromi nehezen lehetne keresni. Ha taggelsz egy file-t, netán értékeled is, akkor sokkal egyszerűbben tudod keresni. Ha magyarázattal látod el, akkor tudni is fogod mi van benne mondjuk 5 év múlva. Példa: létrehozol egy logo.png-t. Öt év múlva tudni fogod, hogy milyen logó az? Nem. De ha kereséskor rákattintva kiírja azt a kommentet, amit te fűztál hozzá, hogy "XY webes projektem 10x10-es transzparens logója", akkor azt hiszem, hogy beljebb vagy. Vagy gondolj bele abba, hogy keresel egy MP3-at. Azt mondod a keresőnek, hogy csak az "5-ösre értékelt", "trance", "2005", "nyár" taggel jelölt MP3-akat keresse meg neked. A felhasználási lehetőségek skálája széles. Igen, vannak már hasonló törekvések.
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
"Öt év múlva tudni fogod, hogy milyen logó az?"
Tipikusan a fájlnév és a tartalmazó könyvtárnév együttesen eldönti. A példában mondjuk a ~/projects/web/xy/logo_10_transparent.png néven kerülhet mentésre a logo.
- A hozzászóláshoz be kell jelentkezni
Ühüm. Én is így csinálom. Csakhogy ez nem hatékony.
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
miértis? ömleszteve jobb lenne, csak tag alapján?
--
Peace, Love, Unity, Respect
- A hozzászóláshoz be kell jelentkezni
Miért a HDD-n is ömlesztve vannak az adatok, mégis mindent megtalálsz. Jelenleg is minden fájlhoz tartozik egy tag, "melyik könyvtárban kell lennie"
- A hozzászóláshoz be kell jelentkezni
Na ugye, milyen jók a tag-ek... :-)
---
;-(
- A hozzászóláshoz be kell jelentkezni
De, ha így tárolod akkok elég nehéz lehet összeszedni az összes logot. Ha viszont ellátod olyan taggel, hogy "Logo" akkor egy kereséssel kidobja az összeset. A könyvakkal az a baj, hogy kialakítasz egy logikát és a szerint csoportosítod az adatokat, viszont, ha más feltételek szerint kellenek az adatok akkor jön jól egy ilyen megoldás.
Személyi adatok tárolására csináltam hasonlót. A személy adatai voltak maguk a tag-ek (név, település, munkahely, ...) keresni pedig úgy lehetett, hogy egy kiválasztott tag variációi közül lehetett választani. A választást követően a többi tagnél már csak azok a tag értékek jöttek amelyek az eddig megadott tag feltételeknek is megfelel.
Ha van ~100 személy egy adatbázisban akkor a névsor elég hatékony, de ha mondjuk magyarország összes személye szerepelne benne, elég nehéz lenne a névsort használni, főleg mert pl. 'Nagy Balázs'-ból biztos van pár ezer.
- A hozzászóláshoz be kell jelentkezni
Sajnos drupalban ez a kategoria rendszer messze van attol a cimkezestol, amirol ez a post is szol. Egy rendes portal rendszerben (szerintem) fel lehetne cimkezni egyenkent a postokat, amit nem csak a leader boss, hanem a kozosseg is megtehetne. Peldaul a "16 000 linuxos számítógépet adott át a rászorulóknak" c. cikkre en raaggatnam a "linux desktop hardware recycle non-profit hero" tageket (sot, akar a James Burgett nevet is, ha relativ sokszor megjelenik a neve mas es mas vonatkozasban).
- A hozzászóláshoz be kell jelentkezni
Ugyan ez offtopik, de Drupal-hoz is van ilyen lehetőség, de ahhoz érett olvasótábor kell, hogy ne csak parasztkodásból álljanak a címkék (free tags). Többszörös címkézési lehetőség elérhető lenne a szerkesztőnek, de jelenleg nem kívánom használni. Elegendő a beépített taxonomy modul.
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
gondolom meg tudod jelölni a pdf (vagy egyébb állományaidat), hogy milyen témakörhöz kapcsolhatóak majd a megadott tag-ek alapján tudsz keresni. Enpedig pont ezt a keresési funkciót hiányoltam a kisfilmből. Így nem csak a könyvtárszerkezeted lesz ami kategorizálja a dokumentumaidat, hanem az ezen túlmutató jellemzőknek ad helyet ez a jelölési forma, ha jól értelmezem így elsőre ezt...
Azt, hogy a szemantikus hiányosságok a legnagyobb problémái a nyílt forráskodú projekteknek kicsit erősnek érzem. Egyáltalán hol van ez megvalósítva, hogy innen meg hiányzik? Biztos én vagyok lemaradva....
ontológiával kapcsolatban:
- A hozzászóláshoz be kell jelentkezni
"Enpedig pont ezt a keresési funkciót hiányoltam a kisfilmből."
Ilyesmit mondott a fazon a végén:
"of course in later versions of NEPOMUK you will see many more possibilities"
Azaz, később sokkal több szolgáltatás várható, a jelenlegi - erősen fejlesztői teszem fel - állapot ez.
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
a hangot nem hallottam, de az üzleti szféra meg fogja követelni tőlük azt a sok jövőbéli megoldást
- A hozzászóláshoz be kell jelentkezni
Az üzleti szféra egy jelentősnek mondható része - HP, IBM, SAP - áll a projekt mögött, ami arra enged következtetni, hogy nem "akkora baromság" ez az egész. Garancia persze erre nincs.
BTW: én már most sem igazodok el sokszor 80 GB-os HDD-men (mondjuk a Beagle sokat segít, de lehetne jobb is). Mi lesz ha 1-2 terabyte lesz az standard mndjuk egy notebook-ban? Valami megoldás kell. Hogy ez lesz-e az? Ki tudja.
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
mikor meg csak 40-80 megabyteos HDDk voltak akkor azon tortuk a fejunket, jajj milesz ha majd 40-80 gigabyteos lesz, lenyegeben nem valtozott semmi, es megse dolt ossze a vilag... ugyanez lesz a kovetkezo lepesben is. es akkor sem fog.
Mellesleg ha te nekiallsz egyenkent betagelni meg mit tudome en az osszes fileodat akkor egeszsegedre. valoszinuleg sokkal tobb idot fogsz vele elcseszni mint amennyit valaha is nyersz vele
- A hozzászóláshoz be kell jelentkezni
"Mellesleg ha te nekiallsz"
Én biztos, hogy nem, tekintve, hogy a gépemen akkor lesz KDE, ha minden más DE megszűnik, ellenben ez egy lehetőség lesz azoknak, akik szeretnének ily módon dolgozni.
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Frissítettem a cikket képekkel. Ott már látszik, hogy lehet tag-ekre és kommentekre keresni.
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Most van egy halom fényképem, amelyeket a kphotoalbum programmal katalogizálok. Tag-eket teszek rá, helyszín, szereplők, kulcsszavak.
Ma pl. reggel a lányomra ráadtam egy szoknyát, ami kb. combközépig ért. Mondtam neki: -Luca! Tudtad, hogy amikor Párizsban laktunk, mennyire nagy volt még neked ez a szoknya? -mert emlékeztem egy fényképre, amit pár hete, vagy hónapja láttam. Kérte, hogy mutassam meg.
Fogtam a kphotoalbumot, és azt mondtam a keresésnél, hogy location:Versailles, Persons: Luca, és kidobott kb. 10-20 képet, amik között ott volt az az 5-6 kép, amik közül egyre emlékeztem.
Régebben könyvtárakba szedtem a fényképeimet, van egy scriptem, ami létrehoz egy év/hó/fájl hardlinket. Így automatikusan megvan hónap bontással, hogy mikori kép. Régebben szintén linkeket készítettem, volt olyan, hogy család, meg jóképek.
Mivel fogalmam sem volt, hogy melyik hónapban voltunk Versailles-ben, elég sok képet át kellett volna nézni, ha nincsenek a Tag-ek.
Szóval meg lehet oldani könyvtárstruktúrával is, de azért látható, hogy a tag-elés lényegesen hatékonyabb.
És pl. a filelight sem zavarodik bele abba a bonyolult kérdésbe, hogy akkor egy fájl két könyvtárbejegyzéssel mekkora helyet is foglal :-)
Ha a KDE4-ben alapértelmezetten megy ez a cucc, akkor simán az egész kphotoalbum felesleges lesz számomra, mert a konquerorból adhatom a tag-eket, és a csillagokat. És a konquerorban egyébként is jobban szeretem a képeket kezelni, jobb a slideshow, meg a zoom, stb.
G
- A hozzászóláshoz be kell jelentkezni
csak kde4-ben mar a konqueror lesz deprecated :)
--
Those who do not understand Unix are condemned to reinvent it, poorly. (based on true story)
- A hozzászóláshoz be kell jelentkezni
Konqueror nem lesz deprecated, csak nem lesz alapértelmezett. (Webböngészőként alapértelmezett lesz, de ez most nem tartozik ide.) Az más kérdés, hogy fogja-e tudni a tag-elést. (A dot.kde.org-on írtak alapján úgy tűnik, inkább az a koncepció, hogy mindenki azt használja, amelyiket akarja, de a Konquerort inkább azok használják, akik vissza tudják állítani alapértelmezettnek.)
- A hozzászóláshoz be kell jelentkezni
A KDE-t általában azok használják akik át tudják állítani :)
(kezdem megérteni a $OTHER_FLAMEBAIT_DESKTOP usereket: ami beállíthatatlan, nem is érdemes próbálkozni a konfigolásával, jóóólesz az defaulton... ;) )
- A hozzászóláshoz be kell jelentkezni
"A KDE-t általában azok használják akik át tudják állítani"
Úgyy tűnik, ezen akarnak (sajnos egy kicsit túlzottan) változtatni.
- A hozzászóláshoz be kell jelentkezni
Igazabol szamomra ez onnantol lesz hasznalhato, amikortol ezek a tag-ek automatikusan generalodnak majd, es kereshetsz pl. ugy, hogy 'mi is volt az a pdf, amit ket hete kuldott at a Jozsi levelben'.
- A hozzászóláshoz be kell jelentkezni
erdekes otlet. a web 2.0 featureinak "vissza" portolasa desktopra.
de nem igazan latom ertelmet az egyszemelyes web 2.0-nak.
epp az a lenyeg, hogy látom miként ratingolja, es tagelei a vilagot a millionyi user.
az egesz web 2.0/opensource/wikipedia/... mozgatorugoja az, hogy adok 1-et es kapok ezret.
ceges kornyezetben lehet ennek ertelme
- A hozzászóláshoz be kell jelentkezni
ez nem web2 visszaportolása desktopra, hanem egy természetes emberi igény. Elhárult az akadálya annak,hogy tetszőleges információmennyiséget tárolj és tárolsz is, de most jön az a rész, hogy el akarsz igazodni benne. Ennek az igénynek az első jele a fenti megoldás illetve a web2 -nek a tag-elési dolgai.
ha erről többet akarsz tudni, akkor egy iratkozz be egy könyvtásori képzésre. ott az osztályozás apró pici bugyraiba fog belelátni...
- A hozzászóláshoz be kell jelentkezni
Úgy kell az egészet értelmezni, mintha barkochba lenne. Ha csak rákérdezésből áll, akkor eltart egy darabig, mire kitalálod. Ha viszont "személy? élő személy? magyar?" alapon csinálod, akkor sokkal gyorsabban eljutsz a megoldáshoz.
Ennél szemléletesebben nem tudom leírni.
It doesn't matter if you like my song as long as you can hear me sing
- A hozzászóláshoz be kell jelentkezni
Nem olyan hülyeségű ez, mert én például a zenéimnél szoktam olyat csinálni, hogy csillagokkal értékelem amarok-ban őket. És ha valaki jön, és jó zenét akarunk hallgatni, akkor azt mondom az amarok-nak, hogy csak 4-5 csillagos számokat mutasson. Ezt könyvtárszerkezettel úgy nehéz lenne megoldani, hogy közben maradjon együttes/album alapján is csoportosítva.
- A hozzászóláshoz be kell jelentkezni
symlink
- A hozzászóláshoz be kell jelentkezni
playlist
- A hozzászóláshoz be kell jelentkezni
Mesterségesen gerjesztett igény ;-)
--
A nyúl egy igazi jellem. Ott ül a fűben, de akkor sem szívja!
- A hozzászóláshoz be kell jelentkezni
Regota fluxbox user vagyok, igazabol 1ik desktop kornyezet sem tudott olyat nyujtani, amiert en felaldoztam volna annyi ramot (regen keves volt belole, manapsag meg mar csak megszokas igy). De ez az uj kde bemutatok nagyon meggyozoek. En biztos kiprobalom.
- A hozzászóláshoz be kell jelentkezni
de ez igy nem jó, előbb meg kell várni hogy a windowsba és a makkosx-be is bekerüljön a dolog. csak utána lehet átvenni a gnomeba vagy a kde-be. mi lesz így kedvenc trolljainkkal? :/
- A hozzászóláshoz be kell jelentkezni
Akárhogy is lesz, jó utód leszel.
It doesn't matter if you like my song as long as you can hear me sing
- A hozzászóláshoz be kell jelentkezni
nem célom felnőni melléd.
vagy izé, le... whatever.
- A hozzászóláshoz be kell jelentkezni
Vannak megoldások hasonlóra máshoz is. Az Apple Spotlight-ja valamelyest hasonló.
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Szerencsére nem kell várnod rájuk, mert már sok-sok éve létezik... ;)
{kind=link}
- A hozzászóláshoz be kell jelentkezni
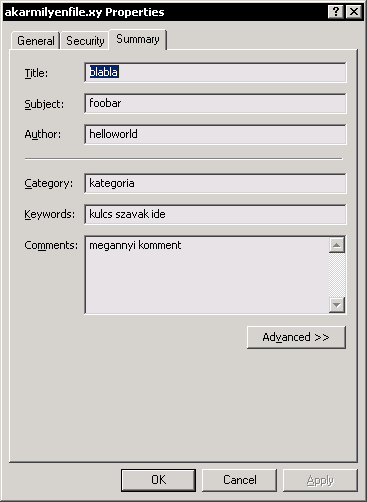
Elfelejtetted barakni azt a képet, ahol pld az "Author" alapján lehet kikeresni a fájlocskákat.
- A hozzászóláshoz be kell jelentkezni
Szerintem nem felejtette el. Trivialitásokról minek csináljon screenshotot? (bár az, hogy ilyen eleve van a Windows XP-ben szintén az :)
- A hozzászóláshoz be kell jelentkezni
> Trivialitásokról minek csináljon screenshotot?
Egy screenshotot ugye csinált. Akkor meg miért ne csinálhatna meg egy másodikat is, a teljesség miatt?
- A hozzászóláshoz be kell jelentkezni
Nem értem mit szeretnél mondani. :)
- A hozzászóláshoz be kell jelentkezni
Nyilván azt, hogy elfelejtette berakni azt a képet, ahol pld. az "Author" alapján lehet kikeresni a fájlocskákat. ;)
init();
- A hozzászóláshoz be kell jelentkezni
Ha szigorúan értelmezzük amit írt, akkor valóban. De ha a sorok között is olvasunk... :)
- A hozzászóláshoz be kell jelentkezni
Gondolom olyan XP-je van, ami a fejlesztés befejezése előtt került ki a gyártótól, és csak beírni tudja az "Author"-t, keresni meg nem ... :-)
- A hozzászóláshoz be kell jelentkezni
Nyilván, főleg mivel ez a feature már a Windows 2000-ben is benne volt. ;)
- A hozzászóláshoz be kell jelentkezni
És egész mostanáig "mesterségesen gerjesztett igény" volt. :-)
It doesn't matter if you like my song as long as you can hear me sing
- A hozzászóláshoz be kell jelentkezni
A kérdés az volt, hogy lehet-e a tag-ekre és megjegyzésekere keresni. Ha lehet, akkor hogyan, és hol van róla a screenshot. Ha jól értettem. Erre kaptunk már választ?
Én még esetleg megkérdezném a rating funkciót, és az egyes file-ok tulajdonság fülén levő azonnali megjelenítést.
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Nem kívánok online support lenni, hogy állandó screenshotokkal és Windows alapismeretekkel lássalak el téged és a fluffereidet, remélem megérted. Kiváncsiságaid kielégítésére tudom ajánlani az MS leírásait és a keresők használatát.
{kind=link}
- A hozzászóláshoz be kell jelentkezni
Elnézést, ez nem támadás volt (paranoia?) csak próbáltam segíteni megérteni az egyenes kérdést, mert úgy láttam, hogy nem ment illetve mellébeszélés szaga volt.
Néhány kérdés: Az első képen levő Windows Desktop Search az része az alap Windows telepítéseknek? A második az nem Vista ablak?
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Nem vagyok windows mágus, viszont az alap search keres ezekben az információkban is, viszont azt nem tudom, hogy szűrni lehet-e vele (azaz pld. csak author szerint keresni, nyilván Kovács Béla-ra keresve nem csak azok a doksik fognak megjelenni, amelyek metaadatai tartalmazzák az author: Kovács Béla propertyt).
A WDS nem része, cserébe a GDS és minden más desktop search is képes ezeket (indexelve, vagy anélkül) keresni, tehát az állítás ettől függetlenül helyes: évek óta benne van az OS-ben.
Teljesen másnak érzem a helyzetet: a Windows esetében ilyet alapból tudsz tárolni és ezt az információt sok programon át tudod keresni, a KDE-nél ezt a KDE adott fájlkezelőjével tudod megtenni és kész.
A fragmentáltságnak ez a hátránya, nem igazán terjednek az ilyen jellegű innovatív dolgok, mert elég nehéz a teljes láncban, mindenhol elérhetően implementálni és széleskörűen elterjeszteni. :(
- A hozzászóláshoz be kell jelentkezni
Ilyen alapon a Linux terjesztésekben is van évek óta. Úgy hívják, hogy Beagle.
Valószínűleg ez zavart meg engem:
""és csak beírni tudja az "Author"-t, keresni meg nem ... :-)""
"Nyilván, főleg mivel ez a feature már a Windows 2000-ben is benne volt. ;)"
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
s/Linux/Gnome
It doesn't matter if you like my song as long as you can hear me sing
- A hozzászóláshoz be kell jelentkezni
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Ez igaz, ehhez is lehet frontendeket írni. Ja, és a Beagle-el csak visszaolvasni tudod a metaadatot, vagy szerkeszteni is? Ha az előbbi, akkor faszán összehasonlíthatjuk az Acrobat Suite-ot az xpdf-el is. :-)
It doesn't matter if you like my song as long as you can hear me sing
- A hozzászóláshoz be kell jelentkezni
Nem erről beszéltünk.
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Most az van, hogy van-e értelme az összehasonlításnak vagy nincs. Mivel a Windows natív megoldást kínál mindkettőre (keywords, author, kiskutyafasza), a Beagle meg nem, ezért...
It doesn't matter if you like my song as long as you can hear me sing
- A hozzászóláshoz be kell jelentkezni
Arra kéne emlékezni, hogy honnan indult a beszélgetés, ugye?
Lehet keresni alap Windows (2000) keresővel (állította valaki, hogy beépített volt már a Windows 2000-ben is) az Author-ra, megjegyzésre (nem külső programokkal, mert nem ez volt az állítás)? Ez volt a kiinduló kérdés. Tehát a válasz: ....
Te jössz.
Ha igen, akkor le is zárhatjuk. Ha nem, akkor is. Csak jó volna már végre tudni.
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Én nem tudom, nem szoktam használni ezeket. De utánanézek.
It doesn't matter if you like my song as long as you can hear me sing
- A hozzászóláshoz be kell jelentkezni
>> Ilyen alapon a Linux terjesztésekben is van évek óta. Úgy hívják, hogy Beagle.
nem olyan sok éve, csak amióta linuxon is a legdinamikusabban fejlődő fejlesztői platform egy ms technológia lefénymásolása
(Beagle is written in C# using Mono)
- A hozzászóláshoz be kell jelentkezni
Ami jó illetve életképes, azt nem kell újra feltalálni. Semmi problémám vele. A Microsoft sem maga sz.rta az összes technológiát amit használ, nemde?
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
természetesen nem, azok már mind másodkézből kerülnek majd az alap linuxterjesztésekbe
- A hozzászóláshoz be kell jelentkezni
Teszemazt?
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
hup-tény, hogy gates úgy lopta a guik szent tekercsét start menüstől
- A hozzászóláshoz be kell jelentkezni
Nemtom, én olyasmikre gondolok, mint a Veritas féle volume menedzsment (ami miatt tán még per is volt). De ez mellékszál.
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Érdekes, hogy ha a M$ ellen használják, akkor milyen jó is tud lenni ez a patent...
It doesn't matter if you like my song as long as you can hear me sing
- A hozzászóláshoz be kell jelentkezni
Nem erről beszéltünk. És nem állítottam a patent-ekről semmi ezen beszélgetés során. Please hanyagoljuk a mellékszálakat.
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Linuxnál ugye elég nehéz azt mondani, hogy valami alapból van, vagy nincs. :)
Ja, végülis a beagle valami ilyesmi, már persze ha van hozzá extended attributes a fájlrendszeren (bár ez a megközelítés azért más, mint a Windows esetén).
- A hozzászóláshoz be kell jelentkezni
Hm. Kicsit elmegyek grillkolbászt sütni meg sörözni és mindjárt micsoda csetepaté alakul itt ki. :) De azért a fenti szórakoztató szálból lejött annyi, hogy a Windowsban alapból van valami - ezt ugye tudtuk -, de visszakeresés, szűrés, rating, pláne bővíthetőség szempontjából nem az igazi, tehát erős túlzás szemantikus desktopnak nevezni. (Nem véletlenül próbálkozott a Microsoft a WinFS-el.) A KDE/GNOME pedig próbálkoznak, de arról meg nem kell azt hinnünk, hogy újdonság (pláne nem, hogy forradalmi újdonság).
init();
- A hozzászóláshoz be kell jelentkezni
De azért a fenti szórakoztató szálból lejött annyi, hogy a Windowsban alapból van valami - ezt ugye tudtuk -, de visszakeresés, szűrés, rating, pláne bővíthetőség szempontjából nem az igazi, tehát erős túlzás szemantikus desktopnak nevezni.
Neked ez jött le, mert ezt akartad hogy lejöjjön. Gondolkoztam egy ideig, hogy írok kicsit mélyebben a témában, kezdve a NTFS streamekben tárolt attribútumokról, amelyekben ezek a file tulajdonságokat leíró információk is vannak, az ennek köszönhető dinamikus bővíthetőségről, az elosztott filerendszerben is működő, hálózatban is használható kereső rendszerről, a teljes indexeléses architektúráról és az ennek köszönhető könnyű scripthelhetőségről, és hogy miért nem erőltették ezt eddig desktopon és épp ezért miért leegyszerűsített a frontend az Explorer-ben (azon kívül, hogy az átlag felhasználó nem érti a különbséget az AND és az OR között és a sokféle tulajdonság, amely alapján keresni lehet csak elbizonytalanítaná), de rájöttem, hogy totálisan feleslegesen tépném a számat (illetve koptatnám a billentyűzetet), mert itt az okosok úgyis megmondják előre, hogy ez a "szemantikus desktop" biza nem buzzword, hanem linux-innováció és máshol még csak hasonló sincs és nem is lesz...
- A hozzászóláshoz be kell jelentkezni
Nem arra céloztam, hogy a Windowsban lévő infrastruktúra ne adna rá lehetőséget (vagy ne lehetne ilyen irányban bővíthető), hanem azt, hogy jelenleg a felhasználó számára nincs elérhető kényelmes megoldás, ami van az nem az igazi. (Még mindig azt mondom: a Microsoft nem véletlenül próbálkozott a WinFS-el, többek között azért akarta adatbázisba tenni a fájlokat, mert éppen a tagelés, a rating és ezek felhasználó általi bővíthetősége egy hierarchikus fájlrendszerben nem megfelelően megoldható, és sokezer fájl esetén lassú. -> még mindig nem mutattál képet ahol az Author-ra tudunk keresni, szűrni :-P)
okosok úgyis megmondják előre, hogy ez a "szemantikus desktop" biza nem buzzword, hanem linux-innováció és máshol még csak hasonló sincs és nem is lesz
A szemantikus desktop tényleg nem buzzword, és csak dikki állította, hogy kizárólag (vagy elsőként) linux-on foglalkoznak/foglalkoztak ezzel (lásd pl. BeOS, vagy mégkorábban Apple - és igen, külön a Te kedvedért - a Microsoft). Magamtól idézek: "A KDE/GNOME pedig próbálkoznak, de arról meg nem kell azt hinnünk, hogy újdonság (pláne nem, hogy forradalmi újdonság)".
Az viszont tagadhatatlan, hogy a KDE projekt legalább foglalkozik vele, ráadásul céges segítséggel. Én ennek örülök, akkor is, ha ez nem original Linux innováció.
init();
Jav.: ...és senki nem állította, hogy kizárólag.... Ja, visszaolvasva dikki állította, bocs. (De akkor vele beszéld meg.)
- A hozzászóláshoz be kell jelentkezni
Látom az online ügyfélszolgálatosunk beguglizta magát a témába. :-) Ez derék dolog, s mint minden más személyes teljesítmény, dícséretet és tiszteletet érdemel.
Szánalmas ez a magyarázkodás. A "leegyszerűsített a frontend" azzal ekvivalens, hogy csak félig csinálták meg. "Az átlag felhasználó"-t meg fehér nyuszika módjára időnként előhúzza a marketing droid a kalapból, csak manapság már a gyerekek közül is egyre kevesebben sem dőlnek be az ilyen trükköknek.
- A hozzászóláshoz be kell jelentkezni
>> "Az átlag felhasználó"-t meg fehér nyuszika módjára időnként előhúzza a marketing droid a kalapból, csak manapság már a gyerekek közül is egyre kevesebben sem dőlnek be az ilyen trükköknek.
mint ahogy azt az elmúlt 15 év marketshare adatai is mutatják
>> csak félig csinálták meg
vagány szavak egy linuzblogban
- A hozzászóláshoz be kell jelentkezni
...az elmúlt 15 év marketshare adatai...
...amelyek az előző 10 év során felépített monopólium következményei. De ezt már egyszer megbeszéltük.
vagány szavak egy linuzblogban
Ott a pont.
init();
- A hozzászóláshoz be kell jelentkezni
http://www.zeneszoveg.hu/dalszoveg.phtml?szk=17455
"65 kiló, 166 cm magas, barna hajú, barna szemű, várható életkora 60 év felett van, ..."
Te találkoztál már Á.F. kollégával? Mer én még nem.
Igazad van, a "leegyszerűsített felhasználói interfész" jobb, mert azon túl, hogy ugyanazt jelenti mint a "féligkész", legalább vicces.
Persze lehetne még javítani rajta, pld az "Á.F. kolléga számára optimális felhasználói élményt biztosító grafikus felület" még viccesebb lenne. :-)))
- A hozzászóláshoz be kell jelentkezni
Eredetileg arról volt szó, hogy ezt a KDE team találta fel. Ahhoz képest ilyeneket már lehet használni 2001 óta a Windowsban (onine fórumok tele vannak a keywords cuccal, vajon miért).
It doesn't matter if you like my song as long as you can hear me sing
- A hozzászóláshoz be kell jelentkezni
> Eredetileg arról volt szó, hogy ezt a KDE team találta fel.
Idézni csak pontosan, szépen ...
> Ahhoz képest ilyeneket már lehet használni 2001 óta a Windowsban (onine fórumok tele vannak a keywords cuccal, vajon miért).
Ahhoz képest egy wintroll sem volt képes egy képet felmutatni az "Author" bejegyzések kikeresésről. Valahogy csak guglival jönnek elő ezek a dolgok. Vajon miért?
- A hozzászóláshoz be kell jelentkezni
http://bayimg.com/BaDKKAAbo
It doesn't matter if you like my song as long as you can hear me sing
- A hozzászóláshoz be kell jelentkezni
Ne segíts neki, hagy lovagoljon még egy kicsit ezen és égesse szénné magát...
- A hozzászóláshoz be kell jelentkezni
Figyeld meg, hogy meg fogom kapni, hogy frenkizek. Egyébként olyan buli, hogy zipek is vannak, pedig becsszavamra, nem direkt volt. :-)
It doesn't matter if you like my song as long as you can hear me sing
- A hozzászóláshoz be kell jelentkezni
Nem, most az jön, hogy "de hol a ráting?!?!" :)
- A hozzászóláshoz be kell jelentkezni
Az nem csak visztában van?
(Egyébként én vagyok a hülye, hogy belemegyek ilyen szarokba, mikor ezek annyira nem érdekelnek, a könyvtárakat minden OS ismeri, és nekem jó a desktop 1.0 is.)
It doesn't matter if you like my song as long as you can hear me sing
- A hozzászóláshoz be kell jelentkezni
Én se használom és mint írtam is ez első sorban nem desktop célokra lett kitalálva... Egy elektronikus könyvtárat elosztott filerendszeren így felindexelve viszont eltudok képzelni, hogy jó. Nálunk a levelezés van hasonlóképp megoldva, de érhető módon nem a Windows Search keres a levelek között, hanem az Outlook. :)
- A hozzászóláshoz be kell jelentkezni
Olvastam valahol, hogy bár a beépített search nem a legjobb, meg nem opensource a Win, de a search API borzasztó jó. Nem vagyok programozó, így nem tudom megítélni...
It doesn't matter if you like my song as long as you can hear me sing
- A hozzászóláshoz be kell jelentkezni
Kimaradt a hozzászólásodból a konklúzió. Hogy a kép tanúsága szerint ...
- A hozzászóláshoz be kell jelentkezni
...használható.
It doesn't matter if you like my song as long as you can hear me sing
- A hozzászóláshoz be kell jelentkezni
Itt a vége.
- A hozzászóláshoz be kell jelentkezni
Konklúzió: már az XP-be is tettek ilyet, és használható.
It doesn't matter if you like my song as long as you can hear me sing
- A hozzászóláshoz be kell jelentkezni
"Szánalmas ez a magyarázkodás. A "leegyszerűsített a frontend" azzal ekvivalens, hogy csak félig csinálták meg. "Az átlag felhasználó"-t meg fehér nyuszika módjára időnként előhúzza a marketing droid a kalapból, csak manapság már a gyerekek közül is egyre kevesebben sem dőlnek be az ilyen trükköknek."
valamiert en egybol a gnome-ra asszocialtam :D
--
Those who do not understand Unix are condemned to reinvent it, poorly. (based on true story)
- A hozzászóláshoz be kell jelentkezni
A "leegyszerűsített a frontend" azzal ekvivalens, hogy csak félig csinálták meg.
Nyilván, hisz hihetetlen nagy meló lenne, de sajnos te ezt nem érheted a Greasemonkey scriptjeiddel.
"Az átlag felhasználó"-t meg fehér nyuszika módjára időnként előhúzza a marketing droid a kalapból, csak manapság már a gyerekek közül is egyre kevesebben sem dőlnek be az ilyen trükköknek.
Mondja ezt az a nem átlag felhasználó, aki nem tudja megkülönböztetni az NTFS transzparens tömörítést, a ZIP-től... :)))
Szálljál már magadba, ember.
- A hozzászóláshoz be kell jelentkezni
> Nyilván, hisz hihetetlen nagy meló lenne,
Értem. Hihetetlen nagy meló.
Mostanában perl kódokat küldözgetek, így inkább: "de sajnos te ezt nem érheted a Greasemonkey és Perl scriptjeiddel."
Szálljál már magadba, ember.
- A hozzászóláshoz be kell jelentkezni
Majd szólj, ha már nem csak scripteket irogatsz... ;)
- A hozzászóláshoz be kell jelentkezni
> Nem kívánok online support lenni, ...
Kár, mer lenne rá igény.
- A hozzászóláshoz be kell jelentkezni
Ezt már én is észrevettem. ;-)
It doesn't matter if you like my song as long as you can hear me sing
- A hozzászóláshoz be kell jelentkezni
És mit kívánsz tenni (ellene, mellette) ?
- A hozzászóláshoz be kell jelentkezni
itt vagy te nekunk guglizni, ugyhogy nincs gond
- A hozzászóláshoz be kell jelentkezni
Lamaradtál, Hunger már rég kiguglizta :-)
- A hozzászóláshoz be kell jelentkezni
Eddig amolyan "városi legenda" ez a fícsör, a sógor szomszédjának a munkatársa hallotta a buszon, hogy valaki azt mondta, hogy egy helyen azt írták, van a W2K-ban egy ilyen fícsör. :-)))
- A hozzászóláshoz be kell jelentkezni
Ja, mint a zipfs. :-)
It doesn't matter if you like my song as long as you can hear me sing
- A hozzászóláshoz be kell jelentkezni
Nálam még mindíg az mc a nyerő.
- A hozzászóláshoz be kell jelentkezni
Azért alapjaiban véve ennek is az a buktatója, hogy valaki (azaz TE a user) hozzácsatolja-e azokat a bizonyos TAG-eket, azaz a metainformációkat megadja-e. Mert ha nem, akkor a projektet tűzheted a kalapod mellé.:-)
- A hozzászóláshoz be kell jelentkezni
Az ember alapvetően LUSTA lény.
A szemantika már csak a második jellemzője a fontossági sorban ;)
- A hozzászóláshoz be kell jelentkezni
és éppen emiatt lusta feltagelni is a sok ezer file-ját visszamenőleg.
--
Peace, Love, Unity, Respect
- A hozzászóláshoz be kell jelentkezni
Még szerencse, hogy új felhasználók is vannak, és ez elsősorban őket célozza, nyilván Te meg én már tudjuk, hogyan rendszereztük őket.
It doesn't matter if you like my song as long as you can hear me sing
- A hozzászóláshoz be kell jelentkezni
Pld. a 800 pixelnél szélesebb képek kereséséhez remélhetőleg nem kell majd kézzel beírni a képek szélességét.
- A hozzászóláshoz be kell jelentkezni
Az, hogy az ember szemantikus hálóval gondolkodik, az nem feltétlenül jelenti azt, hogy egy külső dolgot is így lát át legjobban. Egy faszerkezet szerintem sokkal szemléletesebb, mint egy általános irányított gráf, amit igazol, hogy az emberek által alkotott (pl. tudományos) rendszerek mindig is nagyrészt faszerkezetűek voltak.
Az az 1-5 Ranking a legtöbb esetben elég értelmetlennek/jelentéstelennek tűnik.
- A hozzászóláshoz be kell jelentkezni
Hol tárolódnak ezek a metaadatok? Mivel nem fájlrendszerszinten működik a dolog, egy fájlrendszer-átrendezés, rendszer-újratelepítés, egy-egy könyvtár átmásolása másik gépre (főleg nem KDE alkalmazásokkal) nem kuszálja össze az egészet?
- A hozzászóláshoz be kell jelentkezni
A belinkelt cikkekben, oldalakon le van írva minden:
The current implementation of Nepomuk-KDE contains an implementation of an RDF repository which stores all the data. According to Sebastian the data can be accessed by DBUS which is the default way to communicate in Nepomuk-KDE (of course).
[...]
The definitions (aka Ontologies) how the data like tags, comments and so on should be stored in the repository can be found in kmetadata/ontologies in KDE’s svn or in the directory $KDEDIR/share/apps/knepomuk/ontologies if you install kmetadata on your hard disk.
A cikk itt.
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Köszönöm, átsiklottam rajta. E szerint viszont gyanús, hogy ha nem KDE eszközökkel rendezem át a home könyvtáramat, akkor elszállnak a metaadatok.
- A hozzászóláshoz be kell jelentkezni
gyanús, hogy ha nem KDE eszközökkel rendezem át a home könyvtáramat, akkor elszállnak a metaadatok
Lehet, hogy lenne értelme a fájlrendszerhez kötni a tagelést, commentelést stb. Ebben az esetben tetszőleges utilityvel mozgatva az állományokat a metainformációk is követnék az állományt. Windowson a WinFS-nek nem lettek volna ilyen képességei?
init();
- A hozzászóláshoz be kell jelentkezni
A Vista-ban akartak ilyen filerendszert aztán (többek közt) pünkt ez nem valósult meg belőle.
Ha ez a szemantikai dolog nem filerendszer szinten kötődik a file-hoz akkor nem túl használható a dolog.
- A hozzászóláshoz be kell jelentkezni
a WinFS pont ez lett volna ;)
meg reiser4.
- A hozzászóláshoz be kell jelentkezni
Nem feltétlenül kell fájlrendszer szinten megoldani, lokális adatoknál az oprendszer szinkronban tudja tartani a fájlrendszeren történt változásokat (áthelyezés, átnevezés,...) és a szemntikai adatokat tároló adatbázist, így fájlrendszerfüggetlen lenne. Persze, hálózaton lévő adatokkat már problémásabb lenne, oda tényleg fájlrendszer szinten kell megoldani. Bár, ha az adatbázis a fájlrendszeren van tárolva és mindenki hozzáfér és mindegyik op támogatja és ha kevesebb lenne a ha :)
- A hozzászóláshoz be kell jelentkezni
> A Vista-ban akartak ilyen filerendszert
Régebbi történet ez annál:
- A hozzászóláshoz be kell jelentkezni
- A hozzászóláshoz be kell jelentkezni
Sok fájlrendszer támogatja a metaadatok hozzárendelését a fájlokhoz (pl ext3 is).
Beagle is használja ezt, ha támogatja a fájlrendszer.
Nem is értem, a NEPOMUK miért nem használja ezt.
A WinFS ennél jóval több lett volna: adatbázisban tárolna minden fájlt, mindenféle metaadattal együtt, amiben a keresés egy lekérdezés lenne. Ezt elég komolyan kell támogatnia az oprendszernek meg az összes programnak is. De szvsz mindenképp ilyesmi a jövő.
- A hozzászóláshoz be kell jelentkezni
végre! Ha máshol nemis, de a homeomban végre felszámolhatom a könyvtárstruktúrát.
- A hozzászóláshoz be kell jelentkezni
Interju Sebastian Trüg-el (K3b) a Mandrivarol es a K3b-rol es a Nepomuk-rol:
http://newsvac.newsforge.com/newsvac/07/05/10/2117226.shtml
--
B+ - http://pozor.hu
- A hozzászóláshoz be kell jelentkezni
Basszus én meg már azt hittem a cím alapján, hogy kitaláltak valamit. :(
- A hozzászóláshoz be kell jelentkezni
izes frenglish narracioval ;)
- A hozzászóláshoz be kell jelentkezni
Es ez hogy menti a kommenteket meg az egyeb bejegyzeseket?
Mert ha az en fajlaim egy pendrivon vannak, amit tobb gepen is elerek, akkor ugyanugy meglesznek ezek a bejegyzesek?
Mert azoktol a programoktol hulyek kapok, amik csinalnak egy kis fajlt minden konyvtarba es abba irjak a megjegyzeseket. Alltalaban kepnezegetok ilyenek. Szoval ezt magukba a fajlokba kellene tarolni. Mert ha masolom a fajlokat, akkor is jo lenne ha megmaradnanak.
- A hozzászóláshoz be kell jelentkezni
Pont ezt a problémát akartam felvetni. Ez az egész akkor lehet kényelmes, ha a fájlokkal együtt le tudom másolni a metaadatokat is. Iszonyú gáz, ha mindenkinek újra kell indexelnie a saját elképzelése szerint.
Mondjuk a helyi svn repository kecsegtet némi lehetőséggel, hogy esetleg az egy központi svn repository legyen, amibe mindenki beletegelhet, és mindenki lát mindent.
--
Simplicitas Sigillum Veri
- A hozzászóláshoz be kell jelentkezni
Ezzel az egészel csupán csak az a baj, hogy köszönő viszonyben sincs a Szemantikus hálóval, mint a mesterséges intelligencia kutatás egy alkalmazott modelljével!
Szemantikus hálókról itt van némi tudásanyag:
http://www.math.klte.hu/~bognar/mestint4/szemanti.htm
http://www.mek.iif.hu/porta/szint/tarsad/konyvtar/informat/azinform/htm…
http://www.agent.ai/?folderID=166&articleID=1454&ctag=&iid=
http://www.index.hu/tech/tudomany/mestiq3/
és ezek után jöhet a könyvtárnyi szakirodalom...
Így ennek semmi összefüggése nincs a tudásbázis alapú mesterséges intelligencia kutatás folyamán bevezetett szemantikus háló fogalmával, amit a programírók megvalósitottak az nem szemantikus háló!
Kár úgy átvenni egy marketing cikket, hogy nincs tudományosan ellenőrizve, még akkor is ha az egy populális WEB médiumon jelent meg.
Tanulság: tudományos publikációkat a tudósok tollából várjunk, ne IT managerektől!
- A hozzászóláshoz be kell jelentkezni
Az első linked be van linkelve a cikkben. Ezt írja:
A kognitív pszichológiai kísérletek alapján a kutatók azt feltételezték, hogy az emberek tárgyköri ismereteiket háló formájában tárolják. Bebizonyosodott, hogy az általános tulajdonságok nem az egyes egyedekhez kapcsolódnak, hanem mindig az adott osztályszintjen rögzülnek. Tobbszintű osztályozás esetén pedig a jellemzőket a lehető legmagasabb szinten jegyezzük be, ahol már érvényesek.
1. Tud-e a kanári énekelni?
2. Tud-e a kanári repülni?
3. Vane a kanárinak bőre?A kísérlet tanúsága szerint az embereknek több időre van szükségük a 2. kérdés megválaszolására, mint arra, hogy az 1.-re feleljenek, és még több a 3. kérdés megválaszolására. Az éneklés képességét az ember a kanárihoz társítja, a repülést a madarak általános képességeként tartjuk nyilván, míg az hogy bőre van, minden állatra jellemző, ezért ennek megválaszolására előbb gondolatban megteszi a kanári ---> madár ---> állat utat.
Látok rációt, hogy a file-ok egyszerűbben jegyezhetők meg a tulajdonságaikról, mellé írt megjegyzésekből, mint az egyszerű filenevekből, így nem értek egyet veled.
--
trey @ gépház
- A hozzászóláshoz be kell jelentkezni
Igen valóban így lehet, bár megjegyzem NEPOMUK-hoz hasonló kisérletek eddig mind elhaltak.
Másrészt jól látható hogy a NEPOMUK-al a user egy kapcsolati hálót épít fel, nem pedig egy Szemantikus Hálót. Hiányzik a gép oldaláról az a mesterséges intelligencia -amit a programozó kódol bele-, amit szementikus háló gráfjainak élei jelképeznek. Így csak az obejuktomok kapcsolati hálójáról beszélhetünk.
Hasonlóan mint az IWIW: azt nem fogja megmondani a hw/sw hogy ki az ismerősöm/barátom csupán csak azt fogja megmondani hogy ki kivel áll kapcsolatban. Pedig elvileg ha több intelligenciát kódoltak volna az iwiw-be, akkor az érdeklődési kör, a közös óvoda/iskola/munkahely/lakhely, és egyéb életparaméterek alapján megmondhatná azt hogy Bálint Antónia bartátja, esetleg barátnője lehet -e Arany Jánosnak? A mostani rendszerben akár elképzelhető lehetne a hibás pozitív válasz is a kérdésre; ami nekünk embereknek egyértelmű: Nem lehettek barátok, és nem találkozhattak egymással sem mert nem egy időben éltek.
Egy szemantikus rendszerben elképzelhetetlen az objektumok közötti kapcsolatok direkt manipulálása, hiszen a rendszer intelligenciájának növelésével (tanításával) lehet a rendszert tökéletesíteni. Az iskolában a tanítónéni is tanítja a diákok szemtikus agyát, nem pedig a dolgozatokat (outputot) írja át / állítja be megfelelőre, hogy aztán elmondhassa hogy minden tanuló megfelelően intelligens lett.
Ezért mondom azt hogy a szemantikához nincs köze a NEPOMUK kapcsolati hálójának, és szerintem a NEPOMUK rosszul teszi hogy összkeveri (gondolom szándékosan, és marketing céllal) a fogalmakat.
- A hozzászóláshoz be kell jelentkezni