A C fordító (gcc, clang) normál esetben megdöbbentően jól fordít, kár hozzányúlni assembly szinten.
Akkor kell hozzányúlni, ha spéci dolgot szeretnénk elérni, amit a C fordító semmiképpen nem ért meg, és azzal nem +3%-ot, hanem akár +100%-ot is nyerünk és van eset, amikor ez szükséges.
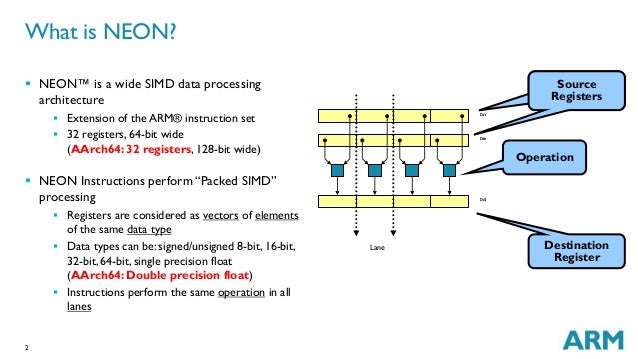
Ilyen amikor valójában mélyebb optimalizáció kell. Például a fent írt vektorprocis témánál ott nyersz sokat, ha kockás papír - ceruza és ügyesen használod a 16 AVX regisztert vagy a 32 darab NEON regisztert, ezzel memóriaműveletet spórolva. Főleg ARM procikon jellemző, hogy a proci nagyon gyors de a RAM visszafog. Ezt az átfogó, már algoritmus átdolgozást is tartalmazó mutatványt nem lehet simán C fordítóval megoldani.
Tehát valójában nem az algoritmus fordítása, hanem az algoritmus és a regiszterszám (16 darab ill. 32 darab) összhangba hozása a varázslat. Lényeg, hogy az aritmetika során minél kevesebb legyen a RAM művelet.
Lásd még: https://en.wikipedia.org/wiki/Advanced_Vector_Extensions#Advanced_Vecto… ... AVX2 jellemző, AVX512 a procik kis arányában (főleg XEON-ok).
ARM Cortex A.. esetén: https://image.slidesharecdn.com/tphcc6ianrickardsneonopensymposia-14120… ... 64 bites módban dupla annyi NEON regiszter érhető el.
{kind=link}