- A hozzászóláshoz be kell jelentkezni
Hozzászólások
Ezen már az Android is használható talán.
- A hozzászóláshoz be kell jelentkezni
Ennek inkább driver hiányosságai voltak eddig is. Azaz rendes opengl/es driver kell alá, hogy menjen. És az sem hátrány, ha a multimédiás képességeit ki lehet használni, mert különben csak egy proci erőből izzadó eléggé minimálisan használható eszköz lenne.
- A hozzászóláshoz be kell jelentkezni
Lol, pedig hogy tagadták :D
Lassan már egy armos windows is el tud futni rajta. (az IOT core az eléggé korlátozott)
https://www.hwsw.hu/hirek/61825/windows-10-iot-core-enterprise.html
"az Enterprise variáns már "teljes értékű Windowsként" működött"
- A hozzászóláshoz be kell jelentkezni
És ez már fog tudni usb/ssd-röl bootolni? :)
"Biztos én vagyok a béna, de csak azt sikerül elérnem, hogy kikapcsol a monitor."
- A hozzászóláshoz be kell jelentkezni
A pi4 -eknek már flash chipben van az a szoftver, ami ezeket kezeli. És szoktak kiadni frissítést hozzá.
Nemrég jött ki a béta változata az új eprom update-nek, kicsit még gányolós a leírás szerint, de ha stabil verzió kijön, akkor másolgatás nélkül is megy
https://www.tomshardware.com/amp/how-to/boot-raspberry-pi-4-usb
- A hozzászóláshoz be kell jelentkezni
Látom neked is hiányzik a microSD-nél fürgébb háttértároló.
Én ezért (is) tértem át Odroid-ra. Az eMMC sokkal fürgébb, főleg apró fájlok esetén.
Továbbá az Odroid-nak alapból normális a hűtése. Sajnos ezeket a procikat ha 4 magon rendesen terheled, akkor már kell a normális borda rájuk.
- A hozzászóláshoz be kell jelentkezni
En toluk vettem kb 1 hete: https://rlx.sk/en/
89 euro volt az Odroid-C4 + haz + tap + szallitas (Romaniaba). Egyeduli hatrany, hogy nem lehet kartyaval fizetni, csak banki utalassal.
- A hozzászóláshoz be kell jelentkezni
https://www.pollin.de/ -ről vettem a C2-est, korrekt szállítás 10 Euróért, postán vettem át.
- A hozzászóláshoz be kell jelentkezni
A fürgeség csak egy dolog, de a kifejezetten ipari kártyákat kivéve nincs wear leveling a sima kártyákon, így megpusztulhat, ha intenzívebben használják. Egyébként pi4-re pont lehet kapni olyan passzív bordát, amit szendvicsként a két oldalára lehet csavarozni.
Nem rossz az odroid, csak mivel kevésbé elterjedt így kevesebb kulcsra kész rendszer van hozzájuk. Chipsettől függően akár sokkal régebbi is lehet a kernel, amivel használni lehet őket. Vagy ha mondjuk armbian-t használ valaki, akkor a multimédiás képességeket nem tudja kihasználni, mert azok a mainline kernellel hiányoznak.
De persze mindegyiknek megvan a maga piaca. A pi amolyan univerzális dolog. Sokmindenhez jó, de egyikre sincs kifejezetten kihegyezve. Az odroidból meg van olyan is, ami kifejezetten hálózati mini nas vagy épp más célfealadra készített.
- A hozzászóláshoz be kell jelentkezni
A wear levelingen az F2FS használata segíthet, illetve OverlayFS adott esetben csodákra képes. :)
- A hozzászóláshoz be kell jelentkezni
Nagyrészt igen. De nem akarok mmc-vel (sem) vacakolni. Rá akarok tenni usb3-on egy olcsó ssd-t, aztán arrol fusson a rendszer. Mint a pi3-nál.
Sajnos amikor utoljára néztem, még nem tudott usb3-rol bootolni, csak sdcard-rol, és hát nyilván megoldható azzal is a boot átdobása, de nah mégis.
"Biztos én vagyok a béna, de csak azt sikerül elérnem, hogy kikapcsol a monitor."
- A hozzászóláshoz be kell jelentkezni
en pont ilyen okbol vettem banana pi m2 ultra lappot, es egy kinai raid boarddal kotottem bele ket ssd-t. emmc-rol bootol a kernel, a root mar ssdn van.
A vegtelen ciklus is vegeter egyszer, csak kelloen eros hardver kell hozza!
- A hozzászóláshoz be kell jelentkezni
Na, akkor innentől van az, hogy van értelmezhető cpu teljesítmény és megfelelő RAM is, tehát bizonyos esetekben kiválthat egy desktopot.
"Sose a gép a hülye."
- A hozzászóláshoz be kell jelentkezni
A ram azért csalóka, mert nem 64 vagy 128 vagy akár még szélesebb buszon ül, hanem talán 16 vagy 32 bit szélesen. Szóval teljesítményben nem éri el a pécés megoldásokat, inkább a tabletesekhez hasonló. Ettől persze még ez is sokmindenre jó. Szóval, akinek pécé kell, az valószínűleg még mindig jobban jár egy pár éves használt üzleti laptoppal hasonló áron - kivéve, ha kifejezetten médiajátszót akar belőle, mert abban gyengébbek a régi pécék a mai h264/h265 és 4k formátumokkal.
- A hozzászóláshoz be kell jelentkezni
A PC nem a DRAM miatt gyorsabb, hanem a cache miatt. Ebben magonként 32/48 KB L1 cache van, és 256KB L2 cache. Egy átlagosnak mondható i5-ös prociban 32KB L1, 256KB L2 és 1.5MB L3 cache van magonként. Tipikus PC-s teszteken a 64 bites DRAM -> 128-bites DRAM átállás csak 10-15% sebességnövekedést hoz.
- A hozzászóláshoz be kell jelentkezni
Nem a dram miatt, hanem a sávszélesség és annak kihasználása miatt gyorsabb. A magasabb órajelű procinak a széles busz jól jön, amikor etetni kell feladattal. Vannak boardok, ahol ugyanolyan ram chipet használnak, mint pécén, csak kevesebb darabot, keskenyebb buszon.
A cache abban segít, hogy a proci futószalagjához már ütemezettebben jusson el az adat vagy a kód, ne kelljen várnia rengeteg órajelet elpazarolva. De ne essünk már át a ló túloldalára. Amikor több adatot kell feldolgozni, akkor már a ram sebessége a szűk kersztmetszet, ha a proci többet is bírna. A 10-15% is úgy jön ki, hogy máshová kerül át a szűk keresztmetszet, mert ott már a proci / gpu nem képes a komplex feladatot gyorsabban elvégezni és kihasználni a ram sávszélességet. Na meg az sem mindegy, hogyan éri el a ramot a proci, régebben azt hiszem pont intelnél nem volt sok értelme az akkori megoldásukkal a több csatornának, mert nem tudta kihasználni a szélesebb buszt. A mai prociknál már jobban optimalizáltak erre.
A pi esetén viszont pár éves desktop proci teljesítményét nyaldosó cpu van párosítva desktopnál fele-negyen olyan széles buszon ülő rammal, amin még a gpu-val is osztozik. Ugyanezt láthatod a tabletes procis és a laptop procis fapados intel gépeknél is (atom és származékai különböző célú változatokkal). Simán van 2x-es szorzó teljesítményben köztük, bár ott lehet a proci nyers teljesítményében is van különbség.
- A hozzászóláshoz be kell jelentkezni
Jó prociban 90% fölött van a "cache hit" aránya: https://www.extremetech.com/extreme/188776-how-l1-and-l2-cpu-caches-wor…
A DRAM sebessége a maradék 5-10%-ot befolyásolja csak. Saját PC-s méréseim szerint a dual channel DDR3 kb. 10% gyorsulást hoz a 64-bites eléréshez képest.
Szerk:
local L1 CACHE hit, ~4 cycles ( 2.1 - 1.2 ns )
local L2 CACHE hit, ~10 cycles ( 5.3 - 3.0 ns )
local L3 CACHE hit, line unshared ~40 cycles ( 21.4 - 12.0 ns )
local L3 CACHE hit, shared line in another core ~65 cycles ( 34.8 - 19.5 ns )
local L3 CACHE hit, modified in another core ~75 cycles ( 40.2 - 22.5 ns )
remote L3 CACHE (Ref: Fig.1 [Pg. 5]) ~100-300 cycles ( 160.7 - 30.0 ns )
local DRAM ~60 ns
remote DRAM ~100 ns
Vagyis az L3 cache hit még mindig 3-5-ször gyorsabb, mint kimenni a DRAM-ba.
- A hozzászóláshoz be kell jelentkezni
persze, hogy gyorsabb a közelebbi, kis késleltetésű cache-t használni. Mindez addig működik is, amíg annyi adattal dolgozol, ami elfér a cache-ben vagy olyan lassan dolgozza fel a proci, hogy a következő adatot elő tudja tölteni a ram-ból. Ha cache méretnél több adat kell, akkor meg kiürülnek a cachek, mert várni kell a dramra. És mindjárt nem mindegy, hogy 100 vagy 1000 MB/sec áttölteni.
Az előtöltés meg persze arra kell, hogy ami várhatóan szintén kell adat, azt is behúzza, nem bájtonként kéregeti a ramból.
Ráadásul nem csak az számít, hogy hány ns elérni a ramot, hanem az is, hogy mennyi adatot tud egységnyi idő alatt betölteni belőle.
Azt kéne megértened, hogy nem mindegy, hogy eleve van egy gyors ramod és azt duplázod pécé esetében, míg beágyazott cuccoknál a gyors ramot negyedeled, nyolcadolod akár sebességben. Persze ideális esetben úgy választják meg a proci és ram képességét, hogy ne legyen kirívó szűk keresztmetszet egyik oldalon sem. Szóval ha a proci elve nem képes kihasználni a 64 bit szélességből adódó nagyobb sebességet, akkor nem hátrány 32 vagy 16 bitre szűkíteni, de olcsóbb gyártani.
- A hozzászóláshoz be kell jelentkezni
Ne felejtsük el, hogy az ARM load-store alapú, ami adott esetben 3x lassabb is lehet az x86-os direkt memória műveleteinél.
Ha valami nem DMA-ból megy és fel kell dolgozni, nincs REP és hasonló CISC nyalánkságok. Leül az ARM hamar a sok mem rw miatt.
http://plazmauniverzum.hu <> A látható anyag 99.999%-a plazma <>
- A hozzászóláshoz be kell jelentkezni
Vannak furcsaságok az x86-hoz képest. Például nézem, mit fordít némi optimalizációs kapcsolóhalmaz mellett a C fordító AArch64 módban az egyik jelfeldolgozó algoritmusomból.
ldr q20, [x5, x1]
ldr q21, [x7, x1]
ldr q22, [x6, x1]
ldr q23, [x11, x1]
ldr q24, [x9, x1]
fmla v28.4s, v20.4s, v21.4s
ldr q25, [x10, x1]
fmla v29.4s, v20.4s, v22.4s
ldr q26, [x8, x1]
add x1, x1, 16
fmla v30.4s, v20.4s, v23.4s
fmla v31.4s, v20.4s, v24.4s
fmla v6.4s, v20.4s, v25.4s
fmla v0.4s, v20.4s, v26.4s
Betölti az [k+i + j]-edik memóriacímről a 128 bites SIMD mintákat, majd a következő SIMD betöltéshez 16-tal (4 float mérete) megnöveli a j indexet. Közben megcsinálja fmla-val 4 float-ra a szorzatösszegeket. Az utasítás sorrend az out-of-order limitációja miatt át lett rendezve. A REP ezen nem segítene, helyette az [k+i + j] index kiszámításából csak a ritkábban kiszámítandó k+i érték okoz pluszműveletet, a ciklusmagban az [x + j] érték számítása ugyanabba az utasításba belefér.
- A hozzászóláshoz be kell jelentkezni
A RAM illesztést jelfeldolgozásnál én is erősen érszrevettem, kritizáltam.
ARM Cortex A53-nál a NEON szintén barom gyors, de nem tudtam etetni mintákkal. Erre az ARM holding is rájött, ARM Cortex A55-nél a RAM illesztésre nagy figyelmet fordítottak.
Az Rpi4-ben levő ARM Cortex A72 is sokkal jobb memória eléréssel rendelkezik első jelfeldolgozós tapasztalataim szerint. Egyetlen hátránya, hogy az ARM Cortex A53..A55 vonalhoz képest erőteljesen melegszik. Főleg ha 4 szálon masszívan kihajtod jelfeldolgozással.
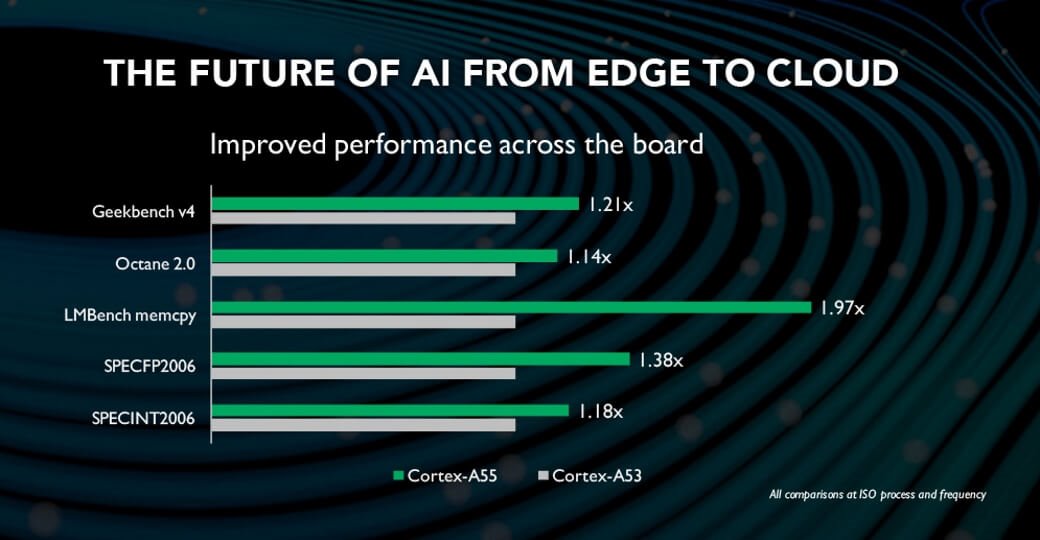{kind=link}
- A hozzászóláshoz be kell jelentkezni
Az A72-ben 3 pipeline van, az A53-ban és A55-ben pedig csak 2.Valamint előbbi tud out-of-order execution-t.
- A hozzászóláshoz be kell jelentkezni
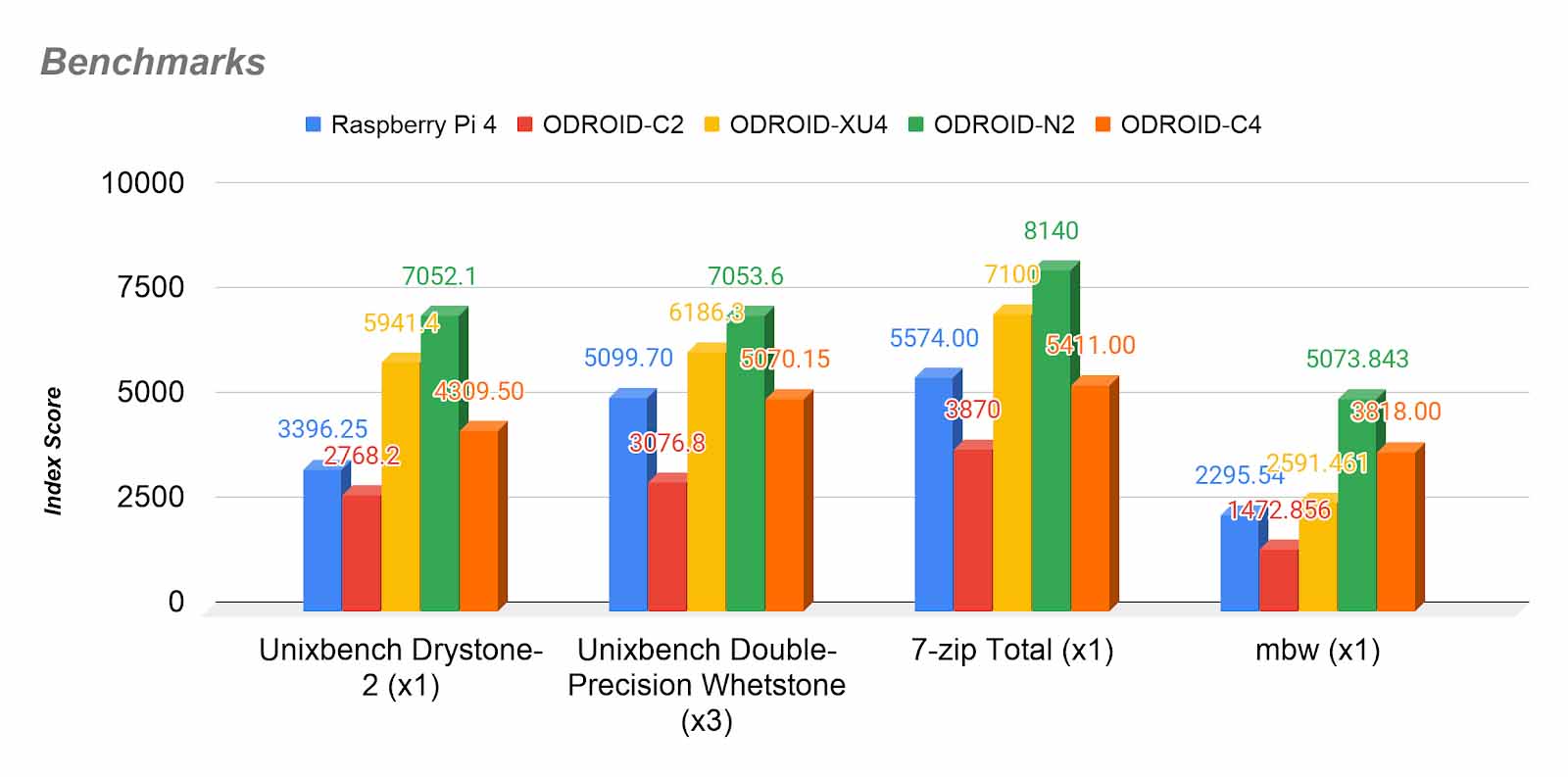
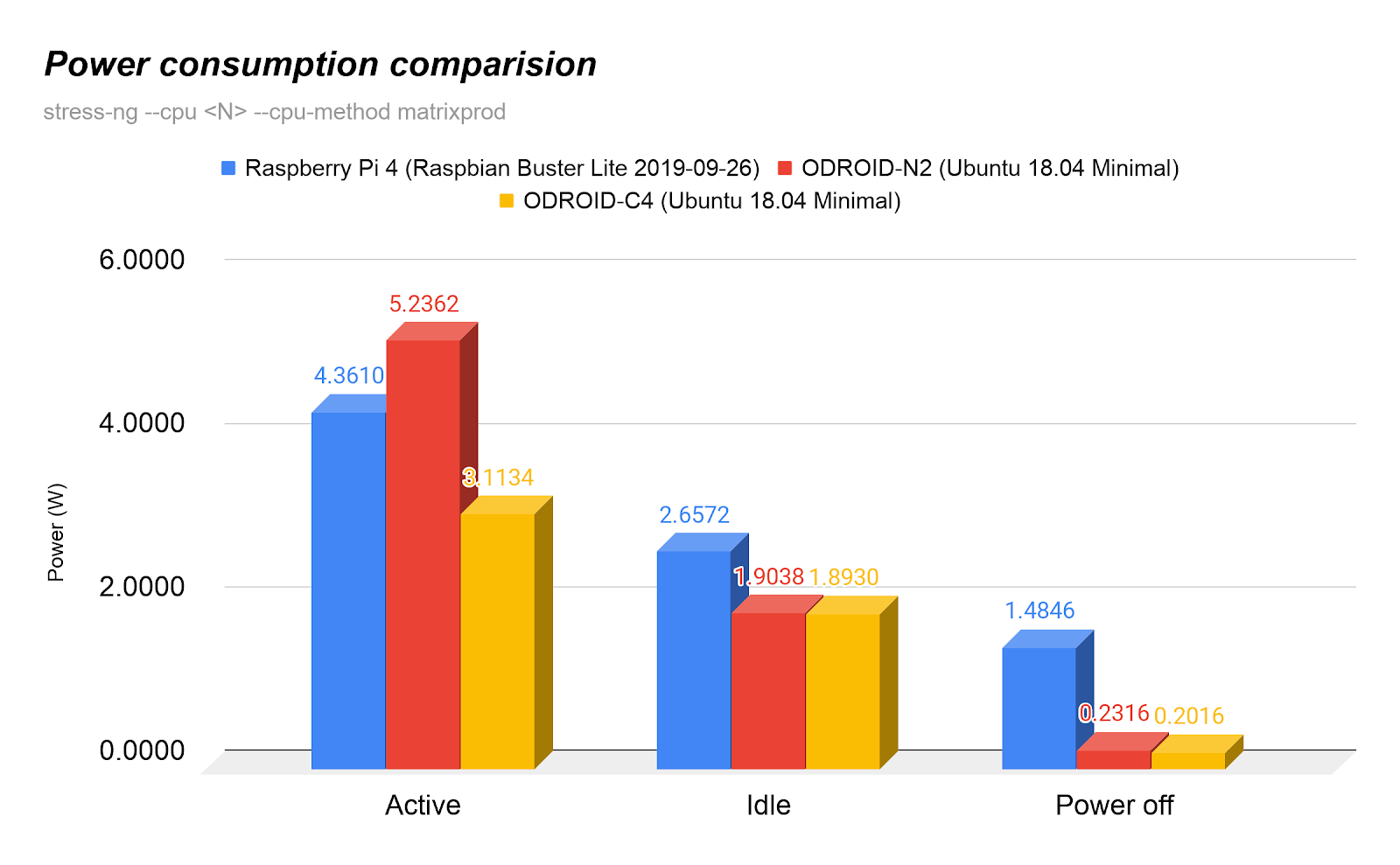
Hiába gyorsabb az architektúra azonos órajelen, ha 3/4 órajelen (1,5 GHz vs. 2 GHz) járatva sem tudod elvinni a hőjét. Ekkor az ARM önvédelme leszabályoz, a lendülete megtorpan (tapasztaltam). Alább két grafikon a számítási teljesítményről és megterhelt lapka fogyasztásáról. Odroid bár terhelve az Rpi4-nél kevesebb hőt disszipál, gyárilag rászorított (jó hőátadású) hűtőbordával érkezik. Rpi4 kétoldalas ragasztós műanyagon keresztül utólag rátapasztott kisebb bordával látható el.
{kind=link}
https://cdn.hardkernel.com/wp-content/uploads/2020/04/odroidc4CPUperfor…
https://cdn.hardkernel.com/wp-content/uploads/2020/04/odroidc4Powercons…
{kind=link}
{kind=link}
- A hozzászóláshoz be kell jelentkezni
Remélem ez elég nagy borda:
- A hozzászóláshoz be kell jelentkezni
- A hozzászóláshoz be kell jelentkezni
RPI 3B+ hűtéssel játszogattam, visszament 600 MHz-re ha melegedett. Akármekkora hűtöborda sem versenyezhetett egy kis borda+ventillátorral.
De én is passziv bordával használom.
- A hozzászóláshoz be kell jelentkezni
Szépen összefoglaltad a lényeget. Egy ilyen RPi-on úgyis limitációkba ütközünk. Az a combosabb feladat, ami tényleg igényelné a 8 giga RAM-ot, ahhoz valószínű a proci lesz gyenge, meg a buszsebesség limitál. Persze ennek ellenére elfér, legalább nem kell swap, meg végül is 75 dollárért nem adják drágán, így miért ne, de értelme nincs túl sok hasznosság szempontjából.
Ez már az én i5-2520M-es ThinkPad X220-amon is előjön, hogy hiába tettem bele 2×8 GB DDR3 RAM-ot, amihez ilyen sok kéne, ahhoz a proci lesz gyenge, így a nagyja az idő java részében kihasználatlanul áll. De anno kimaxoltam (akkor még i7-2620M volt benne), ha már upgrade-eltem, hogy a jövőben le legyen róla a gond.
“A computer is like air conditioning – it becomes useless when you open Windows.” (Linus Torvalds)
- A hozzászóláshoz be kell jelentkezni