Igaz hogy CISC felépítésű, de ez még akkor készült, amikor az emberek még kódoltak assemblyben, tehát nem ártott, ha használható is volt. :) Szinte mindenhol 16/32 bites architektúrának jellemzik, de ezt speciel én nem értem. Mitől függ, hogy egy CPU hány bites? Van ennek valami egzakt meghatározása? (Most csak azért se állok neki keresni...) SZERINTEM egy CPU annyi bitesnek tekinthető, amekkora adatokkal egy lépésben dolgozni tud → amilyen széles(ek) a munkaregisztere(i) → tulajdonképpen amilyen széles az ALU. Ha így nézem, az ős 68K is tisztán 32 bites. Időben mindezt a 70-es évek végén, amikor az intel (ők írják kisbetűvel... :) ) a 8086-ot faragta, amit városi legendák szerint azért terveztek olyanra amilyen, hogy a 8 bites CPU-kon nevelkedett programozóknak ne legyen idegen a felépítés. (Ergo a feladat: „csináljatok egy olyan 16 bites CPU-t, ami 8 bitesnek látszik”.) Hogy ez igaz-e, azt nem tudom, de más magyarázat nem létezik arra, hogy hogy lehet egy ilyen el....... ISA-t kitalálni.
No de vissza a 68K-ra! Amikor a kódot nekiálltam anno készíteni, még teljesen egyértelműnek tűnt, hogy a fejlesztést Amiga-n fogom csinálni, mivel abban a CPU szintén 68K, az esetleges debug könnyebb lehet. (Ugyan a komplett kódot az eltérő HW miatt nem fogom tudni tesztelni, de a részleteit igen!) A projekt assemblyben készült, a megfelelő assembler kiválasztása viszont némi fejtörést okozott, ugyanis a(z akkor általam ismert) fejlesztőeszközök eléggé Amiga specifikusak voltak. Leginkább direkt memóriába szerettek volna fordítani, nekem meg fix memóriaterületre kellett, így csak a „klasszikus” fordítók jöhettek számításba, amik fájlt olvasnak bemenetként, és fájlt írnak kimenetként. (Azok a tool-ok, amiket akkoriban használtak pl. demókódolásra, azok úgy működtek, hogy a forráskód editor össze volt építve a fordítóval, közvetlenül abból fordítódott a gépi kód egyből a memóriába, amit rögtön ki is lehetett próbálni. Ilyen pl. az Asm-Pro, vagy az ASM-One. Ez nekem nem volt járható út.) Akkor a választásom a PhxAss-ra esett, mivel a fontos kritériumoknak megfelelt.
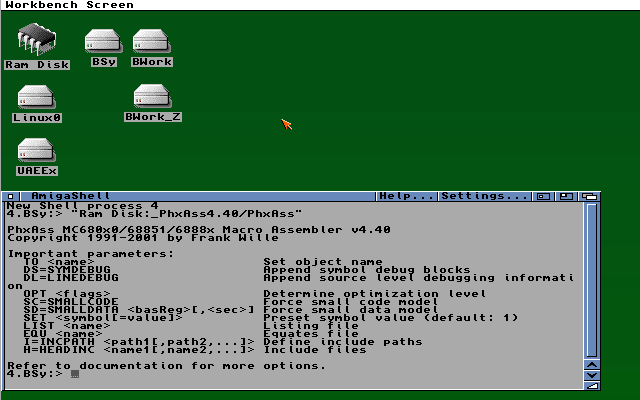
Nagyon tovább nem is keresgéltem, mivel akkor az a luxus, amit internetnek hívtak, az a legjobb esetben egy drága percdíjas ISDN vonalat jelentett (esetleg dupla percdíjért duplán... :) ), az „olcsójánosoknak” maradt a modem, de az 56K-s verzió már ott is fényűzésnek számított. Ez a cucc se „dróton”, hanem még (vagy már...) valami CD-n került hozzám.
Ezt a kombinációt használtam igen sokáig (Amiga, ill. a fejlesztéshez PhxAss), majd ahogy teltek-múltak az évek, kezdett a gép kevés lenni. Ahogy nőtt a kód, úgy lett egyre lassabb a fordítás. „Megjött” az internet, a levelezéssel én nagyon sokáig elvoltam az eredeti vason, de aztán lassan ott is kevés kezdett lenni az „öreg hölgy”, így a nettel kapcsolatos dolgok átkerültek pc-re. (RedHat 8, emlékszik még valaki? Valamerre még megvan az 5 CD-s install készlet. :) ) Ez is így ment sokáig (Fejlesztés → Amiga; többi → pc), de itt meg a gépcserélgetés volt nyűgös. Miután a pc elég combossá fejlődött, az Amiga oldal az E-UAE segítségével átköltözött pc-re. Sajnos az E-UAE sem fejlődik ahogy látom, napokon belül 6 (!) éves lesz az a verzió, amit most használok... (De iszonyúan megy az idő: nem is ezzel a verzióval kezdtem! Szóval ez a költözködős projekt se ma volt...) Ezzel egész eddig elvagyok, bár a „debug” (Legalábbis ahogy csinálom: Kérdéses kódrészlet kimásol, ASM-One-ba betölt, fordít, lépésenként debugol...) néha nem működik (az látszik, hogy közben az E-UAE hibákat dobál a konzolba, szerencsére nem száll el...), szóval nem teljes az öröm, de a kényelem kárpótol. Rossz leírni, de sajnos így van: az E-UAE-s emuláció még úgy is jóval gyorsabb, hogy az eredeti Amiga-ban is van egy jófajta turbó- + videokártya. Eljárt fölötte az idő, na.
A héten kb. másfél év kihagyás után újra elő kellett vennem az E-UAE-t a módosítások miatt, viszont igencsak meglátszik (rajtam... :) ) a kihagyott idő. Valahogy nem állnak kézre a régi billentyűkombinációk, mindenen gondolkoznom kell, hogy mit hogy kéne megcsinálni. (Nem a kódolás részen, az OS, az editor használata alatt!) Nem is gondoltam volna, hogy ennyire „ki lehet rázódni” a rutinból. Itt jött az a „hatalmas” ötlet, hogy meg kellene próbálni a fordítást Linux alatt megoldani (a debug úgyis minimális abban a formában, ahogy az E-UAE alatt használtam...). Editor itt is van sokféle, választhatom közülük a kedvencet, „csak” egy 68K-s assemblert kell keresnem.
A keresgélés valójában semeddig se tartott, ugyanis van nekem már egy assemblerem, a The macroassembler AS, amit röviden csak asl-nek hívok (a fordítás után ez lesz a neve az „eszköznek”). Ez egy jó nagy rakás architektúrát támogat, közöttük természetesen (...) a 68K-t is. Igaz, hogy jó régi, gyorsan rá is néztem a honlapra, hogy egyáltalán meg van-e még... És erre mit látok? Utolsó frissítés 2013-07-22. :) Ami természetesen elírás, az aktuális build 2013-03-22 dátumú, azaz MAI. (...volt akkor, amikor ez a történet játszódik.) Tehát még mindig faragják, ez azért jó hír.
Az emulátorból kimásoltam a projektemet, majd a legrövidebb önállóan fordulni tudó cuccot megpróbáltam lefordítani. Mint az várható volt, egy rakás hibába ütközött az asl. Első körben az IF-es részek nem tetszenek neki, más a feltételes fordítás szintaktikája, ezt most „kikommenteztem”. De továbbra se fordul... Olyan hibákat ír, hogy csak pislogok. Egyértelműen kommenteket próbál assemblálni, ráadásul olyan sorszámokban, amiknek a környékén van olyan megjegyzés, de az adott sorban semmi... Remek. Némi „debug” árán sikerült kideríteni a hibát: azok a sorok amik ilyet okoznak, egyszerűen túl hosszúak. Az asl „elég bután” csinálja a sorfeldolgozást (ezek szerint). Valahol a doksiban mintha meg is lenne említve (Most persze nem találom... Álmodtam? :) ), hogy a sorok maximális hossza 255 karakter lehet, nekem viszont vannak extra hosszú soraim néhol. Az értelmes részük (mármint a fordító számára értelmes) rövid, de van hozzá „monstre-hosszú” megjegyzés. A fordító valószínűleg úgy olvassa a sorokat, hogy egy sztringbe olvassa befele karakterenként. Akkor hagyja abba, ha elért egy „sorvége” karakterig VAGY beolvasott 255 (?) BYTE-ot. Ha az utóbbi feltétel teljesül, akkor ezt a sort még feldolgozza, de a következő beolvasása helyett ennek a sornak a folytatása olvasódik új sor gyanánt. Ami persze megjegyzés, azt meg nem csoda ha nem tudja értelmezni. Én viszont ragaszkodnék a hosszú soraimhoz (ne törje szét az utasítás-sorokat, úgy jobban átlátom, ha meg a magyarázat kell, szkrollozok), de ekkor eszembe jutott, hogy ez bizony GPLv2-es cucc, ott a forrás, hátha át lehetne a sorhosszt egyszerűen írni mondjuk 1024-re.
A terv kész: C-ben még úgyse tudok programozni (pedig tanulgatom), ez egy jó gyakorlás lehet. Ha nem megoldható egyszerűen, akkor annak a kiderítése is. Szóval rosszul nem fogok járni, ha belenézek abba a kódba. Hát... :)
Két fajta megoldás lehet. Az egyik: ha megvan a „sorbeolvasó” függvény, azt ki lehetne egészíteni egy olyan résszel, hogy ha nem „sorvége” karakter miatt állt le a beolvasás, akkor a sor többi részét azért olvassa be tárolás nélkül. Ez nem biztos hogy ilyen egyszerű, mert lehet hogy nincs külön „sorbeolvasó” függvény a kódban, hanem valami „gyári” C-s függvényt használ erre, azt meg használhat több helyen is. A másik megoldás, hogy valahogy a sorpuffer hosszát meg kellene emelni mondjuk 1024 BYTE-ra, az már nekem is elég... (Az ilyen „nagyon hosszú” soraim 4-500 BYTE környékén azért megállnak, az az 1K még mindig bőven túlméretezett.) Vajon melyik vitelezhető ki az én tudásommal?
A forrásokba belenézve egy-két dolgot rögtön megállapítottam. Például azt, hogy a módosítás-ötleteim közül MOST egyiket sem próbálom kivitelezni. :) Konkrétan nem találok el a forráskódon. De valami nagyon nem... Azt hiszem nem ebből fogok C-t tanulni. :( Az látszik, hogy aki(k) készíti(k), az(ok) tud(nak) programozni. De szépen kódolni... (Szerintem tökéletes példa ez a projekt a „csúnya forrás, használható végeredmény” kombinációra. Persze bőven van példa a „szép forrás, vacak végeredmény” verzióra is, úgyhogy tényleg nem vonható le következtetés a forráskód szépségéből a végeredmény minőségére.) Az identálás számomra erősen „érdekes” kategória. A projekt eredetileg Pascal-ban készült, később írták át C-re. A Pascal-os örökség erősen látszik... Ha másból nem is, ennyi BEGIN-END párost C-s forrásban még nem láttam. :) Abszolút minden tiszteletem az alkotó(k)é, de ez nekem most még magas.
De ha már forrás, meg forgatás, a múltkor kimaradt a csomagkészítés, pedig a rendszerre az rpm-mel pakolgatni tisztább, szárazabb érzés az ilyesmit. (És hipp-hopp el is érkeztünk eme rövid bevezető után a tárgyhoz.) Ha ennyit küzdöttem eddig az egésszel, legalább valami sikerélmény is legyen, „saját” csomagot eddig még úgysem sikerült csinálnom. A GCC-s kalandomkor ugyan készült .rpm, de azt az alien követte el. Ideje lenne most már valahogy sajátot is csinálni, meg az sem biztos hogy rosszat tenne, ha valamennyire érteném is, hogy mi történik. No de csak sorjában.
Először a csomagolandó cucc (jelen esetben az asl) forrását olyan állapotba kell hozni, hogy simán le lehessen fordítani. Ez a múltkori téma, de ez nem így működik az összes csomag esetén (sajnos... :) ). Mindegy, ezt most így, itt is meg kell csinálni.
A jelenlegi verzió az 1.42Bld88 (Természetesen ß verzió, a stable 1999-7-11, szóval nem túl friss...), így a következő lett a könyvtár, amibe kicsomagolódott: asl-1.42Bld88. A feladatok:
- Forráscsomag kitömörítése
Makefile.defmegszerkesztése (cél könyvtárak útvonalai, ill. a target platform beállításamakea fordításhozmake testaz ellenőrzéshezmake docsa dokumentáció generálásához, ez opcionális
A dokumentáció elkészítéséhez szükséges a tex2html csomag (ami húzza magával a komplett (la)tex-t), a korrektség jegyében ezt (röpke 163 mega...) felraktam.
Ha ezek mennek normálisan, akkor egy make clean után a könyvtárat vissza lehet csomagolni:
$ cd ..
$ tar -cvjf asl-1.42Bld88.tar.bz2 asl-1.42Bld88Majd jöhet az RPM generálása, amihez kelleni fog az rpm-build csomag, ami a megfelelő szkripteket tartalmazza.
Ehhez elő kell készíteni a megfelelő környezetet, hogy az rpmbuild működőképes legyen. Ez egyrészt egy könyvtárstruktúra, ez az rpmbuild „homokozó”:
$ cd ~
$ mkdir RPMsandbox
$ cd RPMsandbox
$ mkdir SPECS SOURCES BUILD RPMS SRPMSMajd az rpmbuild számára kell egy konfigurációs fájl, amiben „el van neki magyarázva”, hogy mit hol talál. Ez a fájl a „júzer hómjában” az .rpmmacros néven tanyázik, aminek a tartalma a következő:
%_topdir /home/work/RPMsandbox
%_builddir %{_topdir}/BUILD
%_rpmdir %{_topdir}/RPMS
%_sourcedir %{_topdir}/SOURCES
%_specdir %{_topdir}/SPECS
%_srcrpmdir %{_topdir}/SRPMS(Az első sor a fent létrehozott homokozó könyvtár közvetlen elérési útja (van egy jó work júzerem... :) ), a többi a benne létrehozott könyvtáraké értelemszerűen.) Ezután már működőképes lesz az rpmbuild.
A környezet kész, jöhet az érdemi munka. A becsomagolt forrást a megfelelő helyre kell másolni:
$ cd ahol/a/forrás/archív/van
$ cp asl-1.42Bld88.tar.bz2 ~/RPMsandbox/SOURCESEzután létre kell hozni a csomaghoz tartozó .spec fájlt. Na, eddig mindig itt akadtam el, ugyanis ez nem egy „szimpla” eset. De szerencsére van hozzá segítség:
$ cd ~/RPMsandbox/SPECS
$ rpmdev-newspec asl-assemblerEz a parancs létrehoz egy „vázat”, amit „csak” ki kell tölteni a megfelelő adatokkal.
A „Name” mező van egyedül kitöltve (Name: asl-assembler), amit rögtön ki is javítok asl-re. A Version: sorba bekerül a verziószám: 1.42Bld88. A Release: marad az ami. A többi „fejlécadat” értelemszerű, de a Source0: paraméter még fontos, oda az asl-1.42Bld88.tar.bz2 kerül, ez a forrásarchív neve, amiből az .rpm készül. (A név ill. verzióból, meg a Release adatból fog összeállni majd az elkészült csomag neve.)
A Buildrequires: meg a Requires: sorok most simán kitörölhetőek, ha kellene, az már a Level-2 lenne. :)
A %build szekció jön, mivel a csomag nem használ configure szkriptet, így a %configure sor törlendő. Mivel én akarok dokumentációt is generálni (elvégre ezért raktam föl vagy 163 megát...), így a %build szekció így néz ki:
%build
make %{?_smp_mflags}
make docsAz %install rész marad, de utána jöhet az ellenőrzés futtatása egy új szekcióban:
%check
make testA %clean is jó ahogy van, viszont a %files részben/után fel kell (majd) sorolni a csomagba kerülendő fájlokat. Erre most csak egy „buta” megoldást találtam ki, erről majd később, most marad az is változatlanul.
Vissza van még a %changelog szekció, ez most így néz ki:
%changelog
* Sat Mar 24 2013 balagesz
- Initial RPM releaseA „*”-os sor az időpont (a formátumra elég háklis) illetve az azt elkövető neve, a többi sor (a „-”-esek) a leírás. Ez a rész persze opcionális.
Ha a .spec fájl eddig kész, akkor el lehet kezdeni csomagot generálni. Maradva a SPECS könyvtárban, jöhet az rpmbuild:
$ rpmbuild -bb asl-assembler.specEz a parancs egy „binary only” csomagot fog elvileg kreálni (-bb kapcsoló), de ez egyelőre nem sikerül neki.
A csomagépítés alatt az rpmbuild kicsomagolja a SOURCES könyvtárban levő archívot a BULID könyvtárba (az archívban nem csak a forráskönyvtár tartalma van, hanem a forrást tartalmazó könyvtár, tehát a BUILD könyvtáron belül létrejön az asl-1.42Bld88 könyvtár, abban van a forráskód), majd itt elindítja a .spec fájl %build szekcióját, azaz a make-t meg a make docs-ot. Ha ez lefut hibátlanul, akkor jön az %install szekció.
Az rpmbuild dokumentációjában külön felhívják a figyelmet arra, hogy sose futtasd root jogokkal. Most az is kiderült hogy miért: az %install rész átadja a make install számára a célkönyvtárat, hogy hol hozza létre azt a struktúrát, amibe a fájlokat kell másolnia. (Ha ez a paraméter hiányzik, akkor a gyökérből kiinduló útvonalakra kerül a cucc, tehát a /usr/bin-be és társaiba.) A „mi kis” install szkriptünk viszont magasról tesz a DESTDIR paraméterre, úgyhogy most is a gyökérhez képesti útvonalakra szeretne települni, ami mezei „jüzerként” szerencsére nem megy. A „települési útvonalak” a Makefile.def-ben vannak definiálva, ahova egy kis kiegészítést érdemes tenni:
BINDIR = $(DESTDIR)/usr/bin
INCDIR = $(DESTDIR)/usr/include/asl
MANDIR = $(DESTDIR)/usr/share/man
LIBDIR = $(DESTDIR)/usr/lib/asl
DOCDIR = $(DESTDIR)/usr/share/doc/aslHa ez megvan (lehet újratömöríteni a forrást meg másolni a megfelelő helyre), akkor az rpmbuild kimenete már szebben fest:
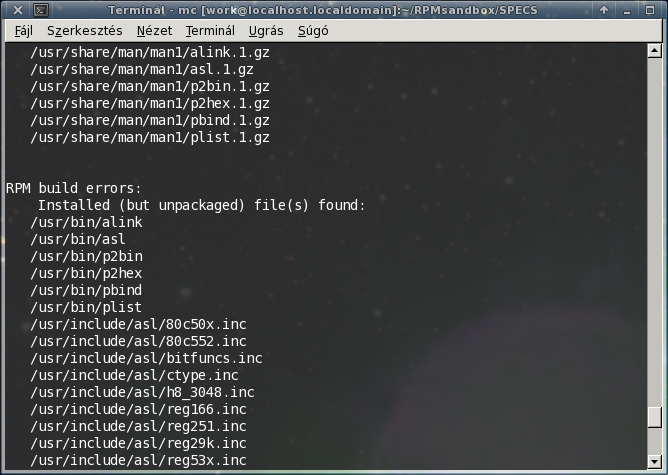
Végrehajtódik az %install szekció is, a BUILDROOT könyvtáron belül létrehozza a „csomagnév” nevű könyvtárat (itt asl-1.42Bld88-1.el6.x86_64, majd ide „installálja” a programunkat, azaz ide áll össze az a könyvtárstruktúra, ami a csomag telepítésekor majd felkerül a gépre. Az rpmbuild viszont talált „egy csomó” installált, de nem becsomagolt fájlt. Persze, mert a %files részben nincs felsorolva, hogy mi fog a csomagba kerülni. Erre egy igencsak favágó módszert használtam: a konzolból a hibalistát simán copy-paste módszerrel bemásoltam a .specs fájl %files szekciójába a %doc alá. A végeredmény:
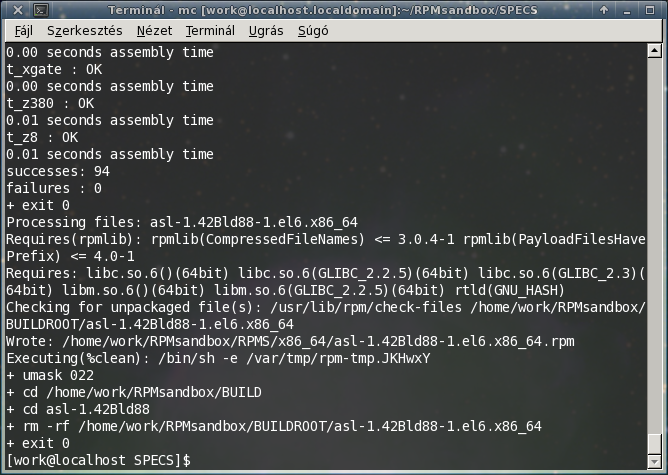
És igen! Elkészült a csomagom! A BUILDROOT könyvtár kiürült, az RPMS alatt meg létrejött az x86_64 könyvtár (csomag architektúrája), abban meg ott az eddigi munka gyümölcse, az asl-1.42Bld88-1.el6.x86_64.rpm nevű csomag. Juhéj! Nézzük meg, mi is van benne:
rpm2cpio asl-1.42Bld88-1.el6.x86_64.rpm | cpio -idmvEz rögtön ide ki is csomagolja a megfelelő könyvtárstruktúrában. Igen, benne van minden. Csak nem... Vajon fel is lehet rakni? Root-ként minden bizonnyal:
yum install asl-1.42Bld88-1.el6.x86_64.rpm
Nohát... Megy az installálás is, teljes a siker!
A csomagolásból azért még nem 100%-ig tiszta minden, ez a verzió arról szólt, amikor a csomaggenerálás maga csinálja a fordítást is. A GCC-s móka például nem tudom hogy működne így (ott maga a fordítás is túl macerás volt, nem hogy ráhagyjam az rpmbuild-ra...), a kész binárisból még nem tudom hogy tudnék csomagot gyártani. De legalább van merre elindulni... :)
Ha esetleg valami érdekelne a végeredmények közül:
- A saját
Makefile.defaz asl fordításához - Az elkészült
.specfájl a csomag újragenerálásához - Maga az asl forrás archív, ebben már a megfelelő
Makefile.defbenne van - Az elkészült asl csomag, x86_64 változatban, RHEL6/CentOS6/SL6/... rendszerekhez
Na de vajon fordul-e vele a 68K-s kódom?
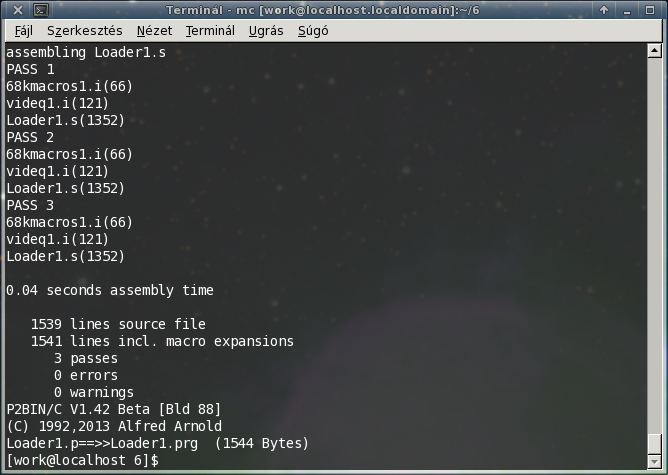
Fordul. Miután lerövidítettem azt a pár extra hosszú sort. Egyelőre a tesztelés ennyi, a végeredményt ki nem próbáltam, az E-UAE-ből való „kiköltözés” még odébb van, mindenesetre már van merre elindulni. Ez is valami...
Update:
Elkészült a 89-es „build”, amiben a szerző javított a hosszú soros problémámon. (Innen is köszönet neki!) A túl hosszú sorokból az első 255 karaktert dolgozza csak fel, a többit szépen átlépi. (Az első tesztekből ez látszik legalábbis...) Itt vannak az elkészült „dolgok”:
- A Bld89-es
.specfájl - A Bld89-es asl forrás archív, ebben is a megfelelő
Makefile.defvan - A Bld89-es asl csomag, x86_64 változatban, RHEL6/CentOS6/SL6/... rendszerekhez
Update2:
Röpke 2½ év után :) van új „build” részemről, mivel fejlesztik ezt a programot, még ha nem is roham léptekben. Persze én sem figyeltem közben a történteket, mivel az előző verzió is tette a dolgát, szerencsére. A mostani verzióban a „.de” dokumentációk nincsenek benne, ettől egy kicsit kisebb az elfoglalt hely. Illetve ez már CentOS7 alatt készült, szintén x86_64. Figyelem: továbbra is ß változat!
- A Bld106-os
.specfájl, „optimalizált” verzió az előzőekhez képest - A Bld106-os asl forrás archív
- A Bld106-os asl csomag, x86_64 változatban, RHEL7/CentOS7/SL7/... rendszerekhez
„Irodalom”:
balagesz
---
2013.03.24.
2013.08.10. Bld89
2013.10.24. Linkek módosítása
2016.01.03. Bld106, helyesírás javítása
2019.12.10. D8.
- balagesz blogja
- A hozzászóláshoz be kell jelentkezni
Hozzászólások
Jól látok? Releváns, szakmai bejegyzés? Biztos, hogy a HUP-on járok?
Mindenesetre, remek post!
--
"Maradt még 2 kB-om. Teszek bele egy TCP-IP stacket és egy bootlogót. "
- A hozzászóláshoz be kell jelentkezni
+1 thx
--
zsebHUP-ot használok!
- A hozzászóláshoz be kell jelentkezni
+1
-fs-
Az olyan tárgyakat, amik képesek az mc futtatására, munkaeszköznek nevezzük.
/usr/lib/libasound.so --gágágágá --lilaliba
- A hozzászóláshoz be kell jelentkezni
+1. köszi!
- A hozzászóláshoz be kell jelentkezni
Betyaros hosszu :) A tortenelmi reszt olvastam el, az tetszett.
http://karikasostor.hu - Az autentikus zajforrás.
- A hozzászóláshoz be kell jelentkezni
Nem olvasom végig, pedig jó. Csak reagálok: "Mitől függ, hogy egy CPU hány bites? ... folyt"
A munkaregiszterek nem számítanak. 8088 is 8 bites, mégis vannak 16 bites regiszterei, és nem tud címezni 1MB fölé (jó, egy picivel tud, de nem sokkal, mert ha a szegmens 0xFFFF, akkor 65520-szal túllépheti az 1M bűvös határát). De ettől még 8 bit.
Ergo, akkor lesz a kód 8, 16, 32, stb. bites, ha az adott bitspecifikációban szereplő CPU utasításkészletet használod - ez meg úgy hiszem a compileren múlik magasabb szintű nyelveken, asm esetén meg Rajtad.
--
PtY - www.onlinedemo.hu
- A hozzászóláshoz be kell jelentkezni
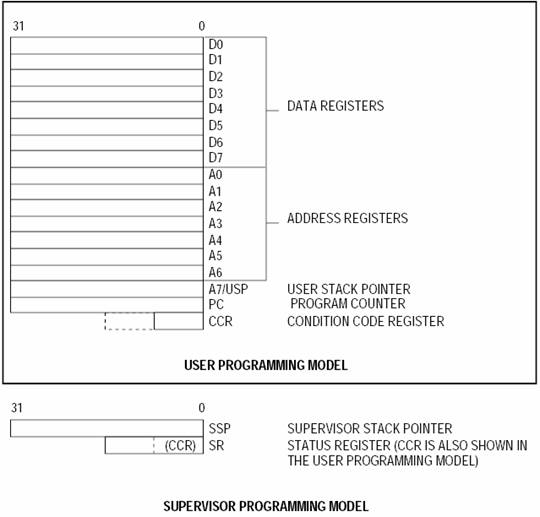
Az, hogy a "CPU hány bites", abba én nem keverném bele azt, hogy milyen kódot lehet rá írni. Mint ahogy a címek hosszát se... Ez tisztán hardveres kérdés. Egyszerűen meg kell nézni, hogy az adott processzornak hogy néz ki a "Programming Model"-je. (Van erre jó fordítás?) A 68K-ról most egy ilyet találtam, ez tiszta 32 bites felépítésnek látszik. (Persze szerintem.) De úgy tűnik itt is van több féle megközelítés, mindenki azt használja, ami neki szimpatikus! :-D (Pl. az említett 68000 belül 16 bites ALU-val van felépítve, a 32 bites műveleteket több lépésben hajtja végre. De a programozás szempontjából ez maximum annyiból látszik, hogy a 32 bites műveletek tovább tartanak.)
{kind=link}
- A hozzászóláshoz be kell jelentkezni
Tehát azt mondod, hogy azt kéne először is tisztázni, hogy milyen szempontból Xbites egy architektura?
--
PtY - www.onlinedemo.hu
- A hozzászóláshoz be kell jelentkezni
Valahogy úgy... Eddig azt "hittem", hogy ez egy egyszerű történet. De úgy tűnik manapság szokás a régi dolgokat újradefiniálni. :)
- A hozzászóláshoz be kell jelentkezni